


C# OCR Image to Text Tutorial: Convert Images to Text Without Tesseract
Deseja converter imagens em texto em C# sem a complicação de configurações complexas do Tesseract? Este tutorial completo de IronOCR em C# mostra como implementar um poderoso sistema de reconhecimento óptico de caracteres em suas aplicações .NET com apenas algumas linhas de código.
Início Rápido: Extrair Texto de uma Imagem em Uma Linha
Este exemplo mostra como é fácil entender o IronOCR— apenas uma linha de C# transforma sua imagem em texto. Este vídeo demonstra a inicialização do mecanismo OCR e a leitura e recuperação imediatas de texto sem configurações complexas.
-
Instale IronOCR com o Gerenciador de Pacotes NuGet
-
Copie e execute este trecho de código.
string text = new IronTesseract().Read("image.png").Text; -
Implante para testar em seu ambiente de produção.
Comece a usar IronOCR em seu projeto hoje com uma avaliação gratuita

Fluxo de trabalho mínimo (5 etapas)
- Baixe o IronOCR - a biblioteca OCR em C# para conversão de imagens em texto.
- Use a classe
IronTesseractpara ler texto de imagens instantaneamente. - Aplique filtros de imagem para melhorar a precisão do OCR em digitalizações de baixa qualidade.
- Processe vários idiomas com pacotes de idiomas para download.
- Exporte os resultados como PDFs pesquisáveis ou extraia sequências de texto.
Como faço para ler texto de imagens em aplicativos .NET ?
Para implementar a funcionalidade de OCR (reconhecimento óptico de caracteres) de imagem para texto em C# em suas aplicações .NET , você precisará de uma biblioteca de OCR confiável. IronOCR fornece uma solução gerenciada usando a classe IronOcr.IronTesseract que maximiza tanto a precisão quanto a velocidade sem exigir dependências externas.
Primeiro, instale o IronOCR em seu projeto do Visual Studio. Você pode baixar a DLL do IronOCR diretamente ou usar o Gerenciador de Pacotes NuGet .
Install-Package IronOcr
Por que escolher IronOCR para OCR em C# sem Tesseract?
Quando você precisa converter imagens em texto em C#, o IronOCR oferece vantagens significativas em relação às implementações tradicionais do Tesseract:
- Funciona imediatamente em ambientes .NET puros
- Não é necessária nenhuma instalação ou configuração do Tesseract
- Executa os motores mais recentes: Tesseract 5 (além de Tesseract 4 e 3)
- Compatível com .NET Framework 4.6.2+, .NET Standard 2+ e .NET Core 2, 3, 5, 6, 7, 8, 9 e 10
- Melhora a precisão e a velocidade em comparação com o Tesseract original.
- Suporta implantações em Xamarin, Mono, Azure e Docker.
- Gerencia dicionários Tesseract complexos por meio de pacotes NuGet.
- Processa PDFs, TIFFs MultiFrame e todos os principais formatos de imagem automaticamente.
- Corrige digitalizações de baixa qualidade e distorcidas para resultados ideais.
Como usar o tutorial C# do IronOCR para OCR básico?
Este exemplo em C# do Iron Tesseract demonstra a maneira mais simples de ler texto de uma imagem usando o IronOCR. A classe IronOcr.IronTesseract extrai texto e o retorna como uma string.
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-3.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageindices);
input.Deskew(); // removes rotation and perspective
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
Private pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.LowQuality.tiff", pageindices)
input.Deskew() ' removes rotation and perspective
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)Este código atinge 100% de precisão em imagens nítidas, extraindo o texto exatamente como ele aparece:
IronOCR Simple Example
In this simple example we test the accuracy of our C# OCR library to read text from a PNG Image. This is a very basic test, but things will get more complicated as the tutorial continues.
The quick brown fox jumps over the lazy dogA classe IronTesseract lida internamente com operações complexas de OCR. Ele realiza varreduras automáticas para alinhamento, otimiza a resolução e usa IA para ler o texto da imagem com precisão semelhante à humana, utilizando o IronOCR .
Apesar do processamento sofisticado que ocorre nos bastidores — incluindo análise de imagem, otimização do mecanismo e reconhecimento inteligente de texto — o processo de OCR acompanha a velocidade de leitura humana, mantendo níveis de precisão excepcionais.
