


C# OCR Image to Text Tutorial: Convert Images to Text Without Tesseract
Vous cherchez à convertir des images en texte en C# sans avoir à vous soucier des configurations complexes de Tesseract ? Ce tutoriel complet sur IronOCR en C# vous montre comment implémenter une puissante reconnaissance optique de caractères dans vos applications .NET avec seulement quelques lignes de code.
Guide de démarrage rapide : extraire du texte d'une image en une seule ligne
Cet exemple montre à quel point IronOCR est facile à appréhender : une seule ligne de C# transforme votre image en texte. Il démontre l'initialisation du moteur OCR et la lecture et la récupération immédiates du texte sans configuration complexe.
-
Installez IronOCR avec le Gestionnaire de Packages NuGet
-
Copiez et exécutez cet extrait de code.
string text = new IronTesseract().Read("image.png").Text; -
Déployez pour tester sur votre environnement de production.
Commencez à utiliser IronOCR dans votre projet dès aujourd'hui avec un essai gratuit

Flux de travail minimal (5 étapes)
- Téléchargez IronOCR - la bibliothèque OCR C# pour la conversion d'images en texte
- Utilisez la classe
IronTesseractpour lire instantanément le texte des images. - Appliquez des filtres d'image pour améliorer la précision de la reconnaissance optique de caractères (OCR) sur les numérisations de faible qualité.
- Gérez plusieurs langues grâce aux packs de langues téléchargeables.
- Exporter les résultats sous forme de PDF consultables ou extraire des chaînes de texte
Comment lire le texte des images dans les applications .NET ?
Pour intégrer la fonctionnalité de conversion d'images en texte par reconnaissance optique de caractères (OCR) en C# dans vos applications .NET, vous aurez besoin d'une bibliothèque OCR fiable. IronOCR fournit une solution gérée utilisant la classe IronOcr.IronTesseract qui maximise à la fois la précision et la rapidité sans nécessiter de dépendances externes.
Commencez par installer IronOCR dans votre projet Visual Studio. Vous pouvez télécharger directement la DLL IronOCR ou utiliser le gestionnaire de packages NuGet .
Install-Package IronOcr
Pourquoi choisir IronOCR pour l'OCR en C# sans Tesseract ?
Lorsque vous devez convertir des images en texte en C#, IronOCR offre des avantages significatifs par rapport aux implémentations Tesseract traditionnelles :
- Fonctionne immédiatement dans les environnements .NET purs Aucune installation ni configuration de Tesseract requise
- Fonctionne avec les moteurs les plus récents : Tesseract 5 (ainsi que Tesseract 4 et 3)
- Compatible avec .NET Framework 4.6.2+, .NET Standard 2+ et .NET Core 2, 3, 5, 6, 7, 8, 9 et 10
- Améliore la précision et la vitesse par rapport au Tesseract de base
- Prend en charge les déploiements Xamarin, Mono, Azure et Docker
- Gère les dictionnaires Tesseract complexes via les packages NuGet
- Prend en charge automatiquement les fichiers PDF, les TIFF multi-images et tous les principaux formats d'image.
- Corrige les numérisations de mauvaise qualité et déformées pour des résultats optimaux
Comment utiliser le tutoriel IronOCR C# pour un OCR de base ?
Cet exemple C# avec Iron Tesseract illustre la méthode la plus simple pour lire du texte à partir d'une image à l'aide d'IronOCR. La classe IronOcr.IronTesseract extrait du texte et le retourne sous forme de chaîne.
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-3.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageindices);
input.Deskew(); // removes rotation and perspective
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
Private pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.LowQuality.tiff", pageindices)
input.Deskew() ' removes rotation and perspective
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)Ce code atteint une précision de 100 % sur les images nettes, en extrayant le texte exactement comme il apparaît :
IronOCR Simple Example
In this simple example we test the accuracy of our C# OCR library to read text from a PNG Image. This is a very basic test, but things will get more complicated as the tutorial continues.
The quick brown fox jumps over the lazy dogLa classe IronTesseract gère les opérations OCR complexes en interne. Il effectue automatiquement une analyse d'alignement, optimise la résolution et utilise l'IA pour lire le texte de l'image grâce à IronOCR avec une précision comparable à celle de l'humain.
