

使用 C# 光學字符識別從圖像中讀取文本

在這個教程中,我們將學習如何在C#和其他.NET語言中將圖像轉換為文本。
如何在 C# 中將圖片轉換為文本
- 下載 OCR 圖像到文本的 IronOCR 函式庫
- 調整裁剪區域以讀取圖像的部分內容
- 使用語言包支持多達 125 種國際語言
- 匯出 OCR 掃描結果為文字或可搜尋的 PDF
在 .NET 應用程式中從圖像讀取文字
我們將使用 IronOcr.IronTesseract 類別來識別圖像中的文字,並研究如何使用 Iron Tesseract OCR 在從 .NET 中的圖像讀取文字時獲得最高的準確性和速度性能的細微差別。
要實現“圖像到文本”,我們將在 Visual Studio 項目中安裝 IronOCR 庫。
為此,我們下載 IronOcr DLL 或使用 NuGet。
Install-Package IronOcr
為什麼選擇IronOCR?
我們使用 IronOCR 進行 Tesseract 管理,因為它的獨特之處在於:
- 在純 .NET 環境中即可直接使用
- 不需要在您的機器上安裝 Tesseract。
- 運行最新引擎:Tesseract 5(以及 Tesseract 4 和 3)
- 可用于任何 .NET 项目:.NET Framework 4.5 及以上,.NET Standard 2 及以上,以及 .NET Core 2、3 和 5!
- 提高了比傳統 Tesseract 更高的準確性和速度。
- 支援 Xamarin、Mono、Azure 和 Docker
- 使用 NuGet 套件管理複雜的 Tesseract 字典系統。
- 支持 PDF、多幀 Tiff 和所有主要圖像格式,無需配置
-
可以糾正低質量和傾斜的掃描,以從 tesseract 獲得最佳結果。
立即在您的專案中使用IronOCR,並享受免費試用。
使用 Tesseract 在 C#
在這個簡單的範例中,您可以看到我們使用 IronOcr.IronTesseract 類別來從圖像中讀取文字,並自動以字串的形式返回其值。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-1.cs// PM> Install-Package IronOcr
using IronOcr;
OcrResult result = new IronTesseract().Read(@"img\Screenshot.png");
Console.WriteLine(result.Text);' PM> Install-Package IronOcr
Imports IronOcr
Private result As OcrResult = (New IronTesseract()).Read("img\Screenshot.png")
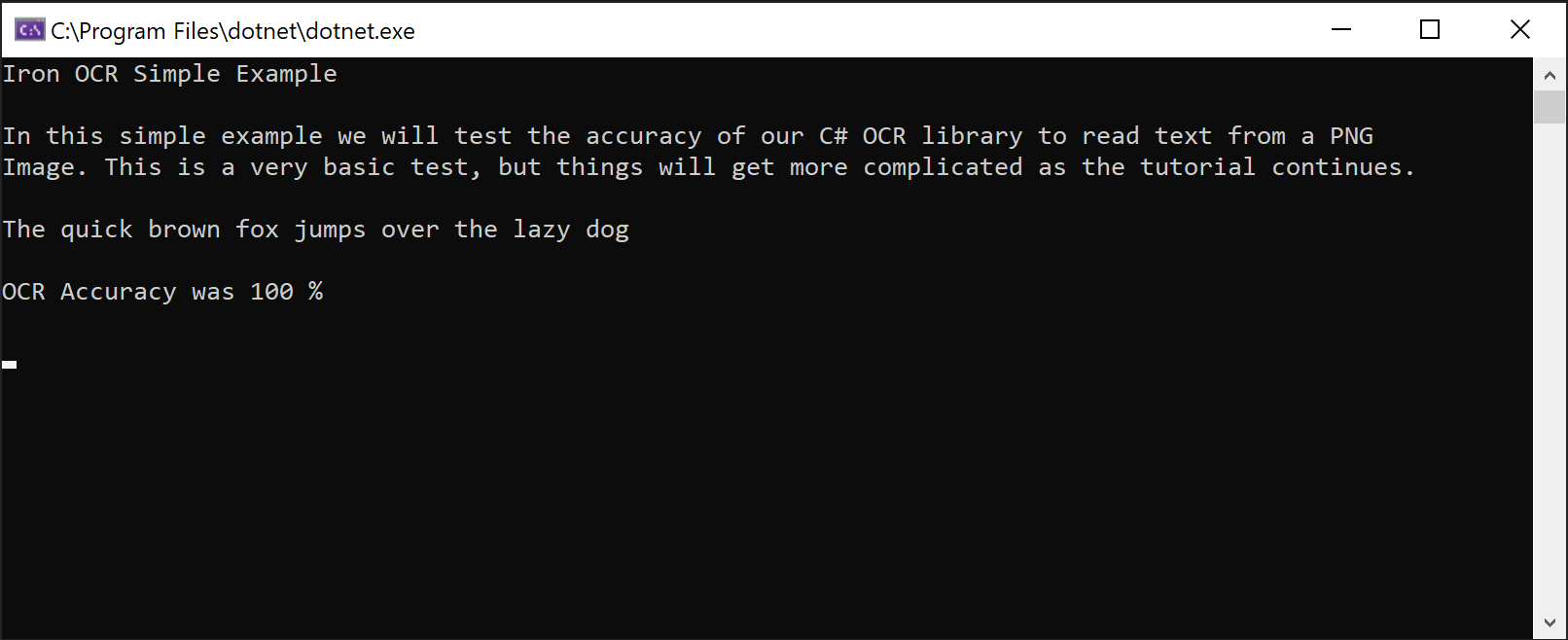
Console.WriteLine(result.Text)導致以下文本的準確率達到100%:
IronOCR Simple Example
In this simple example we will test the accuracy of our C# OCR library to read text from a PNG
Image. This is a very basic test, but things will get more complicated as the tutorial continues.