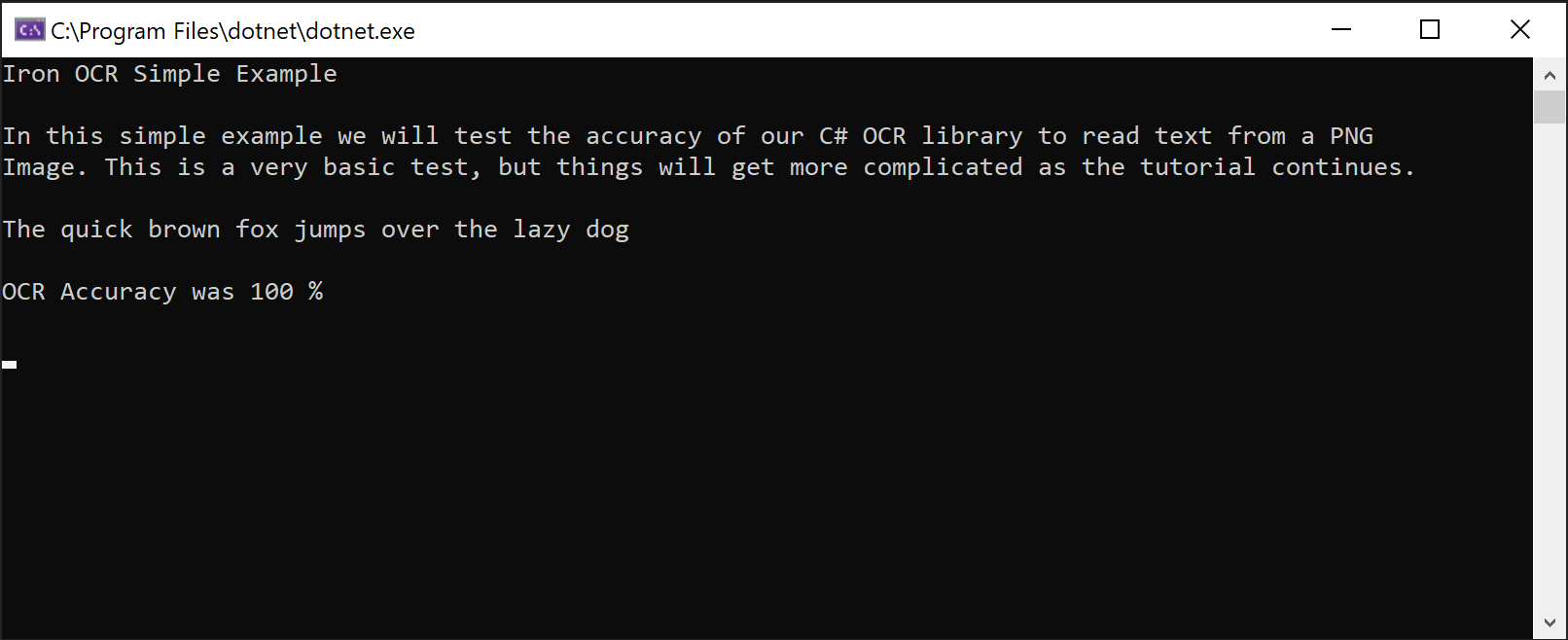 Captura de tela demonstrando a capacidade do IronOCR de extrair texto de uma imagem PNG com precisão perfeita.
Captura de tela demonstrando a capacidade do IronOCR de extrair texto de uma imagem PNG com precisão perfeita.
Como implementar OCR C# avançado sem configuração do Tesseract?
Para aplicativos de produção que exigem desempenho ideal ao converter imagens em texto em C#, use as classes OcrInput e IronTesseract juntas. Essa abordagem proporciona um controle preciso sobre o processo de OCR.
Recursos da Classe OcrInput
- Processa múltiplos formatos de imagem: JPEG, TIFF, GIF, BMP, PNG
- Importa PDFs completos ou páginas específicas
- Melhora automaticamente o contraste, a resolução e a qualidade da imagem.
- Corrige rotação, ruído de digitalização, distorção e imagens negativas.