Malgré le traitement sophistiqué qui s'effectue en arrière-plan — incluant l'analyse d'images, l'optimisation du moteur et la reconnaissance intelligente de texte — le processus OCR atteint une vitesse de lecture humaine tout en conservant des niveaux de précision exceptionnels.
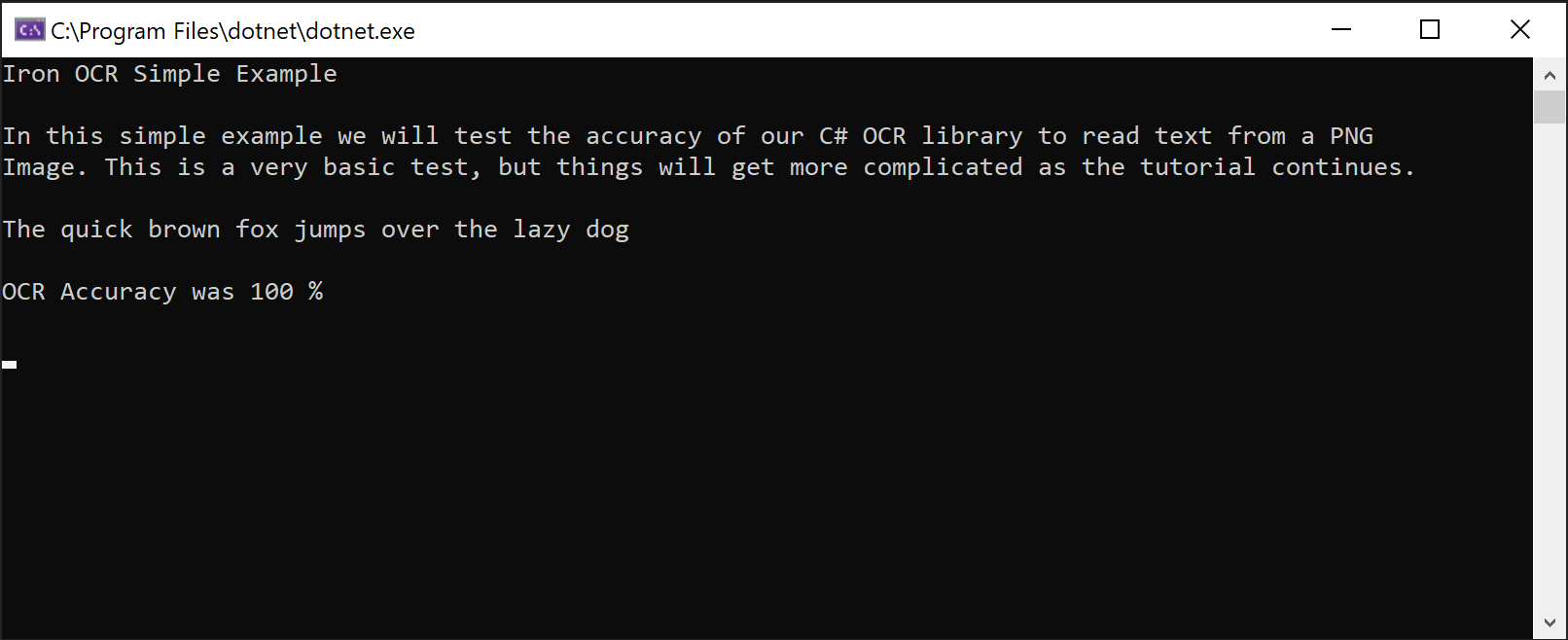 Capture d'écran démontrant la capacité d'IronOCR à extraire du texte d'une image PNG avec une précision parfaite
Capture d'écran démontrant la capacité d'IronOCR à extraire du texte d'une image PNG avec une précision parfaite
Comment mettre en œuvre un OCR C# avancé sans configuration Tesseract ?
Pour les applications de production nécessitant une performance optimale lorsque vous convertissez des images en texte en C#, utilisez les classes OcrInput et IronTesseract ensemble. Cette approche permet un contrôle précis du processus OCR.
Fonctionnalités de la classe OcrInput
- Prend en charge plusieurs formats d'image : JPEG, TIFF, GIF, BMP, PNG
- Importe des PDF complets ou des pages spécifiques
- Améliore automatiquement le contraste, la résolution et la qualité d'image
- Corrige la rotation, le bruit de numérisation, l'inclinaison et les images négatives
Fonctionnalités de la classe IronTesseract
- Accès à plus de 127 langues pré-intégrées
- Moteurs Tesseract 5, 4 et 3 inclus
- Spécification du type de document (capture d'écran, extrait ou document complet)
- Fonctionnalités intégrées de lecture de codes-barres
- Formats de sortie multiples : PDF consultables, HTML HOCR, objets DOM et chaînes de caractères
Comment commencer avec OcrInput et IronTesseract ?
