



Canlı bir ortamda test edin
Üretim ortamında su yas cızlar olmadan test edin.
İhtiyacınız olan her yerde çalışır.

using IronOcr;
string imageText = new IronTesseract().Read(@"images\image.png").Text;Imports IronOcr
Private imageText As String = (New IronTesseract()).Read("images\image.png").TextInstall-Package IronOcr
IronOCR, kusurlu taranmış görüntülerden ve PDF belgelerinden metni otomatik olarak algılama ve okuma yeteneği ile benzersizdir. IronTesseract sınıfı, en basit API'yi sağlar.
C# OCR işlemlerinizin ince ayarlı kontrolünü elde etmek için diğer kod örneklerini deneyin.
IronOCR, her platformda bilinen, artırılmış hız, doğruluk, yerel DLL ve API ile her yerde Tesseract'un en gelişmiş yapısını sunar.
.NET Framework, Standard, Core, Xamarin ve Mono için Tesseract 3, Tesseract 4 ve Tesseract 5'i destekler.
IronTesseract başlatınRead yöntemini kullanarak VB.NET içinde OCR gerçekleştirinText özelliğine erişerek alınusing IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR, 125 uluslararası dili destekler. Varsayılan olarak yüklü olan İngilizce'nin yanı sıra, ek dil paketleri NuGet üzerinden veya Diller Sayfamızdan indirilebilir ve .NET projenize eklenebilir. Çoğu dil, IronOCR Dil Desteği
Fast, Standard (önerilen) ve Best kalitesinde mevcuttur. Best kalite seçeneği daha doğru sonuçlar sunabilir, ancak işlem süresi daha yavaş olacaktır.
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
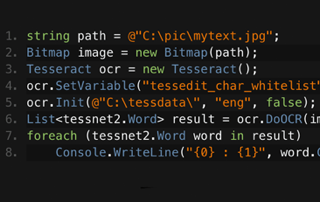
IronOCR, her taradığı sayfa için gelişmiş bir sonuç nesnesi döndürür Tesseract 5. Bu, her biri için konum verileri, görüntüler, metin, istatistiksel güven, alternatif sembol seçenekleri, yazı tipi adları, yazı tipi boyutları, süsleme, yazı ağırlıkları ve konum içerir.
PageParagraphWordBarcode
Ürün, entegrasyon veya lisanslama soruları olsun; Iron ürün geliştirme ekibi tüm sorularınızı desteklemek için hazır. Projenizde kütüphanemizin en iyi şekilde kullanılmasını sağlamak için iletişime geçin ve Iron ile bir diyalog başlatın.
Soru Sor
IronOCR (Optik Karakter Tanıma) kütüphanesi geliştiricilere, görüntüleri metne dönüştürürken hızlı ve etkili sonuçlar sağlar. IronOCR .NET, VB.NET ve C# ile çalışır. Özel olarak sizin — geliştirici için en iyi performansı elde etmenizi destekleyecek şekilde dizayn edilmiş .NET framework'leri için en üst düzey uygulamalardır.
OCR, metin dosyalarını, barkodları, QR içeriklerini ve daha fazlasını alır ve tanır. Ancak IronOCR ayrıca web, windows masaüstü veya konsol .NET projelerine sonsuz profesyonellikte görüntü formatları ve dosyaları, JPG, PNG, GIF, TIFF, BMP, JPEG veya PDF dahil olacak şekilde OCR okuma ve metin eklemenize olanak tanıyan birçok yöntem sağlar.
Görüntü çıktılarından düz metin, karakterler, satırlar ve paragrafların tanıma sonuçları zahmetsiz görünmeyebilir, ancak IronOCR'nin kaput altında sonuçlarının gerçekte düşündüğünüzden kolay olduğunu göreceksiniz. IronOCR, hizalamalar için görüntüyü tarar, gürültü giderme ve filtresi ile kalitesi ve çözünürlüğü kontrol eder. Özelliklerine bakar, OCR motorunu optimize eder ve ardından (görüntülerden) metin tanımayla eğitimli yapay zeka ağı kullanır, ayrıca her insan gibi metni tanır.
Bilgisayarlar için bile OCR basit bir süreç değildir ancak IronOCR, aranabilir belgeler oluşturmayı daha hızlı ve daha basit hale getirir, %100 doğruluk ve minimal kod satırı ile.