Recursos da Classe IronTesseract
- Acesso a mais de 127 idiomas pré-configurados
- Inclui os motores Tesseract 5, 4 e 3
- Especificação do tipo de documento (captura de tela, trecho ou documento completo)
- Capacidades integradas de leitura de código de barras
- Múltiplos formatos de saída: PDFs pesquisáveis, HTML HOCR, objetos DOM e strings.
Como começar com OcrInput e IronTesseract?
Aqui está uma configuração recomendada para este tutorial de IronOCR em C# que funciona bem com a maioria dos tipos de documentos:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-5.csusing IronOcr;
using IronSoftware.Drawing;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
// restrict OCR to a content area for faster processing
Rectangle contentArea = new Rectangle(x: 215, y: 1250, height: 280, width: 1335);
input.LoadImage("img/ComSci.png", contentArea);
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Imports IronSoftware.Drawing
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' restrict OCR to a content area for faster processing
Dim contentArea As New Rectangle(x:=215, y:=1250, height:=280, width:=1335)
input.LoadImage("img/ComSci.png", contentArea)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End UsingEssa configuração alcança consistentemente uma precisão quase perfeita em digitalizações de qualidade média. O método LoadImageFrames lida eficientemente com documentos de várias páginas, sendo ideal para cenários de processamento em lote.

Exemplo de documento TIFF demonstrando as capacidades de extração de texto de várias páginas do IronOCR.
A capacidade de ler texto a partir de imagens e códigos de barras em documentos digitalizados, como TIFFs, demonstra como o IronOCR simplifica tarefas complexas de OCR. A biblioteca se destaca com documentos do mundo real, lidando perfeitamente com arquivos TIFF de várias páginas e extração de texto de PDFs .
Como o IronOCR lida com digitalizações de baixa qualidade?

Documento de baixa resolução com ruído que o IronOCR consegue processar com precisão usando filtros de imagem.
Ao trabalhar com digitalizações imperfeitas que contêm distorção e ruído digital, o IronOCR supera outras bibliotecas OCR em C# . Ele foi projetado especificamente para cenários do mundo real, em vez de imagens de teste perfeitas.
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-6.cs// PM> Install IronOcr.Languages.Arabic
using IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using OcrInput input = new OcrInput();
input.LoadImageFrame("img/arabic.gif", 1);
// add image filters if needed
// In this case, even thought input is very low quality
// IronTesseract can read what conventional Tesseract cannot.
OcrResult result = ocr.Read(input);
// Console can't print Arabic on Windows easily.
// Let's save to disk instead.
result.SaveAsTextFile("arabic.txt");' PM> Install IronOcr.Languages.Arabic
Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.Arabic
Using input As New OcrInput()
input.LoadImageFrame("img/arabic.gif", 1)
' add image filters if needed
' In this case, even thought input is very low quality
' IronTesseract can read what conventional Tesseract cannot.
Dim result As OcrResult = ocr.Read(input)
' Console can't print Arabic on Windows easily.
' Let's save to disk instead.
result.SaveAsTextFile("arabic.txt")
End UsingUsando Input.Deskew(), a precisão melhora para 99.8% em digitalizações de baixa qualidade, quase igualando os resultados de alta qualidade. Isso demonstra por que o IronOCR é a escolha preferida para OCR em C# sem as complicações do Tesseract.
Os filtros de imagem podem aumentar ligeiramente o tempo de processamento, mas reduzem significativamente a duração total do OCR. Encontrar o equilíbrio certo depende da qualidade do seu documento.
Para a maioria dos cenários, Input.Deskew() e Input.DeNoise() fornecem melhorias confiáveis no desempenho de OCR. Saiba mais sobre técnicas de pré-processamento de imagens .
Como otimizar o desempenho e a velocidade do OCR?
O fator mais significativo que afeta a velocidade do OCR ao converter imagens em texto em C# é a qualidade da entrada. Uma resolução DPI mais alta (em torno de 200 dpi) com ruído mínimo produz os resultados mais rápidos e precisos.
Embora o IronOCR seja excelente na correção de documentos imperfeitos, esse aprimoramento requer tempo de processamento adicional.