Voici une configuration recommandée pour ce tutoriel IronOCR en C# qui fonctionne bien avec la plupart des types de documents :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-5.csusing IronOcr;
using IronSoftware.Drawing;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
// restrict OCR to a content area for faster processing
Rectangle contentArea = new Rectangle(x: 215, y: 1250, height: 280, width: 1335);
input.LoadImage("img/ComSci.png", contentArea);
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Imports IronSoftware.Drawing
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' restrict OCR to a content area for faster processing
Dim contentArea As New Rectangle(x:=215, y:=1250, height:=280, width:=1335)
input.LoadImage("img/ComSci.png", contentArea)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End UsingCette configuration permet d'obtenir systématiquement une précision quasi parfaite sur des numérisations de qualité moyenne. La méthode LoadImageFrames gère efficacement les documents multi-page, ce qui la rend idéale pour les scénarios de traitement par lots.

Exemple de document TIFF illustrant les capacités d'extraction de texte multipage d'IronOCR
La capacité à lire du texte à partir d'images et de codes-barres dans des documents numérisés comme les fichiers TIFF illustre comment IronOCR simplifie les tâches OCR complexes. La bibliothèque excelle avec les documents du monde réel, gérant de manière transparente les fichiers TIFF multipages et l'extraction de texte PDF .
Comment IronOCR gère-t-il les numérisations de faible qualité ?

Document basse résolution bruité qu'IronOCR peut traiter avec précision grâce à des filtres d'image.
Lors du traitement de numérisations imparfaites contenant des distorsions et du bruit numérique, IronOCR surpasse les autres bibliothèques OCR C# . Il est spécifiquement conçu pour des scénarios réels plutôt que pour des images de test impeccables.
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-6.cs// PM> Install IronOcr.Languages.Arabic
using IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using OcrInput input = new OcrInput();
input.LoadImageFrame("img/arabic.gif", 1);
// add image filters if needed
// In this case, even thought input is very low quality
// IronTesseract can read what conventional Tesseract cannot.
OcrResult result = ocr.Read(input);
// Console can't print Arabic on Windows easily.
// Let's save to disk instead.
result.SaveAsTextFile("arabic.txt");' PM> Install IronOcr.Languages.Arabic
Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.Arabic
Using input As New OcrInput()
input.LoadImageFrame("img/arabic.gif", 1)
' add image filters if needed
' In this case, even thought input is very low quality
' IronTesseract can read what conventional Tesseract cannot.
Dim result As OcrResult = ocr.Read(input)
' Console can't print Arabic on Windows easily.
' Let's save to disk instead.
result.SaveAsTextFile("arabic.txt")
End UsingEn utilisant Input.Deskew(), la précision s'améliore à 99,8% sur les scans de faible qualité, presque équivalent aux résultats de haute qualité. Cela démontre pourquoi IronOCR est le choix privilégié pour la reconnaissance optique de caractères (OCR) en C# sans les complications liées à Tesseract.
Les filtres d'image peuvent légèrement augmenter le temps de traitement, mais réduisent considérablement la durée globale de la reconnaissance optique de caractères (OCR). Trouver le juste équilibre dépend de la qualité de vos documents.
Pour la plupart des scénarios, Input.Deskew() et Input.DeNoise() fournissent des améliorations fiables à la performance de l'OCR. Apprenez-en davantage sur les techniques de prétraitement d'images .
Comment optimiser les performances et la vitesse de la reconnaissance optique de caractères (OCR) ?
Le facteur le plus important affectant la vitesse de la reconnaissance optique de caractères (OCR) lors de la conversion d'images en texte en C# est la qualité des données d'entrée. Une résolution DPI plus élevée (~200 dpi) avec un bruit minimal produit les résultats les plus rapides et les plus précis.
Bien qu'IronOCR excelle dans la correction de documents imparfaits, cette amélioration nécessite un temps de traitement supplémentaire.