The quick brown fox jumps over the lazy dog雖然這看似簡單,但在"表面下"實際上進行著複雜的行為:掃描圖像的對齊、質量和解析度,檢查其屬性,優化OCR引擎,並使用訓練過的人工智能網絡以人類的方式閱讀文本。
OCR 對於電腦來說不是一個簡單的過程,其閱讀速度可能與人類相似。 換句話說,OCR不是一個即時的過程。 在這種情況下,它是100%準確的。
進階使用 IronOCR Tesseract for C
在大多數實際應用情況下,開發者都會希望他們的項目能有最佳的性能表現。 在這種情況下,我們建議您繼續使用IronOcr命名空間內的OcrInput和IronTesseract類別。
OcrInput 讓您設定OCR任務的特定特性,例如:
- 處理幾乎所有類型的圖片,包括JPEG、TIFF、GIF、BMP和PNG
- 導入整個或部分PDF文件
- 提高對比度、解析度和尺寸
-
校正旋轉、掃描噪聲、數字噪聲、傾斜、負像
IronTesseract
- 從數百種預先封裝的語言和語言變體中選擇
- 使用 Tesseract 5、4 或 3 OCR 引擎「開箱即用」
- 指定文檔類型,無論我們是在查看截圖、片段還是整個文檔。
- 讀取條碼
- 輸出結果至:可搜尋的PDF、Hocr HTML、DOM和字符串。
範例:開始使用 OcrInput + IronTesseract
這一切可能看起來令人生畏,但在下面的示例中,您將看到我們建議您從中開始的默認設置,這些設置幾乎適用於您輸入到IronOCR的任何圖像。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-2.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageindices);
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
Private pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)即使在中等質量的掃描上,我們也可以使用這個工具以100%的準確率。

正如您所見,從掃描圖像(例如TIFF)中讀取文本(以及可選的條碼)相當容易。
這項 OCR 工作的準確率為100%。
OCR 在處理真實世界文件時並不是一門完美的科學,但 IronTesseract 已經是目前最接近完美的產品。
您還將注意到,IronOCR 能夠自動讀取多頁文件,例如 TIFF,甚至可以自動從 PDF 文件中提取文本。
範例:低品質掃描

現在我們將嘗試以較低的DPI掃描同一頁面,這將導致大量的失真、數碼噪音以及對原紙張的損害。
這就是 IronOCR 真正優於其他 OCR 庫(如 Tesseract)的地方,而我們會發現其他替代的 OCR 專案往往避而不談。 在現實世界掃描的圖像上進行光學字符識別,而不是在數字化創建的不切實際的「完美」測試案例上,以實現100%的光學字符識別準確率。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-3.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageindices);
input.Deskew(); // removes rotation and perspective
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
Private pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.LowQuality.tiff", pageindices)
input.Deskew() ' removes rotation and perspective
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)如果不添加Input.Deskew()來校正影像,我們的準確率只有52.5%。 不夠好。
添加Input.Deskew()使我們達到99.8%的準確率,這幾乎與高質量掃描的光學字符識別一樣準確。
圖像過濾器可能需要一點時間運行 - 但也減少了OCR處理時間。對於開發者來說,了解其輸入文件是一種微妙的平衡。
如果您不確定:
Input.Deskew()是一個安全且非常有效的過濾器。- 其次,嘗試使用
Input.DeNoise()來修復大量的數位噪聲。
性能調校
OCR 任務速度中最重要的因素實際上是輸入影像的品質。 背景噪音越少且dpi越高,最理想的目標dpi約為200 dpi,將導致最快且最準確的OCR結果。
不過,這並不是必要的,因為IronOCR在校正不完美文件方面表現出色(雖然這很耗時並且會使您的OCR任務使用更多的CPU週期)。
如果可能,選擇數位噪聲較少的輸入影像格式,如TIFF或PNG,所獲得的結果會比使用有損影像格式如JPEG更快。
圖像過濾器
以下圖像過濾器可以顯著提升性能:
- OcrInput.Rotate(double degrees) - 將圖像順時針旋轉指定的角度數。若要逆時針旋轉,請使用負數。
- OcrInput.Binarize() - 此圖像濾鏡將每個像素轉為黑色或白色,沒有中間色調。 可改善文字與背景對比非常低的情況下的OCR性能。
- OcrInput.ToGrayScale() - 此影像濾鏡將每個像素變成灰階色調。 不太可能提高OCR精度,但可能提高速度。
- OcrInput.Contrast() - 自動增加對比度。 此過濾器通常可以提高低對比度掃描中的OCR速度和準確性。
- OcrInput.DeNoise() - 去除數位噪聲。此濾波器僅應用於預期有噪聲的情況。
- OcrInput.Invert() - 反轉每一個顏色。 例如:白變成黑:黑變成白。
- OcrInput.Dilate() - 高級形態學。 擴張會在影像中的物體邊界增加像素。 侵蝕的對立面
- OcrInput.Erode() - 進階形態學。 侵蝕 移除物體邊界上的像素,與膨脹相反。
- OcrInput.Deskew() - 旋轉影像使其正確朝上並呈正交。 這對於光學字符識別非常有用,因為Tesseract對斜掃描的容忍度可以低至5度。
- OcrInput.DeepCleanBackgroundNoise() - 強效背景噪聲去除。 僅在已知文件背景噪音極端的情況下使用此過濾器,因為這種過濾器也可能降低清晰文件的OCR準確性,且非常耗費CPU資源。
- OcrInput.EnhanceResolution - 增強低質量圖像的解析度。 此篩選器通常不是必須的,因為_OcrInput.MinimumDPI_和_OcrInput.TargetDPI_會自動捕捉並解決低解析度的輸入。
效能調校以提升速度
使用 Iron Tesseract,我們可能希望加快對高質量掃描的 OCR 處理速度。
如果要優化速度,我們可能會從這個位置開始,然後逐步開啟功能,直到找到完美的平衡點。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-4.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