Escolha formatos de imagem com o mínimo de artefatos de compressão. Os formatos TIFF e PNG geralmente produzem resultados mais rápidos do que o JPEG devido ao menor ruído digital.
Quais filtros de imagem melhoram a velocidade do OCR?
Os seguintes filtros podem melhorar drasticamente o desempenho do seu fluxo de trabalho de OCR de imagem para texto em C#:
OcrInput.Rotate(double degrees): Rotaciona imagens no sentido horário (negativo para anti-horário)OcrInput.Binarize(): Converte para preto/branco, melhorando o desempenho em cenários de baixo contrasteOcrInput.ToGrayScale(): Converte para tons de cinza para possíveis melhorias de velocidadeOcrInput.Contrast(): Ajusta automaticamente o contraste para melhor precisãoOcrInput.DeNoise(): Remove artefatos digitais quando se espera ruídoOcrInput.Invert(): Inverte cores para texto branco-sobre-pretoOcrInput.Dilate(): Expande os limites do textoOcrInput.Erode(): Reduz os limites do textoOcrInput.Deskew(): Corrige o alinhamento - essencial para documentos enviesadosOcrInput.DeepCleanBackgroundNoise(): Remoção agressiva de ruídoOcrInput.EnhanceResolution: Melhora a qualidade da imagem de baixa resoluçãoOcrInput.DetectPageOrientation(): Detecta e corrige a rotação da página. Passe umOrientationDetectionModepara controlar o equilíbrio precisão/velocidade:Fast,Balanced,Detailed, ouExtremeDetailed(adicionado na v2025.8.6)
Scale() e EnhanceResolution() são incompatíveis com SaveAsSearchablePdf() devido a um problema conhecido na v2025.12.3. Todos os outros filtros funcionam corretamente com saída de PDF pesquisável.
Como configurar o IronOCR para obter a velocidade máxima?
Use estas configurações para otimizar a velocidade ao processar digitalizações de alta qualidade:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-7.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.ChineseSimplified;
// We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Optionally add custom tesseract .traineddata files by specifying a file path
using OcrInput input = new OcrInput();
input.LoadImage("img/MultiLanguage.jpeg");
OcrResult result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.ChineseSimplified
' We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English)
' Optionally add custom tesseract .traineddata files by specifying a file path
Using input As New OcrInput()
input.LoadImage("img/MultiLanguage.jpeg")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsTextFile("MultiLanguage.txt")
End UsingEssa configuração otimizada mantém 99,8% de precisão, ao mesmo tempo que alcança uma melhoria de velocidade de 35% em comparação com as configurações padrão.
Como ler áreas específicas de imagens usando OCR C#?
O exemplo Iron Tesseract C# abaixo mostra como direcionar regiões específicas usando System.Drawing.Rectangle. Essa técnica é inestimável para o processamento de formulários padronizados onde o texto aparece em locais previsíveis.
O IronOCR consegue processar regiões recortadas para obter resultados mais rápidos?
Ao usar coordenadas baseadas em pixels, você pode limitar o OCR a áreas específicas, melhorando drasticamente a velocidade e evitando a extração de texto indesejado:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-8.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", pageindices);
OcrResult result = ocr.Read(input);
Console.WriteLine($"{result.Pages.Length} Pages"); // 3 PagesImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("image3.gif", pageindices)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine($"{result.Pages.Length} Pages") ' 3 PagesEssa abordagem direcionada proporciona uma melhoria de velocidade de 41%, extraindo apenas o texto relevante. É ideal para documentos estruturados como faturas , cheques e formulários. A mesma técnica de recorte funciona perfeitamente com operações de OCR em PDF .
 Documento demonstrando extração precisa de texto baseada em regiões usando a seleção retangular do IronOCR.
Documento demonstrando extração precisa de texto baseada em regiões usando a seleção retangular do IronOCR.
Quantos idiomas o IronOCR suporta?
O IronOCR oferece 127 idiomas internacionais por meio de pacotes de idiomas convenientes. Faça o download deles como arquivos DLL em nosso site ou através do Gerenciador de Pacotes NuGet .
Instale os pacotes de idiomas através da interface NuGet ( pesquise "IronOCR" ) ou visite a lista completa de pacotes de idiomas .