Choisissez des formats d'image présentant un minimum d'artefacts de compression. Les formats TIFF et PNG donnent généralement des résultats plus rapides que le JPEG grâce à un bruit numérique plus faible.
Quels filtres d'image améliorent la vitesse de la reconnaissance optique de caractères (OCR) ?
Les filtres suivants peuvent améliorer considérablement les performances de votre flux de travail de conversion d'images en texte par reconnaissance optique de caractères (OCR) en C# :
OcrInput.Rotate(double degrees): Fait tourner les images dans le sens des aiguilles d'une montre (négatif pour le sens inverse)OcrInput.Binarize(): Convertit en noir/blanc, améliorant la performance dans des scénarios à faible contrasteOcrInput.ToGrayScale(): Convertit en nuances de gris pour des améliorations potentielles de vitesseOcrInput.Contrast(): Ajuste automatiquement le contraste pour une meilleure précisionOcrInput.DeNoise(): Enlève les artefacts numériques lorsque le bruit est attenduOcrInput.Invert(): Inverse les couleurs pour le texte blanc sur noirOcrInput.Dilate(): Étend les limites du texteOcrInput.Erode(): Réduit les limites du texteOcrInput.Deskew(): Corrige l'alignement - essentiel pour les documents biaisésOcrInput.DeepCleanBackgroundNoise(): Suppression agressive du bruitOcrInput.EnhanceResolution: Améliore la qualité des images de basse résolutionOcrInput.DetectPageOrientation(): Détecte et corrige la rotation des pages. Passez unOrientationDetectionModepour contrôler le compromis précision/vitesse :Fast,Balanced,DetailedouExtremeDetailed(ajouté v2025.8.6)
Scale() et EnhanceResolution() sont incompatibles avec SaveAsSearchablePdf() en raison d'un problème connu dans v2025.12.3. Tous les autres filtres fonctionnent correctement avec la sortie de PDF indexable.
Comment configurer IronOCR pour une vitesse maximale ?
Utilisez ces paramètres pour optimiser la vitesse lors du traitement de numérisations de haute qualité :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-7.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.ChineseSimplified;
// We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Optionally add custom tesseract .traineddata files by specifying a file path
using OcrInput input = new OcrInput();
input.LoadImage("img/MultiLanguage.jpeg");
OcrResult result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.ChineseSimplified
' We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English)
' Optionally add custom tesseract .traineddata files by specifying a file path
Using input As New OcrInput()
input.LoadImage("img/MultiLanguage.jpeg")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsTextFile("MultiLanguage.txt")
End UsingCette configuration optimisée maintient une précision de 99,8 % tout en permettant une amélioration de la vitesse de 35 % par rapport aux paramètres par défaut.
Comment lire des zones spécifiques d'images à l'aide de l'OCR en C# ?
L'exemple Iron Tesseract C# ci-dessous montre comment cibler des régions spécifiques en utilisant System.Drawing.Rectangle. Cette technique est précieuse pour le traitement des formulaires standardisés où le texte apparaît à des emplacements prévisibles.
IronOCR peut-il traiter les régions recadrées pour des résultats plus rapides ?
En utilisant des coordonnées basées sur les pixels, vous pouvez limiter la reconnaissance optique de caractères (OCR) à des zones spécifiques, ce qui améliore considérablement la vitesse et empêche l'extraction de texte indésirable :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-8.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", pageindices);
OcrResult result = ocr.Read(input);
Console.WriteLine($"{result.Pages.Length} Pages"); // 3 PagesImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("image3.gif", pageindices)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine($"{result.Pages.Length} Pages") ' 3 PagesCette approche ciblée permet un gain de vitesse de 41 % tout en extrayant uniquement le texte pertinent. Il est idéal pour les documents structurés tels que les factures , les chèques et les formulaires. La même technique de recadrage fonctionne parfaitement avec les opérations OCR de PDF .
 Document illustrant l'extraction précise de texte par région à l'aide de la sélection rectangulaire d'IronOCR
Document illustrant l'extraction précise de texte par région à l'aide de la sélection rectangulaire d'IronOCR
Combien de langues IronOCR prend-il en charge ?
IronOCR propose 127 langues internationales via des packs linguistiques pratiques. Téléchargez-les sous forme de DLL depuis notre site web ou via le gestionnaire de packages NuGet .
Installez les modules linguistiques via l'interface NuGet ( recherchez " IronOcr.Languages " ) ou consultez la liste complète des modules linguistiques .