// Configure for speed
ocr.Configuration.BlackListCharacters = "~`$#^*_}{][|\\";
ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
ocr.Language = OcrLanguage.EnglishFast;
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageindices);
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Private ocr As New IronTesseract()
' Configure for speed
ocr.Configuration.BlackListCharacters = "~`$#^*_}{][|\"
ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
ocr.Language = OcrLanguage.EnglishFast
Using input As New OcrInput()
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End Using這個結果的準確率是99.8%,相比基線的100%,但速度快35%。
讀取圖像的裁剪區域
您可以從以下代碼示例中看到,Iron對Tesseract OCR的分支很擅長讀取圖像的特定區域。
我們可以使用System.Drawing.Rectangle以像素為單位指定要讀取的圖像的確切區域。
這在我們處理填寫的標準化表格時非常有用,其中只有某個區域的文字會根據不同情況而改變。
示例:掃描頁面的一個區域
我們可以使用 System.Drawing.Rectangle 來指定我們將在其中讀取文件的區域。 度量單位一律是像素。
我們將會發現這樣不僅可以提升速度,也避免讀取不必要的文字。 在此範例中,我們將從標準化文件的中央區域讀取學生的名字。


:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-5.csusing IronOcr;
using IronSoftware.Drawing;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
// a 41% improvement on speed
Rectangle contentArea = new Rectangle(x: 215, y: 1250, height: 280, width: 1335);
input.LoadImage("img/ComSci.png", contentArea);
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Imports IronSoftware.Drawing
Private ocr As New IronTesseract()
Private OcrInput As using
' a 41% improvement on speed
Private contentArea As New Rectangle(x:= 215, y:= 1250, height:= 280, width:= 1335)
input.LoadImage("img/ComSci.png", contentArea)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)這帶來了41%的速度提升 - 並允許我們做到具體化。 這對於文件相似且一致的 .NET OCR 情境非常有用,例如發票、收據、支票、表格、報銷單等。
在讀取PDF時,也支持ContentAreas(OCR裁剪)。
國際語言
IronOCR 支援 125 種國際語言,透過語言包以 DLL 的形式分發,可以從本網站下載,也可以從 Visual Studio 的 NuGet 套件管理器下載。
我們可以通過瀏覽NuGet(搜尋 "IronOcr.Languages")或從OCR語言包頁面來安裝它們。
支持的語言包括:
- 南非語
- 阿姆哈拉語 亦稱為 አማርኛ
- 阿拉伯語 又稱為 العربية
- ArabicAlphabet 也被稱為 العربية
- ArmenianAlphabet Also known as Հայերեն
- 阿薩姆語 Also known as অসমীয়া
- 阿塞拜疆語 又稱為 azərbaycan dili
- AzerbaijaniCyrillic Also known as azərbaycan dili
- 白俄羅斯語 Also known as беларуская мова
- 孟加拉語 亦稱為Bangla,বাংলা
- 孟加拉字母又稱為孟加拉語,বাংলা
- Tibetan Also known as Tibetan Standard, Tibetan, Central ཡིག་
- 波斯尼亞語 又稱為bosanski jezik
- 布列塔尼語(也稱為brezhoneg)
- Bulgarian Also known as български език
- 加拿大原住民字母 也被稱為加拿大第一民族、加拿大原住民、加拿大土著、因紐特人
- 加泰羅尼亞語 又稱為 català、valencià
- 宿霧語 又稱為Bisaya、Binisaya
- 捷克語(亦稱作čeština, český jazyk)
- CherokeeAlphabet 也被稱為 ᏣᎳᎩ ᎦᏬᏂᎯᏍᏗ,Tsalagi Gawonihisdi
- 中國簡體 也被稱為中文(Zhōngwén),汉语,漢語
- ChineseSimplifiedVertical 也被稱為中文(Zhōngwén),汉语,漢語
- 中文繁體 也稱為 中文 (Zhōngwén), 汉语, 漢語
- 中文傳統直排 也稱為 中文 (Zhōngwén), 汉语, 漢語
- Cherokee 也被稱為 ᏣᎳᎩ ᎦᏬᏂᎯᏍᏗ, Tsalagi Gawonihisdi
- 科西嘉語 又稱 corsu,lingua corsa
- 威爾士語(又稱為Cymraeg)
- 西里爾字母 也被稱為西里爾文
- 丹麥文 又稱為 dansk
- 丹麥Fraktur(亦稱為dansk)
- 德文 又稱為 Deutsch
- 德國Fraktur 也稱為Deutsch
- DevanagariAlphabet 也稱為Nagair,देवनागरी
- Divehi 也被稱為 ދިވެހި
- Dzongkha 也被稱為 རྫོང་ཁ
- 希臘語 Also known as ελληνικά
- 英語
- 中古英文(亦稱為英語,1100-1500 AD)
- 世界語
- 愛沙尼亞語 又稱為 eesti, eesti keel
- 埃塞俄比亞字母 也被稱為吉茲,ግዕዝ,Gəʿəz
- 巴斯克語 也稱為euskara、euskera
- 法羅語 也稱為 føroyskt
- 波斯語(又稱為فارسی)