İle Çalışır UI Framework, VB.NET, Avalonia
Eğitimi Oku
Yazılım, coğrafi sınırlara bağlı değildir — işletmeler sınır ötesinde işler ve sonuçlarını almak için birden fazla dile güvenirler. Benzer şekilde, sadece tek bir dilde belge tanıyan bir optik karakter okuma (OCR) aracı, her açıdan büyük bir HAYIR'dır!
Çok sayıda OCR işlevi sunan çokdilli bir OCR kütüphanesi ile, bir taranmış PDF veya taranmış görüntüden birden fazla dili (Fransızcadan Çinceye kadar!) aranabilir bir PDF belgesi oluşturmanın avantajlarını elde edersiniz. Zaman ve çabanız, dinamik, kelime aranabilir bir PDF belgeyle kolaylaştırılmış olur, siz, müşterileriniz veya kuruluşunuz tarafından sınırsız şekilde kullanılabilir ve yeniden kullanılabilir.
Sizin, işiniz ve OCR ihtiyaçlarınız, yerleşik olarak veya talep üzerine odaklanarak IronOCR kütüphanesi geniş bir dil yelpazesi sunar. Sonraki .NET projeniz dil uyumluluğu endişelerinden muaf olabilir!
İster Arapça, İspanyolca, Fransızca, Almanca, İbranice, İtalyanca, Japonca, Basitleştirilmiş Çince, Geleneksel Çince (Mandarin), Danca, İngilizce, Fince, Portekizce, Rusça, İspanyolca veya İsveççe olsun, dilleri isimlendirirsiniz ve biz onları size sağlıyoruz! Tercih ettiğiniz dil paketlerini indirebilir veya daha fazla dil için 7/24 destek ekibimize başvurabilirsiniz.
İlk adım, Windows Visual Studio için NuGet paket kurulumunu kullanmaktır.
Dil Paketlerini İndir
IronOCR'un rakiplerinden farkı nedir? OCR işlevlerini kolayca eklemenizin yanı sıra, metin çıkarmanız ve döndürülmüş görüntüleri taramanızdan başka, kusurlu taramalardan da OCR yapabilme yeteneğine sahiptir! Aksine, bugün piyasadaki çeşitli kullanıma hazır ürünlerin çoğu katı ve yanlış olup, makinelerle yazdırılmış, yüksek çözünürlükte ve mükemmel ayarlanmış metinlerle çalışırken gerçek dünya bireysel ve kurumsal uygulamalarında başarısız olacak şekilde tasarlandılar.
Google Tesseract nedeniyle IronTesseract DLL ile güçlü - yerel C# OCR kütüphanesi daha fazla kararlılık ve Tesseract özgür kütüphaneden daha kesin olacak şekilde yeteneklerini genişletiyor.
Yolun tuttuğunuz en iyi araçlarla, mükemmel olmayan taranmış bir görüntünüz olsa da veya saklama klasörünüzde saklı bir görüntü olsa dahi IronOCR'un görüntü işleme kütüphanesi dönüşümü, gürültüyü temizler, döndürür, bozulmayı ve eğik hizalamayı azaltır ve çözünürlük ve kontrastı artırır. Gelişmiş Optik Karakter Tanıma (OCR) ayarları, kodlayıcılar için — kodlama ve kodu — mevcut mümkün olan en iyi aranabilir sonuçları elde etmenize olanak tanır, kere kere.
İhtiyacınız olan kelimeleri arayın ve %99.8-100 kesin sonuçlar, PDF Belgeleri, çok kareli TIFF dosyaları, JPEG & JPEG2000, GIF, PNG, BMP, WBMP, System.Drawing.Image, System.Drawing.Bitmap, System.IO.Streams görüntüleri ve ikili görüntü verileri (bayt[]) ve her şey ötesinde olanlarla asla hayal kırıklığına uğrayamazsınız!
Tesseract için Alternatif
.NET framework'de diğer .NET uygulamalarından farklı olarak, IronOCR'un paket yöneticisi konsolu ve tanınan metin konsolu içindeki gelişmiş Optik Karakter Tanıma, kullanıcılarınıza çeşitli kelime yazı tipleri (Times New Roman'dan herhangi bir zamansız veya anlaşılması zor olan) okuma, ağırlıkları ve stilleri doğrulukla metin okuma yeteneği verir. Bir görüntünün belirli alanlarını seçme yeteneğimiz hız ve doğruluğu artırır. Çok iş parçacığından bir kaç satırdan birkaç paragrafa spor ile çalışmayı hızlandırır ve çok çekirdekli makinelerde birden fazla belge okumasına olanak tanır.