Les langues prises en charge incluent l'arabe, le chinois (simplifié/traditionnel), le japonais, le coréen, l'hindi, le russe, l'allemand, le français, l'espagnol et plus de 115 autres, chacune optimisée pour une reconnaissance de texte précise.
Comment implémenter la reconnaissance optique de caractères (OCR) dans plusieurs langues ?
Ce tutoriel IronOCR en C# illustre la reconnaissance de texte arabe :
Install-Package IronOcr.Languages.Arabic

IronOCR extrait avec précision du texte arabe d'une image GIF
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-10.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadPdf("example.pdf", Password: "password");
// We can also select specific PDF page numbers to OCR
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Length} Pages");
// 1 page for every page of the PDFImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadPdf("example.pdf", Password:= "password")
' We can also select specific PDF page numbers to OCR
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
Console.WriteLine($"{result.Pages.Length} Pages")
' 1 page for every page of the PDFIronOCR peut-il gérer des documents multilingues ?
Lorsque les documents contiennent plusieurs langues, configurez IronOCR pour la prise en charge multilingue :
Install-Package IronOcr.Languages.ChineseSimplified
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-12.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Metadata Name";
input.LoadPdf("example.pdf", Password: "password");
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Metadata Name"
input.LoadPdf("example.pdf", Password:= "password")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")Comment traiter des documents multi-pages avec OCR en C# ?
IronOCR combine harmonieusement plusieurs pages ou images dans un seul OcrResult. Cette fonctionnalité offre des possibilités puissantes telles que la création de PDF consultables et l'extraction de texte à partir d'ensembles de documents.
Combinez et associez différentes sources (images, images TIFF et pages PDF) en une seule opération OCR :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-13.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Title";
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Title"
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")Traiter efficacement toutes les pages d'un fichier TIFF :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-14.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Html Title";
// Add more content as required...
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf",Password: "password");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Html Title"
' Add more content as required...
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf",Password:= "password")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")Convertir les fichiers TIFF ou PDF en formats consultables :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-15.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
input.LoadImage("img/Barcode.png");
OcrResult result = ocr.Read(input);
foreach (var barcode in result.Barcodes)
{
Console.WriteLine(barcode.Value);
// type and location properties also exposed
}Imports IronOcr
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
input.LoadImage("img/Barcode.png")
Dim result As OcrResult = ocr.Read(input)
For Each barcode In result.Barcodes
Console.WriteLine(barcode.Value)
' type and location properties also exposed
Next barcode
End UsingConvertir les fichiers PDF existants en versions consultables :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-16.csusing IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageindices);
OcrResult result = ocr.Read(input);
foreach (var page in result.Pages)
{
// Page object
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// null if we don't set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap(input);
System.Drawing.Bitmap pageImageLegacy = page.ToBitmap(input);
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int paragraphNumber = paragraph.ParagraphNumber;
String paragraphText = paragraph.Text;
System.Drawing.Bitmap paragraphImage = paragraph.ToBitmap(input);
int paragraphXLocation = paragraph.X;
int paragraphYLocation = paragraph.Y;
int paragraphWidth = paragraph.Width;
int paragraphHeight = paragraph.Height;
double paragraphOcrAccuracy = paragraph.Confidence;
var paragraphTextDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int lineNumber = line.LineNumber;
String lineText = line.Text;
AnyBitmap lineImage = line.ToBitmap(input);
System.Drawing.Bitmap lineImageLegacy = line.ToBitmap(input);
int lineXLocation = line.X;
int lineYLocation = line.Y;
int lineWidth = line.Width;
int lineHeight = line.Height;
double lineOcrAccuracy = line.Confidence;
double lineSkew = line.BaselineAngle;
double lineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int wordNumber = word.WordNumber;
String wordText = word.Text;
AnyBitmap wordImage = word.ToBitmap(input);
System.Drawing.Image wordImageLegacy = word.ToBitmap(input);
int wordXLocation = word.X;
int wordYLocation = word.Y;
int wordWidth = word.Width;
int wordHeight = word.Height;
double wordOcrAccuracy = word.Confidence;
if (word.Font != null)
{
// Word.Font is only set when using Tesseract Engine Modes rather than LTSM
String fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isFixedWidth = word.Font.IsFixedWidth;
bool isItalic = word.Font.IsItalic;
bool isSerif = word.Font.IsSerif;
bool isUnderlined = word.Font.IsUnderlined;
bool fontIsCaligraphic = word.Font.IsCaligraphic;
}
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int characterNumber = character.CharacterNumber;
String characterText = character.Text;
AnyBitmap characterImage = character.ToBitmap(input);
System.Drawing.Bitmap characterImageLegacy = character.ToBitmap(input);
int characterXLocation = character.X;
int characterYLocation = character.Y;
int characterWidth = character.Width;
int characterHeight = character.Height;
double characterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spell checking
OcrResult.Choice[] characterChoices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
For Each page In result.Pages
' Page object
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' null if we don't set Ocr.Configuration.ReadBarCodes = true;
Dim barcodes() As OcrResult.Barcode = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap(input)
Dim pageImageLegacy As System.Drawing.Bitmap = page.ToBitmap(input)
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphImage As System.Drawing.Bitmap = paragraph.ToBitmap(input)
Dim paragraphXLocation As Integer = paragraph.X
Dim paragraphYLocation As Integer = paragraph.Y
Dim paragraphWidth As Integer = paragraph.Width
Dim paragraphHeight As Integer = paragraph.Height
Dim paragraphOcrAccuracy As Double = paragraph.Confidence
Dim paragraphTextDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim lineNumber As Integer = line.LineNumber
Dim lineText As String = line.Text
Dim lineImage As AnyBitmap = line.ToBitmap(input)
Dim lineImageLegacy As System.Drawing.Bitmap = line.ToBitmap(input)
Dim lineXLocation As Integer = line.X
Dim lineYLocation As Integer = line.Y
Dim lineWidth As Integer = line.Width
Dim lineHeight As Integer = line.Height
Dim lineOcrAccuracy As Double = line.Confidence
Dim lineSkew As Double = line.BaselineAngle
Dim lineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim wordNumber As Integer = word.WordNumber
Dim wordText As String = word.Text
Dim wordImage As AnyBitmap = word.ToBitmap(input)
Dim wordImageLegacy As System.Drawing.Image = word.ToBitmap(input)
Dim wordXLocation As Integer = word.X
Dim wordYLocation As Integer = word.Y
Dim wordWidth As Integer = word.Width
Dim wordHeight As Integer = word.Height
Dim wordOcrAccuracy As Double = word.Confidence
If word.Font IsNot Nothing Then
' Word.Font is only set when using Tesseract Engine Modes rather than LTSM
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isFixedWidth As Boolean = word.Font.IsFixedWidth
Dim isItalic As Boolean = word.Font.IsItalic
Dim isSerif As Boolean = word.Font.IsSerif
Dim isUnderlined As Boolean = word.Font.IsUnderlined
Dim fontIsCaligraphic As Boolean = word.Font.IsCaligraphic
End If
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim characterNumber As Integer = character.CharacterNumber
Dim characterText As String = character.Text
Dim characterImage As AnyBitmap = character.ToBitmap(input)
Dim characterImageLegacy As System.Drawing.Bitmap = character.ToBitmap(input)
Dim characterXLocation As Integer = character.X
Dim characterYLocation As Integer = character.Y
Dim characterWidth As Integer = character.Width
Dim characterHeight As Integer = character.Height
Dim characterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spell checking
Dim characterChoices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next page
End UsingAppliquez la même technique aux conversions TIFF :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-17.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Configure document properties
input.Title = "Scanned Archive Document";
// Select pages to process
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Create searchable PDF from TIFF
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Configure document properties
input.Title = "Scanned Archive Document"
' Select pages to process
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Create searchable PDF from TIFF
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")
End UsingComment exporter les résultats OCR au format HTML HOCR ?
IronOCR prend en charge l'exportation HTML HOCR, permettant la conversion de PDF structurés en HTML et de TIFF en HTML tout en préservant les informations de mise en page :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-18.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set HTML title
input.Title = "Document Archive";
// Process multiple document types
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf", "password");
// Add TIFF pages
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Export as HOCR with position data
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Set HTML title
input.Title = "Document Archive"
' Process multiple document types
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf", "password")
' Add TIFF pages
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Export as HOCR with position data
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")
End UsingIronOCR peut-il lire les codes-barres ainsi que le texte ?