- 菲律賓語 又稱為菲律賓的國家語言,標準化的他加祿語
- 芬蘭語 又稱為suomi、suomen kieli
- 財務 又稱為財務、數字和技術文件
- 法文 又稱為法語、法蘭西語
- FrakturAlphabet 也被稱為通用Fraktur,拉丁字母的書法手寫體
- Frankish(也稱為Frenkisk、Old Franconian)
- 中古法語_也稱為Moyen Français,中古法語(約。 1400-1600 公元
- 西弗里西亞語 又稱為 Frysk
- 格魯吉亞字母 也稱為 ქართული
- 蘇格蘭蓋爾語 又稱為 Gàidhlig
- 愛爾蘭語(又稱為Gaeilge)
- 加利西亞語 也稱為 galego
- 古希臘文 又稱為 Ἑλληνική
- 希臘字母 Also known as ελληνικά
- 古吉拉特語 也被稱為 ગુજરાતી
- GujaratiAlphabet 也被稱為 ગુજરાતી
- GurmukhiAlphabet 也被稱為 Gurmukhī, ਗੁਰਮੁਖੀ, Shahmukhi, گُرمُکھی, Sihk Script
- HangulAlphabet(又稱為韓國字母,한글,Hangeul,조선글,hosŏn'gŭl)
- HangulVerticalAlphabet 也稱為韓國字母,한글,Hangeul,조선글,hosŏn'gŭl
- 韓文簡化字集 又稱三韓,韓語,韓語
- 漢簡化垂直字母 也稱為三韓,한어,韓語
- 漢傳統字母 又稱作Samhan,한어,韓語
- HanTraditionalVerticalAlphabet 也被稱為Samhan,한어,韓語
- 海地克里奥尔语,亦称为海地語
- 希伯來語 又稱為 עברית
- HebrewAlphabet Also known as 希伯來語
- Hindi Also known as हिन्दी, हिंदी
- 克羅地亞語(又稱為 hrvatski jezik)
- 匈牙利語(也被稱為馬扎爾語)
- 亞美尼亞語 又稱為 Հայերեն
- Inuktitut 又稱 ᐃᓄᒃᑎᑐᑦ
- 印尼語 也被稱為巴哈薩印尼
- 冰島語 又稱為Íslenska
- 義大利文 又稱為 italiano
- ItalianOld(又稱為italiano)
- JapaneseAlphabet 也稱為 日本語 (にほんご)
- JapaneseVerticalAlphabet亦稱為日本語(にほんご)
- 爪哇語(又稱為basa Jawa)
- 日語也稱為日本語 (にほんご)
- JapaneseVertical 也稱為 日本語 (にほんご)
- Kannada 也稱為 ಕನ್ನಡ
- KannadaAlphabet Also known as ಕನ್ನಡ
- 格魯吉亞語(亦稱為ქართული)
- GeorgianOld 也稱為 ქართული
- 哈薩克語 又稱為қазақ тілі
- Khmer 也被稱為 ខ្មែរ, ខេមរភាសា, ភាសាខ្មែរ
- KhmerAlphabet 也被稱為 ខ្មែរ, ខេមរភាសា, ភាសាខ្មែរ
- 吉爾吉斯,又稱Кыргызча、Кыргыз тили
- NorthernKurdish 也被稱為 Kurmanji,کورمانجی,Kurmancî
- 韓語亦稱為 한국어 (韓國語), 조선어 (朝鮮語)
- KoreanVertical 也稱為 한국어 (韓國語), 조선어 (朝鮮語)
- Lao Also known as ພາສາລາວ
- LaoAlphabet 也被稱為ພາສາລາວ
- 拉丁文 又稱為拉丁語, 拉丁語言
- 拉丁字母 也稱為拉丁文,拉丁語
- 拉脫維亞語 又稱為 latviešu valoda
- 立陶宛語 又稱為 lietuvių kalba
- 盧森堡語又稱為Lëtzebuergesch
- Malayalam 也被稱為 മലയാളം
- 馬拉雅拉姆字母 亦稱為 മലയാളം
- Marathi 也被稱為 मराठी
- MICR(又稱磁性墨水字符識別,MICR支票編碼)
- 馬其頓語 也被稱為 македонски јазик
- 馬爾他語 又稱為 Malti
- 蒙古語 也稱為 монгол
- 毛利語 亦稱為te reo Māori
- 馬來語(也稱為巴哈薩馬來語,بهاس ملايو)
- Myanmar 也被稱為 Burmese,ဗမာစာ
- 緬甸字母,又稱為緬甸語,ဗမာစာ
- Nepali 也稱為 नेपाली
- 荷蘭語(又稱Nederlands、Vlaams)
- 挪威語(又稱為Norsk)
- 奧克西坦語 又稱為奧克西坦語,òc語言
- Oriya 也被稱為 ଓଡ଼ିଆ
- OriyaAlphabet 也稱為 ଓଡ଼ିଆ
- Panjabi 也稱為 ਪੰਜਾਬੀ, پنجابی
- 波蘭語(也稱為język polski、polszczyzna)
- 葡萄牙語 也被稱為 português
- Pashto 也稱為 پښتو
- 克丘亞語 又稱為Runa Simi,Kichwa
- 羅馬尼亞語 又稱為 limba română
- Russian 也稱為 русский язык
- 梵語 亦稱為 संस्कृतम्
- Sinhala 又名為සිංහල
- SinhalaAlphabet 也稱為 සිංහල
- 斯洛伐克語 又稱為slovenčina,slovenský jazyk
- SlovakFraktur 也稱為斯洛伐克語,斯洛伐克語言
- 斯洛文尼亞語 又稱作斯洛文尼亞語,斯洛維尼亞語
- Sindhi 也稱為 सिन्धी, سنڌي، سندھی
- 西班牙語 也稱為español、castellano
- Also known as 西班牙語, 卡斯蒂利亚語
- 阿爾巴尼亞語 又稱為gjuha shqipe
- Serbian 也被稱為 српски језик
- SerbianLatin 也稱為српски језик
- 巽他語 又稱為巴沙蘇達
- 斯瓦希里語 也稱為Kiswahili
- 瑞典語,又被稱為Svenska。
- 敘利亞語 亦稱為敘利亞語、敘利亞阿拉姆語、ܠܫܢܐ ܣܘܪܝܝܐ、Leššānā Suryāyā
- 敘利亞字母也稱為敘利亞方言、敘利亞阿拉姆語、ܠܫܢܐ ܣܘܪܝܝܐ、Leššānā Suryāyā
- Tamil 亦稱為 தமிழ்
- TamilAlphabet 也稱為 தமிழ்
- 韃靼語 也稱為 татар теле,tatar tele
- 泰盧固語 Also known as తెలుగు
- TeluguAlphabet 也被稱為 తెలుగు
- Tajik 也被稱為тоҷикӣ,toğikī,تاجیکی
- Tagalog 亦稱為Wikang Tagalog, ᜏᜒᜃᜅ᜔ ᜆᜄᜎᜓᜄ᜔
- 泰語 亦稱為 ไทย
- ThaanaAlphabet 也稱為 Taana、Tāna、ތާނަ
- 泰文字母 也稱為 ไทย
- TibetanAlphabet 也稱為藏語標準,藏語,中央 ཡིག་
- 提格利尼亞語 也稱為 ትግርኛ
- Tonga 又稱為 faka Tonga
- 土耳其語 又稱為 Türkçe
- Uyghur 也被稱為 Uyƣurqə, ئۇيغۇرچە