Os idiomas suportados incluem árabe, chinês (simplificado/tradicional), japonês, coreano, hindi, russo, alemão, francês, espanhol e mais de 115 outros, cada um otimizado para reconhecimento preciso de texto.
Como implementar OCR em vários idiomas?
Este exemplo de tutorial em C# do IronOCR demonstra o reconhecimento de texto em árabe:
Install-Package IronOcr.Languages.Arabic

IronOCR extraindo com precisão texto árabe de uma imagem GIF.
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-10.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadPdf("example.pdf", Password: "password");
// We can also select specific PDF page numbers to OCR
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Length} Pages");
// 1 page for every page of the PDFImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadPdf("example.pdf", Password:= "password")
' We can also select specific PDF page numbers to OCR
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
Console.WriteLine($"{result.Pages.Length} Pages")
' 1 page for every page of the PDFO IronOCR consegue lidar com documentos em vários idiomas?
Quando os documentos contiverem idiomas mistos, configure o IronOCR para suporte a vários idiomas:
Install-Package IronOcr.Languages.ChineseSimplified
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-12.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Metadata Name";
input.LoadPdf("example.pdf", Password: "password");
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Metadata Name"
input.LoadPdf("example.pdf", Password:= "password")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")Como processar documentos de várias páginas com OCR C#?
IronOCR combina perfeitamente várias páginas ou imagens em um único OcrResult. Essa funcionalidade possibilita recursos avançados, como a criação de PDFs pesquisáveis e a extração de texto de conjuntos inteiros de documentos.
Combine e misture diversas fontes — imagens, quadros TIFF e páginas PDF — em uma única operação de OCR:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-13.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Title";
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Title"
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")Processar todas as páginas de um arquivo TIFF de forma eficiente:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-14.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Html Title";
// Add more content as required...
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf",Password: "password");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Html Title"
' Add more content as required...
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf",Password:= "password")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")Converter arquivos TIFF ou PDF para formatos pesquisáveis:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-15.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
input.LoadImage("img/Barcode.png");
OcrResult result = ocr.Read(input);
foreach (var barcode in result.Barcodes)
{
Console.WriteLine(barcode.Value);
// type and location properties also exposed
}Imports IronOcr
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
input.LoadImage("img/Barcode.png")
Dim result As OcrResult = ocr.Read(input)
For Each barcode In result.Barcodes
Console.WriteLine(barcode.Value)
' type and location properties also exposed
Next barcode
End UsingConverter PDFs existentes em versões pesquisáveis:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-16.csusing IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageindices);
OcrResult result = ocr.Read(input);
foreach (var page in result.Pages)
{
// Page object
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// null if we don't set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap(input);
System.Drawing.Bitmap pageImageLegacy = page.ToBitmap(input);
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int paragraphNumber = paragraph.ParagraphNumber;
String paragraphText = paragraph.Text;
System.Drawing.Bitmap paragraphImage = paragraph.ToBitmap(input);
int paragraphXLocation = paragraph.X;
int paragraphYLocation = paragraph.Y;
int paragraphWidth = paragraph.Width;
int paragraphHeight = paragraph.Height;
double paragraphOcrAccuracy = paragraph.Confidence;
var paragraphTextDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int lineNumber = line.LineNumber;
String lineText = line.Text;
AnyBitmap lineImage = line.ToBitmap(input);
System.Drawing.Bitmap lineImageLegacy = line.ToBitmap(input);
int lineXLocation = line.X;
int lineYLocation = line.Y;
int lineWidth = line.Width;
int lineHeight = line.Height;
double lineOcrAccuracy = line.Confidence;
double lineSkew = line.BaselineAngle;
double lineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int wordNumber = word.WordNumber;
String wordText = word.Text;
AnyBitmap wordImage = word.ToBitmap(input);
System.Drawing.Image wordImageLegacy = word.ToBitmap(input);
int wordXLocation = word.X;
int wordYLocation = word.Y;
int wordWidth = word.Width;
int wordHeight = word.Height;
double wordOcrAccuracy = word.Confidence;
if (word.Font != null)
{
// Word.Font is only set when using Tesseract Engine Modes rather than LTSM
String fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isFixedWidth = word.Font.IsFixedWidth;
bool isItalic = word.Font.IsItalic;
bool isSerif = word.Font.IsSerif;
bool isUnderlined = word.Font.IsUnderlined;
bool fontIsCaligraphic = word.Font.IsCaligraphic;
}
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int characterNumber = character.CharacterNumber;
String characterText = character.Text;
AnyBitmap characterImage = character.ToBitmap(input);
System.Drawing.Bitmap characterImageLegacy = character.ToBitmap(input);
int characterXLocation = character.X;
int characterYLocation = character.Y;
int characterWidth = character.Width;
int characterHeight = character.Height;
double characterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spell checking
OcrResult.Choice[] characterChoices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
For Each page In result.Pages
' Page object
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' null if we don't set Ocr.Configuration.ReadBarCodes = true;
Dim barcodes() As OcrResult.Barcode = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap(input)
Dim pageImageLegacy As System.Drawing.Bitmap = page.ToBitmap(input)
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphImage As System.Drawing.Bitmap = paragraph.ToBitmap(input)
Dim paragraphXLocation As Integer = paragraph.X
Dim paragraphYLocation As Integer = paragraph.Y
Dim paragraphWidth As Integer = paragraph.Width
Dim paragraphHeight As Integer = paragraph.Height
Dim paragraphOcrAccuracy As Double = paragraph.Confidence
Dim paragraphTextDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim lineNumber As Integer = line.LineNumber
Dim lineText As String = line.Text
Dim lineImage As AnyBitmap = line.ToBitmap(input)
Dim lineImageLegacy As System.Drawing.Bitmap = line.ToBitmap(input)
Dim lineXLocation As Integer = line.X
Dim lineYLocation As Integer = line.Y
Dim lineWidth As Integer = line.Width
Dim lineHeight As Integer = line.Height
Dim lineOcrAccuracy As Double = line.Confidence
Dim lineSkew As Double = line.BaselineAngle
Dim lineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim wordNumber As Integer = word.WordNumber
Dim wordText As String = word.Text
Dim wordImage As AnyBitmap = word.ToBitmap(input)
Dim wordImageLegacy As System.Drawing.Image = word.ToBitmap(input)
Dim wordXLocation As Integer = word.X
Dim wordYLocation As Integer = word.Y
Dim wordWidth As Integer = word.Width
Dim wordHeight As Integer = word.Height
Dim wordOcrAccuracy As Double = word.Confidence
If word.Font IsNot Nothing Then
' Word.Font is only set when using Tesseract Engine Modes rather than LTSM
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isFixedWidth As Boolean = word.Font.IsFixedWidth
Dim isItalic As Boolean = word.Font.IsItalic
Dim isSerif As Boolean = word.Font.IsSerif
Dim isUnderlined As Boolean = word.Font.IsUnderlined
Dim fontIsCaligraphic As Boolean = word.Font.IsCaligraphic
End If
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim characterNumber As Integer = character.CharacterNumber
Dim characterText As String = character.Text
Dim characterImage As AnyBitmap = character.ToBitmap(input)
Dim characterImageLegacy As System.Drawing.Bitmap = character.ToBitmap(input)
Dim characterXLocation As Integer = character.X
Dim characterYLocation As Integer = character.Y
Dim characterWidth As Integer = character.Width
Dim characterHeight As Integer = character.Height
Dim characterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spell checking
Dim characterChoices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next page
End UsingAplique a mesma técnica às conversões TIFF:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-17.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Configure document properties
input.Title = "Scanned Archive Document";
// Select pages to process
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Create searchable PDF from TIFF
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Configure document properties
input.Title = "Scanned Archive Document"
' Select pages to process
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Create searchable PDF from TIFF
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")
End UsingComo exportar resultados de OCR como HTML HOCR?
O IronOCR suporta a exportação HOCR para HTML, permitindo conversões estruturadas de PDF para HTML e de TIFF para HTML , preservando as informações de layout:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-18.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set HTML title
input.Title = "Document Archive";
// Process multiple document types
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf", "password");
// Add TIFF pages
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Export as HOCR with position data
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Set HTML title
input.Title = "Document Archive"
' Process multiple document types
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf", "password")
' Add TIFF pages
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Export as HOCR with position data
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")
End UsingO IronOCR consegue ler códigos de barras juntamente com texto?