IronOCR combine de manière unique la reconnaissance de texte et la lecture de codes-barres , éliminant ainsi le besoin de bibliothèques séparées :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-19.cs// Enable combined text and barcode recognition
using IronOcr;
var ocr = new IronTesseract();
// Enable barcode detection
ocr.Configuration.ReadBarCodes = true;
using (var input = new OcrInput())
{
// Load image containing both text and barcodes
input.LoadImage("img/Barcode.png");
// Process both text and barcodes
var result = ocr.Read(input);
// Extract barcode data
foreach (var barcode in result.Barcodes)
{
Console.WriteLine($"Barcode Value: {barcode.Value}");
Console.WriteLine($"Format: {barcode.Format}");
}
}
Imports IronOcr
Dim ocr As New IronTesseract()
' Enable barcode detection
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
' Load image containing both text and barcodes
input.LoadImage("img/Barcode.png")
' Process both text and barcodes
Dim result = ocr.Read(input)
' Extract barcode data
For Each barcode In result.Barcodes
Console.WriteLine($"Barcode Value: {barcode.Value}")
Console.WriteLine($"Format: {barcode.Format}")
Next
End UsingComment accéder aux résultats OCR détaillés et aux métadonnées ?
L'objet de résultats IronOCR fournit des données complètes que les développeurs avancés peuvent exploiter pour des applications sophistiquées.
Chaque OcrResult contient des collections hiérarchiques : pages, paragraphes, lignes, mots, et caractères. Tous les éléments incluent des métadonnées détaillées telles que l'emplacement, les informations sur la police et les scores de confiance.
Les éléments individuels (paragraphes, mots, codes-barres) peuvent être exportés sous forme d'images ou de bitmaps pour un traitement ultérieur :
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-20.csusing System;
using IronOcr;
using IronSoftware.Drawing;
// Configure with barcode support
IronTesseract ocr = new IronTesseract
{
Configuration = { ReadBarCodes = true }
};
using OcrInput input = new OcrInput();
// Process multi-page document
int[] pageIndices = { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
OcrResult result = ocr.Read(input);
// Navigate the complete results hierarchy
foreach (var page in result.Pages)
{
// Page-level data
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// Extract page elements
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap();
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Paragraph properties
int paragraphNumber = paragraph.ParagraphNumber;
string paragraphText = paragraph.Text;
double paragraphConfidence = paragraph.Confidence;
var textDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Line details including baseline information
string lineText = line.Text;
double lineConfidence = line.Confidence;
double baselineAngle = line.BaselineAngle;
double baselineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Word-level data
string wordText = word.Text;
double wordConfidence = word.Confidence;
// Font information (when available)
if (word.Font != null)
{
string fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isItalic = word.Font.IsItalic;
}
foreach (var character in word.Characters)
{
// Character-level analysis
string charText = character.Text;
double charConfidence = character.Confidence;
// Alternative character choices for spell-checking
OcrResult.Choice[] alternatives = character.Choices;
}
}
}
}
}
Imports System
Imports IronOcr
Imports IronSoftware.Drawing
' Configure with barcode support
Dim ocr As New IronTesseract With {
.Configuration = New TesseractConfiguration With {
.ReadBarCodes = True
}
}
Using input As New OcrInput()
' Process multi-page document
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("img\Potter.tiff", pageIndices)
Dim result As OcrResult = ocr.Read(input)
' Navigate the complete results hierarchy
For Each page In result.Pages
' Page-level data
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' Extract page elements
Dim barcodes As OcrResult.Barcode() = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap()
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Paragraph properties
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphConfidence As Double = paragraph.Confidence
Dim textDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Line details including baseline information
Dim lineText As String = line.Text
Dim lineConfidence As Double = line.Confidence
Dim baselineAngle As Double = line.BaselineAngle
Dim baselineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Word-level data
Dim wordText As String = word.Text
Dim wordConfidence As Double = word.Confidence
' Font information (when available)
If word.Font IsNot Nothing Then
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isItalic As Boolean = word.Font.IsItalic
End If
For Each character In word.Characters
' Character-level analysis
Dim charText As String = character.Text
Dim charConfidence As Double = character.Confidence
' Alternative character choices for spell-checking
Dim alternatives As OcrResult.Choice() = character.Choices
Next
Next
Next
Next
Next
End UsingRésumé
IronOCR offre aux développeurs C# l'implémentation la plus avancée de l'API Tesseract , fonctionnant de manière transparente sur les plateformes Windows, Linux et Mac. Sa capacité à lire avec précision le texte à partir d'une image grâce à IronOCR — même à partir de documents imparfaits — la distingue des solutions OCR de base.