- 烏克蘭語 Also known as українська мова
- Urdu 也被稱為 اردو
- Uzbek 亦稱 O‘zbek, Ўзбек, أۇزبېك
- UzbekCyrillic 也被稱為 O‘zbek, Ўзбек, أۇزبېك
- 越南語 又稱為Tiếng Việt
- Tiếng Việt 也被稱為越南字母
- 意第绪语 又称为 ייִדיש
- 也稱為約魯巴
範例:阿拉伯語的 OCR(還有更多)
在以下示例中,我們將展示如何掃描阿拉伯文檔案。
PM> Install-Package IronOcr.Languages.ArabicPM> Install-Package IronOcr.Languages.Arabic
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-6.cs// PM> Install IronOcr.Languages.Arabic
using IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using OcrInput input = new OcrInput();
input.LoadImageFrame("img/arabic.gif", 1);
// add image filters if needed
// In this case, even thought input is very low quality
// IronTesseract can read what conventional Tesseract cannot.
OcrResult result = ocr.Read(input);
// Console can't print Arabic on Windows easily.
// Let's save to disk instead.
result.SaveAsTextFile("arabic.txt");' PM> Install IronOcr.Languages.Arabic
Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.Arabic
Using input As New OcrInput()
input.LoadImageFrame("img/arabic.gif", 1)
' add image filters if needed
' In this case, even thought input is very low quality
' IronTesseract can read what conventional Tesseract cannot.
Dim result As OcrResult = ocr.Read(input)
' Console can't print Arabic on Windows easily.
' Let's save to disk instead.
result.SaveAsTextFile("arabic.txt")
End Using示例:在同一文件中使用多種語言進行光學字元識別。
在下面的範例中,我們將展示如何對同一文件進行多語言的 OCR 掃描。
這其實很常見,例如一份中文文件可能包含英文單詞和網址。
PM> Install-Package IronOcr.Languages.ChineseSimplifiedPM> Install-Package IronOcr.Languages.ChineseSimplified:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-7.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.ChineseSimplified;
// We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Optionally add custom tesseract .traineddata files by specifying a file path
using OcrInput input = new OcrInput();
input.LoadImage("img/MultiLanguage.jpeg");
OcrResult result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.ChineseSimplified
' We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English)
' Optionally add custom tesseract .traineddata files by specifying a file path
Using input As New OcrInput()
input.LoadImage("img/MultiLanguage.jpeg")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsTextFile("MultiLanguage.txt")
End Using多頁文件
IronOCR 可以將多個頁面/圖像合併為單一的 OcrResult。 這在文檔由多個圖像組成時極為有用。 我們稍後會看到,IronTesseract 的這個特殊功能對於從 OCR 輸入產生可搜尋的 PDF 和 HTML 文件非常有用。
IronOcr 可以將圖像、TIFF 幀和 PDF 頁面“混合和匹配”成單一的 OCR 輸入。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-8.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", pageindices);
OcrResult result = ocr.Read(input);
Console.WriteLine($"{result.Pages.Length} Pages"); // 3 PagesImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("image3.gif", pageindices)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine($"{result.Pages.Length} Pages") ' 3 Pages我們也可以輕鬆地對每一頁的TIFF進行OCR。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-9.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("MultiFrame.Tiff", pageindices);
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Length} Pages");