O IronOCR combina de forma exclusiva o reconhecimento de texto com a leitura de códigos de barras , eliminando a necessidade de bibliotecas separadas:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-19.cs// Enable combined text and barcode recognition
using IronOcr;
var ocr = new IronTesseract();
// Enable barcode detection
ocr.Configuration.ReadBarCodes = true;
using (var input = new OcrInput())
{
// Load image containing both text and barcodes
input.LoadImage("img/Barcode.png");
// Process both text and barcodes
var result = ocr.Read(input);
// Extract barcode data
foreach (var barcode in result.Barcodes)
{
Console.WriteLine($"Barcode Value: {barcode.Value}");
Console.WriteLine($"Format: {barcode.Format}");
}
}
Imports IronOcr
Dim ocr As New IronTesseract()
' Enable barcode detection
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
' Load image containing both text and barcodes
input.LoadImage("img/Barcode.png")
' Process both text and barcodes
Dim result = ocr.Read(input)
' Extract barcode data
For Each barcode In result.Barcodes
Console.WriteLine($"Barcode Value: {barcode.Value}")
Console.WriteLine($"Format: {barcode.Format}")
Next
End UsingComo acessar resultados detalhados de OCR e metadados?
O objeto de resultados do IronOCR fornece dados abrangentes que desenvolvedores avançados podem aproveitar para aplicações sofisticadas.
Cada OcrResult contém coleções hierárquicas: páginas, parágrafos, linhas, palavras e caracteres. Todos os elementos incluem metadados detalhados, como localização, informações sobre a fonte e pontuações de confiança.
Elementos individuais (parágrafos, palavras, códigos de barras) podem ser exportados como imagens ou bitmaps para processamento posterior:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-20.csusing System;
using IronOcr;
using IronSoftware.Drawing;
// Configure with barcode support
IronTesseract ocr = new IronTesseract
{
Configuration = { ReadBarCodes = true }
};
using OcrInput input = new OcrInput();
// Process multi-page document
int[] pageIndices = { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
OcrResult result = ocr.Read(input);
// Navigate the complete results hierarchy
foreach (var page in result.Pages)
{
// Page-level data
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// Extract page elements
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap();
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Paragraph properties
int paragraphNumber = paragraph.ParagraphNumber;
string paragraphText = paragraph.Text;
double paragraphConfidence = paragraph.Confidence;
var textDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Line details including baseline information
string lineText = line.Text;
double lineConfidence = line.Confidence;
double baselineAngle = line.BaselineAngle;
double baselineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Word-level data
string wordText = word.Text;
double wordConfidence = word.Confidence;
// Font information (when available)
if (word.Font != null)
{
string fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isItalic = word.Font.IsItalic;
}
foreach (var character in word.Characters)
{
// Character-level analysis
string charText = character.Text;
double charConfidence = character.Confidence;
// Alternative character choices for spell-checking
OcrResult.Choice[] alternatives = character.Choices;
}
}
}
}
}
Imports System
Imports IronOcr
Imports IronSoftware.Drawing
' Configure with barcode support
Dim ocr As New IronTesseract With {
.Configuration = New TesseractConfiguration With {
.ReadBarCodes = True
}
}
Using input As New OcrInput()
' Process multi-page document
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("img\Potter.tiff", pageIndices)
Dim result As OcrResult = ocr.Read(input)
' Navigate the complete results hierarchy
For Each page In result.Pages
' Page-level data
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' Extract page elements
Dim barcodes As OcrResult.Barcode() = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap()
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Paragraph properties
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphConfidence As Double = paragraph.Confidence
Dim textDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Line details including baseline information
Dim lineText As String = line.Text
Dim lineConfidence As Double = line.Confidence
Dim baselineAngle As Double = line.BaselineAngle
Dim baselineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Word-level data
Dim wordText As String = word.Text
Dim wordConfidence As Double = word.Confidence
' Font information (when available)
If word.Font IsNot Nothing Then
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isItalic As Boolean = word.Font.IsItalic
End If
For Each character In word.Characters
' Character-level analysis
Dim charText As String = character.Text
Dim charConfidence As Double = character.Confidence
' Alternative character choices for spell-checking
Dim alternatives As OcrResult.Choice() = character.Choices
Next
Next
Next
Next
Next
End UsingResumo
O IronOCR oferece aos desenvolvedores C# a implementação mais avançada da API Tesseract , funcionando perfeitamente em plataformas Windows, Linux e Mac. Sua capacidade de ler com precisão o texto de uma imagem usando o IronOCR - mesmo em documentos imperfeitos - o diferencia das soluções básicas de OCR.