Les caractéristiques uniques de la bibliothèque incluent la lecture intégrée des codes-barres et la possibilité d'exporter les résultats sous forme de PDF consultables ou de HTML HOCR, des fonctionnalités indisponibles dans les implémentations Tesseract standard.
Aller de l'avant
Pour continuer à maîtriser IronOCR :
- Consultez notre guide complet pour bien démarrer
- Parcourez des exemples de code C# pratiques
- Consultez la documentation détaillée de l'API.
Téléchargement du code source
Prêt à implémenter la conversion d'images en texte par reconnaissance optique de caractères (OCR) en C# dans vos applications ? Téléchargez IronOCR et commencez votre essai gratuit dès aujourd'hui.
Questions Fréquemment Posées
Comment puis-je convertir des images en texte en C# sans utiliser Tesseract ?
Vous pouvez utiliser IronOCR pour convertir des images en texte en C# sans avoir besoin de Tesseract. IronOCR simplifie le processus avec des méthodes intégrées qui gèrent directement la conversion image-texte.
Comment améliorer la précision de l'OCR sur les images de faible qualité ?
IronOCR fournit des filtres d'image tels que Input.Deskew() et Input.DeNoise() qui peuvent être utilisés pour améliorer les images de faible qualité en corrigeant les distorsions et en réduisant le bruit, améliorant ainsi considérablement la précision de l'OCR.
Quelles sont les étapes pour extraire du texte d'un document multipage en utilisant l'OCR en C# ?
Pour extraire du texte de documents multipages, IronOCR vous permet de charger et traiter chaque page en utilisant des méthodes comme LoadPdf() pour les PDF ou en manipulant les fichiers TIFF, convertissant efficacement chaque page en texte.
Est-il possible de lire simultanément des codes-barres et du texte à partir d'une image ?
Oui, IronOCR peut lire à la fois le texte et les codes-barres à partir d'une seule image. Vous pouvez activer la lecture de codes-barres avec ocr.Configuration.ReadBarCodes = true, ce qui permet l'extraction à la fois des données textuelles et de code-barres.
Comment puis-je configurer l'OCR pour traiter des documents dans plusieurs langues ?
IronOCR prend en charge plus de 125 langues et vous permet de définir une langue principale en utilisant ocr.Language et d'ajouter des langues supplémentaires avec ocr.AddSecondaryLanguage() pour le traitement de documents multilingues.
Quelles méthodes sont disponibles pour exporter les résultats de l'OCR dans différents formats ?
IronOCR offre plusieurs méthodes pour exporter les résultats OCR, telles que SaveAsSearchablePdf() pour les PDF, SaveAsTextFile() pour le texte brut, et SaveAsHocrFile() pour le format HTML HOCR.
Comment puis-je optimiser la vitesse de traitement OCR pour les fichiers image volumineux ?
Pour optimiser la vitesse de traitement OCR, utilisez OcrLanguage.EnglishFast d'IronOCR pour une reconnaissance de langue plus rapide et définissez des régions spécifiques pour l'OCR en utilisant System.Drawing.Rectangle afin de réduire le temps de traitement.
Comment gérer le traitement OCR pour les fichiers PDF protégés ?
Lors de la manipulation de fichiers PDF protégés, utilisez la méthode LoadPdf() avec le bon mot de passe. IronOCR gère les PDF basés sur des images en convertissant automatiquement les pages en images pour le traitement de l'OCR.
Que dois-je faire si les résultats de l'OCR ne sont pas précis ?
Si les résultats de l'OCR sont inexacts, envisagez d'utiliser les fonctionnalités d'amélioration d'image d'IronOCR comme Input.Deskew() et Input.DeNoise(), et assurez-vous que les packs linguistiques corrects sont installés.
Puis-je personnaliser le processus OCR pour exclure certains caractères ?
Oui, IronOCR permet la personnalisation du processus OCR en utilisant la propriété BlackListCharacters pour exclure certains caractères, améliorant la précision et la vitesse de traitement en se concentrant uniquement sur le texte pertinent.



Vous faites encore défiler ?
Vous voulez une preuve rapidement ? PM > Install-Package IronOcr
lancez un échantillon regardez votre image se transformer en texte consultable.