// 1 page for every frame (page) in the TIFFImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
Private pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("MultiFrame.Tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
Console.WriteLine($"{result.Pages.Length} Pages")
' 1 page for every frame (page) in the TIFF:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-10.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadPdf("example.pdf", Password: "password");
// We can also select specific PDF page numbers to OCR
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Length} Pages");
// 1 page for every page of the PDFImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadPdf("example.pdf", Password:= "password")
' We can also select specific PDF page numbers to OCR
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
Console.WriteLine($"{result.Pages.Length} Pages")
' 1 page for every page of the PDF可搜索的 PDF 文件
將 OCR 結果導出為 C# 和 VB.NET 中的可搜索 PDF 是 IronOCR 的一個受歡迎的功能。 這對數據庫填充、SEO 和 PDF 可用性的企業和政府真的很有幫助。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-11.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Quarterly Report";
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Quarterly Report"
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("image3.gif", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")另一個光學字符識別(OCR)技巧是將現有的 PDF 文件轉換為可搜索的格式。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-12.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Metadata Name";
input.LoadPdf("example.pdf", Password: "password");
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Metadata Name"
input.LoadPdf("example.pdf", Password:= "password")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")同樣適用於使用IronTesseract將包含一頁或多頁的TIFF文件轉換為可搜尋的PDF。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-13.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Title";
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Title"
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")導出 Hocr HTML
我們也可以將OCR結果文件導出為Hocr HTML。 這是一個XML文件,可以由XML讀取器解析,或標記成視覺上吸引人的HTML。
這允許一定程度的PDF 到 HTML和TIFF 到 HTML轉換。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-14.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Html Title";
// Add more content as required...
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf",Password: "password");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Html Title"
' Add more content as required...
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf",Password:= "password")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")在 OCR 文件中讀取條碼
IronOCR 較傳統的 tesseract 擁有獨特的額外優勢,還可以讀取條形碼和 QR 碼;
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-15.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
input.LoadImage("img/Barcode.png");
OcrResult result = ocr.Read(input);
foreach (var barcode in result.Barcodes)
{
Console.WriteLine(barcode.Value);
// type and location properties also exposed
}Imports IronOcr
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
input.LoadImage("img/Barcode.png")
Dim result As OcrResult = ocr.Read(input)
For Each barcode In result.Barcodes