Os recursos exclusivos da biblioteca incluem leitura integrada de código de barras e a capacidade de exportar resultados como PDFs pesquisáveis ou HTML HOCR, funcionalidades indisponíveis nas implementações padrão do Tesseract.
Seguindo em frente
Para continuar a dominar o IronOCR:
- Explore nosso guia completo de primeiros passos.
- Veja exemplos práticos de código C#
- Consulte a documentação detalhada da API.
Download do código-fonte
Pronto para implementar a conversão de imagens em texto por OCR em C# em seus aplicativos? Baixe o IronOCR e comece seu teste gratuito hoje mesmo.
Perguntas frequentes
Como posso converter imagens em texto em C# sem usar o Tesseract?
Você pode usar o IronOCR para converter imagens em texto em C# sem precisar do Tesseract. O IronOCR simplifica o processo com métodos integrados que lidam diretamente com a conversão de imagem em texto.
Como posso melhorar a precisão do OCR em imagens de baixa qualidade?
O IronOCR oferece filtros de imagem como Input.Deskew() e Input.DeNoise() que podem ser usados para melhorar imagens de baixa qualidade, corrigindo a distorção e reduzindo o ruído, melhorando assim significativamente a precisão do OCR.
Quais são os passos para extrair texto de um documento com várias páginas usando OCR em C#?
Para extrair texto de documentos com várias páginas, o IronOCR permite carregar e processar cada página usando métodos como LoadPdf() para PDFs ou manipulando arquivos TIFF, convertendo efetivamente cada página em texto.
É possível ler simultaneamente códigos de barras e texto em uma imagem?
Sim, o IronOCR consegue ler tanto texto quanto códigos de barras em uma única imagem. Você pode habilitar a leitura de códigos de barras com ocr.Configuration.ReadBarCodes = true , o que permite a extração de dados de texto e de código de barras.
Como posso configurar o OCR para processar documentos em vários idiomas?
O IronOCR suporta mais de 125 idiomas e permite que você defina um idioma principal usando ocr.Language e adicione idiomas adicionais com ocr.AddSecondaryLanguage() para processamento de documentos multilíngues.
Quais métodos estão disponíveis para exportar resultados de OCR em diferentes formatos?
O IronOCR oferece vários métodos para exportar resultados de OCR, como SaveAsSearchablePdf() para PDFs, SaveAsTextFile() para texto simples e SaveAsHocrFile() para formato HTML HOCR.
Como posso otimizar a velocidade de processamento OCR para arquivos de imagem grandes?
Para otimizar a velocidade de processamento do OCR, use OcrLanguage.EnglishFast do IronOCR para um reconhecimento de idioma mais rápido e defina regiões específicas para OCR usando System.Drawing.Rectangle para reduzir o tempo de processamento.
Como faço para processar arquivos PDF protegidos por OCR?
Ao lidar com PDFs protegidos, utilize o método LoadPdf() juntamente com a senha correta. O IronOCR processa PDFs baseados em imagens convertendo automaticamente as páginas em imagens para o processamento de OCR.
O que devo fazer se os resultados do OCR não forem precisos?
Se os resultados do OCR forem imprecisos, considere usar os recursos de aprimoramento de imagem do IronOCR, como Input.Deskew() e Input.DeNoise() , e certifique-se de que os pacotes de idiomas corretos estejam instalados.
Posso personalizar o processo de OCR para excluir determinados caracteres?
Sim, o IronOCR permite a personalização do processo de OCR usando a propriedade BlackListCharacters para excluir caracteres específicos, melhorando a precisão e a velocidade de processamento ao focar apenas no texto relevante.



Ainda está rolando a tela?
Quer provas rápidas? PM > Install-Package IronOcr
executar um exemplo Veja sua imagem se transformar em texto pesquisável.










