

Teste em um ambiente real
Teste em produção sem marcas d'água.
Funciona onde você precisar.

30DAYFREE
using IronWebScraper;
public class Program
{
private static void Main(string[] args)
{
var ScrapeJob = new BlogScraper();
ScrapeJob.Start();
}
}
public class BlogScraper : WebScraper
{
public override void Init()
{
LoggingLevel = LogLevel.All;
Request("https://www.zyte.com/blog/", Parse);
}
public override void Parse(Response response)
{
foreach (HtmlNode title_link in response.Css(".oxy-post-title"))
{
string strTitle = title_link.TextContentClean;
Scrape(new ScrapedData() { { "Title", strTitle } });
}
if (response.CssExists("div.oxy-easy-posts-pages > a[href]"))
{
string next_page = response.Css("div.oxy-easy-posts-pages > a[href]")[0].Attributes["href"];
Request(next_page, Parse);
}
}
}Install-Package IronWebScraper
Projetado para C#, F# e VB.NET executados no .NET 10, 9, 8, 7, 6, 5, Core, Standard ou Framework.

")
")
")
")
")
")
")
")
")
")
")
")
")
")
Raspe milhares de páginas de uma única classe C#. Seletor CSS, XPath, renderização de JavaScript, identidades virtuais e controles de polidez em uma só biblioteca.

Request(url, Parse), response.Css(".selector"), Scrape(data).using IronWebScraper;
public class Program
{
private static void Main(string[] args)
{
var ScrapeJob = new BlogScraper();
ScrapeJob.Start();
}
}
public class BlogScraper : WebScraper
{
public override void Init()
{
LoggingLevel = LogLevel.All;
Request("https://www.zyte.com/blog/", Parse);
}
public override void Parse(Response response)
{
foreach (HtmlNode title_link in response.Css(".oxy-post-title"))
{
string strTitle = title_link.TextContentClean;
Scrape(new ScrapedData() { { "Title", strTitle } });
}
if (response.CssExists("div.oxy-easy-posts-pages > a[href]"))
{
string next_page = response.Css("div.oxy-easy-posts-pages > a[href]")[0].Attributes["href"];
Request(next_page, Parse);
}
}
}Imports IronWebScraper
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim ScrapeJob = New BlogScraper()
ScrapeJob.Start()
End Sub
End Class
Public Class BlogScraper
Inherits WebScraper
Public Overrides Sub Init()
LoggingLevel = LogLevel.All
Request("https://www.zyte.com/blog/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each title_link As HtmlNode In response.Css(".oxy-post-title")
Dim strTitle As String = title_link.TextContentClean
Scrape(New ScrapedData() From {
{ "Title", strTitle }
})
Next title_link
If response.CssExists("div.oxy-easy-posts-pages > a[href]") Then
Dim next_page As String = response.Css("div.oxy-easy-posts-pages > a[href]")(0).Attributes("href")
Request(next_page, AddressOf Parse)
End If
End Sub
End ClassInstall-Package IronWebScraper
IronWebScraper fornece uma estrutura poderosa para extrair dados e arquivos de sites usando código C#.
WebScraper.Init que usa o método Request para analisar pelo menos uma URL.Parse para processar as solicitações, e de fato Request mais páginas. Use response.Css para trabalhar com elementos HTML usando seletores CSS no estilo jQuery.Start();.Descubra como extrair dados de sites de filmes online com C#