Console.WriteLine(barcode.Value)
' type and location properties also exposed
Next barcode
End Using深入探討圖像到文字OCR結果
我們在本教程中將查看的最後一項內容是OCR結果對象。 當我們讀取OCR時,通常只需要文字輸出,但IronOCR實際上包含了大量可能對高級開發者有用的信息。
在OCR結果對象中,我們有一系列可以進行迭代的頁面。 在每個頁面中,我們可能會找到條碼、功率圖、文字行、單詞和字符。
每個對象實際上包含:一個位置; X坐標; 一個Y坐標; 一個寬度和一個高度; 與之關聯的圖像可以進行檢查; 字型名稱; 字體大小;文字書寫的方向; 文字的旋轉; 以及IronOCR對該特定單詞、行或段落的統計信心。
简而言之,这使得开发者可以自由地以他们选择的任何方式创造并处理OCR数据,以检查和导出信息。
我們還可以處理並導出 .NET OCR 結果對象中的任何元素,如段落、單詞或條形碼為圖像或位圖。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-16.csusing IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageindices);
OcrResult result = ocr.Read(input);
foreach (var page in result.Pages)
{
// Page object
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// null if we don't set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap(input);
System.Drawing.Bitmap pageImageLegacy = page.ToBitmap(input);
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int paragraphNumber = paragraph.ParagraphNumber;
String paragraphText = paragraph.Text;
System.Drawing.Bitmap paragraphImage = paragraph.ToBitmap(input);
int paragraphXLocation = paragraph.X;
int paragraphYLocation = paragraph.Y;
int paragraphWidth = paragraph.Width;
int paragraphHeight = paragraph.Height;
double paragraphOcrAccuracy = paragraph.Confidence;
var paragraphTextDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int lineNumber = line.LineNumber;
String lineText = line.Text;
AnyBitmap lineImage = line.ToBitmap(input);
System.Drawing.Bitmap lineImageLegacy = line.ToBitmap(input);
int lineXLocation = line.X;
int lineYLocation = line.Y;
int lineWidth = line.Width;
int lineHeight = line.Height;
double lineOcrAccuracy = line.Confidence;
double lineSkew = line.BaselineAngle;
double lineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int wordNumber = word.WordNumber;
String wordText = word.Text;
AnyBitmap wordImage = word.ToBitmap(input);
System.Drawing.Image wordImageLegacy = word.ToBitmap(input);
int wordXLocation = word.X;
int wordYLocation = word.Y;
int wordWidth = word.Width;
int wordHeight = word.Height;
double wordOcrAccuracy = word.Confidence;
if (word.Font != null)
{
// Word.Font is only set when using Tesseract Engine Modes rather than LTSM
String fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isFixedWidth = word.Font.IsFixedWidth;
bool isItalic = word.Font.IsItalic;
bool isSerif = word.Font.IsSerif;
bool isUnderlined = word.Font.IsUnderlined;
bool fontIsCaligraphic = word.Font.IsCaligraphic;
}
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int characterNumber = character.CharacterNumber;
String characterText = character.Text;
AnyBitmap characterImage = character.ToBitmap(input);
System.Drawing.Bitmap characterImageLegacy = character.ToBitmap(input);
int characterXLocation = character.X;
int characterYLocation = character.Y;
int characterWidth = character.Width;
int characterHeight = character.Height;
double characterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spell checking
OcrResult.Choice[] characterChoices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
For Each page In result.Pages
' Page object
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' null if we don't set Ocr.Configuration.ReadBarCodes = true;
Dim barcodes() As OcrResult.Barcode = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap(input)
Dim pageImageLegacy As System.Drawing.Bitmap = page.ToBitmap(input)
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphImage As System.Drawing.Bitmap = paragraph.ToBitmap(input)
Dim paragraphXLocation As Integer = paragraph.X
Dim paragraphYLocation As Integer = paragraph.Y
Dim paragraphWidth As Integer = paragraph.Width
Dim paragraphHeight As Integer = paragraph.Height
Dim paragraphOcrAccuracy As Double = paragraph.Confidence
Dim paragraphTextDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim lineNumber As Integer = line.LineNumber
Dim lineText As String = line.Text
Dim lineImage As AnyBitmap = line.ToBitmap(input)
Dim lineImageLegacy As System.Drawing.Bitmap = line.ToBitmap(input)
Dim lineXLocation As Integer = line.X
Dim lineYLocation As Integer = line.Y
Dim lineWidth As Integer = line.Width
Dim lineHeight As Integer = line.Height
Dim lineOcrAccuracy As Double = line.Confidence
Dim lineSkew As Double = line.BaselineAngle
Dim lineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim wordNumber As Integer = word.WordNumber
Dim wordText As String = word.Text
Dim wordImage As AnyBitmap = word.ToBitmap(input)
Dim wordImageLegacy As System.Drawing.Image = word.ToBitmap(input)
Dim wordXLocation As Integer = word.X
Dim wordYLocation As Integer = word.Y
Dim wordWidth As Integer = word.Width
Dim wordHeight As Integer = word.Height
Dim wordOcrAccuracy As Double = word.Confidence
If word.Font IsNot Nothing Then
' Word.Font is only set when using Tesseract Engine Modes rather than LTSM
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isFixedWidth As Boolean = word.Font.IsFixedWidth
Dim isItalic As Boolean = word.Font.IsItalic
Dim isSerif As Boolean = word.Font.IsSerif
Dim isUnderlined As Boolean = word.Font.IsUnderlined
Dim fontIsCaligraphic As Boolean = word.Font.IsCaligraphic
End If
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim characterNumber As Integer = character.CharacterNumber
Dim characterText As String = character.Text
Dim characterImage As AnyBitmap = character.ToBitmap(input)
Dim characterImageLegacy As System.Drawing.Bitmap = character.ToBitmap(input)
Dim characterXLocation As Integer = character.X
Dim characterYLocation As Integer = character.Y
Dim characterWidth As Integer = character.Width
Dim characterHeight As Integer = character.Height
Dim characterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spell checking
Dim characterChoices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next page
End Using摘要
IronOCR 為 C# 開發人員提供我們所知在任何平台上最先進的Tesseract API。
IronOCR 可以部署在 Windows、Linux、Mac、Azure、AWS、Lambda 上,並支持 .NET Framework、.NET Standard 和 .NET Core 專案。
即便是輸入一份不完美的文件到IronOCR,它仍能以大約99%的統計準確率準確讀取其內容,即使該文件格式不良、歪斜且有數字噪音。
我們還可以在OCR掃描中讀取條碼,甚至將我們的OCR導出為HTML和可搜索的PDF。
這是IronOCR獨有的功能,您在標準OCR庫或原生Tesseract中找不到此功能。
向前邁進
要繼續了解更多關於IronOCR的資訊,我們建議您:
- 開始使用我們的C# Tesseract OCR 快速入門指南。
- 探索C#和VB代碼範例
- 閱讀深入的MSDN 風格 API 參考。
源代碼下載
- Github 儲存庫
-
您可能也會喜歡本節中的其他 .NET OCR 教程。