Seja para dúvidas sobre produtos, integração ou licenciamento, a equipe de desenvolvimento de produtos da Iron está à disposição para ajudar com todas as suas perguntas. Entre em contato e inicie um diálogo com a Iron para aproveitar ao máximo nossa biblioteca em seu projeto.
Faça uma pergunta
Basta escrever uma única classe web scraper em C# para extrair milhares ou até milhões de páginas da web e armazená-las em instâncias de classes C#, JSON ou arquivos baixados. O IronWebScraper permite que você crie fluxos de trabalho concisos e lineares, simulando o comportamento de navegação humana. O IronWebScraper executará seu código como um enxame de navegadores web virtuais, massivamente paralelos, porém educados e tolerantes a falhas.
Comece a usar a documentação.
O IronWebScraper precisa ser programado para saber como lidar com cada "tipo" de página que encontrar. Isso é feito de forma concisa usando seletores CSS ou expressões XPath e pode ser totalmente personalizado em C#. Essa liberdade permite que você decida quais páginas extrair de um site e o que fazer com os dados coletados. Cada método pode ser depurado e monitorado detalhadamente no Visual Studio.
Siga um tutorial
O IronWebScraper lida com multithreading e requisições web para permitir centenas de threads simultâneas sem que o desenvolvedor precise gerenciá-las. O nível de cortesia (politeness) pode ser configurado para limitar o número de requisições, reduzindo assim o risco de sobrecarga nos servidores web de destino.
Começando a usar o WebScraper
O IronWebScraper pode usar uma ou múltiplas "identidades" — sessões que simulam requisições humanas reais. Cada requisição pode ter sua própria identidade, agente de usuário, cookies, logins e até mesmo endereços IP atribuídos programaticamente ou aleatoriamente. As requisições são definidas como auto-únicas por meio de uma combinação de URL, método de análise e variáveis POST.
See API Reference
O IronWebScraper utiliza um sistema avançado de cache para permitir que os desenvolvedores alterem seu código "em tempo real" e reproduzam cada solicitação anterior sem precisar acessar a internet. Cada tarefa de coleta de dados é salva automaticamente e pode ser retomada em caso de exceção ou queda de energia.
Instruções de configuração do WebScraper
O IronWebScraper coloca as ferramentas de Web Scraping em suas mãos rapidamente com um instalador para Visual Studio. Seja instalando diretamente do NuGet dentro do Visual Studio ou baixando a DLL, você estará pronto em instantes. Apenas uma DLL e nenhuma dependência.
PM > Instalar pacote IronWebScraper Baixar DLL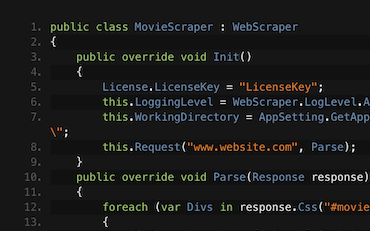
VB C# ASP.NET
Veja como Ahmed usa o IronWebScraper em seus projetos para migrar conteúdo de um site para outro. Exemplos de projetos e código são fornecidos para extrair conteúdo de sites de e-commerce e blogs.
 Veja o tutorial de web scraping do Ahmed.
Veja o tutorial de web scraping do Ahmed.





A equipe da Iron possui mais de 10 anos de experiência no mercado de componentes de software .NET.

Quer provas rápidas? PM > Install-Package IronWebScraper
executar um exemplo Observe como seu site alvo se transforma em dados estruturados.
Install-Package IronWebScraper

Não é necessário cartão de crédito.
Sua chave de avaliação deve estar no e-mail.![]() O formulário de inscrição para o teste foi enviado.
O formulário de inscrição para o teste foi enviado.
Com sucesso .
Caso contrário, entre em contato.
support@ironsoftware.com
Não é necessário cartão de crédito.
Teste em produção sem marcas d'água.
Funciona onde você precisar.
Receba 30 dias de produto totalmente funcional.
Deixe-o pronto para usar em minutos.
Acesso total à nossa equipe de suporte técnico durante o período de teste do produto.
Uma demonstração ao vivo do nosso produto e suas principais funcionalidades.
Receba recomendações de funcionalidades específicas para o seu projeto.
Todas as suas dúvidas serão respondidas para garantir que você tenha todas as informações necessárias. (Sem qualquer compromisso.)





Agende uma consulta sem compromisso.

Preencha o formulário abaixo ou envie um e-mail para sales@ironsoftware.com
Os seus dados serão sempre mantidos em sigilo.

Agende uma demonstração personalizada de 30 minutos.
Sem contrato, sem necessidade de dados de cartão, sem compromissos.