Hız ve doğruluk iddiaları, karakter tanıma sürecine sınırlı kalmaz. IronOCR'un .NET OCR motorunun kullanımı kolay, tam ve iyi belgelenmiş .NET yazılım kütüphanesi olarak kurulum noktasından itibaren iyileştirmeler başlamaktadır. Visual Studio için tek bir NuGet paket yöneticisi kurulumu ve MVC, WebApp, Masaüstü, Konsol ve Sunucu Uygulamaları ile çok iş parçacığı uyumluluğu sağlanır.
%99,8-100 OCR doğruluğu, herhangi bir harici web hizmeti, sürekli ücret, ya da gizli belgeleri internete gönderme gereksinimi olmadan elde edilebilir. Külfetli C++ kodlamadan, IronOCR, tam PDF OCR desteği için birden fazla karakter, kelime, satır, paragraf, metin ve belge isteğiniz geldiğinde yapılacak bariz bir seçimdir.
Kodlamalarını mükemmel bir şekilde yapmaya çalışan geliştiricilere en iyi seçenekleri sunuyoruz; IronOCR performans ayarlamaya ya da giriş görüntüleri üzerinde çok fazla düzenleme yapmaya gerek kalmadan doğrudan kutudan çıkar. En son IronOCR sürümü, on kat daha hızlı çalışır ve önceki yapılardan %250 daha az hata yapar. Kendi yapılarımızı, OCR için mükemmel platformu sağlayarak hedeflerinizi desteklemek için güncelliyoruz!
Tüm İşlev Listesini Gör
Mobil cihazlar kullanırken bile, mükemmel .NET OCR kütüphanemiz, IronOCR'un eksiksiz ve karmaşık metinler gibi içeriği basit bir dizi halinde sorunsuz kodlamanıza olanak tanır, makine kodu metin, barkod verileri veya yapılandırılmış nesne model verileriyle birlikte geliştiricilere 'sorunsuz kodlama' şansı verir. İçerik paragraflarını, satırları, kelimeleri, karakterleri ve görüntü dizesi sonuçlarını doğrudan .NET uygulamalarınıza, bölerek kullanabilirsiniz.
Kaynak koddan sonuca — sonucunda elde edilen veri, uygulamanıza aktaramadığınız sürece yararsız olurdu. IronOCR bunu anlar ve OCR sonucunu XHTML'e dışa aktararak, daha geniş bir yelpaze ölçeğinde sürdürülebilir bir formatla çalışmanıza ve karmaşık web sitelerine entegre etmenize olanak tanır, hızlı yükleme sürelerini de dahil!
Ancak destek burada bitmiyor. OCR'nin aranabilir PDF belgelere dışa aktarım yeteneği, sizin, müşterileriniz ve kuruluşların ihtiyaç duyulduğunda PDF belgelerini saklamalarını ve alıp kullanmalarını kolaylaştırır! Veritabanınızda birkaç anahtar kelime ile arayabileceğiniz 30 sayfalık bir sözleşme olduğunda özellikle yararlıdır ve ayrıca, aranabilir PDF belgelerin görme engelliler için faydalı olduğu kanıtlanmıştır, şirketinizi uyumlu gösterme seçeneğini de sağlar.
Yukarıdakilere ek olarak, OCR çıktınızı temsil eden, düzen bilgileri ve stil bilgisi taşıyan ve standart HTML içine gömülen OCR formatına sonuçlarınızı dışa aktarabilirsiniz.
Daha Fazla Bilgi EdininÜcretsiz topluluk geliştirme lisansları. Ticari lisanslar 749 $'dan başlayan fiyatlarla.





Avalonia Tesseract OCR

Jim, IronOCR'un geliştirilmesinde önde gelen bir figür olmuştur. Jim, OCR için görüntü işleme algoritmaları ve okuma yöntemleri tasarlamakta ve geliştirmektedir.
Karşılaştırmayı Gör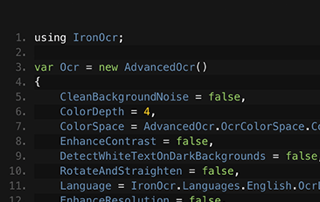
Avalonia OCR ASP.NET

Gemma'nın ekibinin, arşivleme yazılımları için görüntülerden metin okumak amacıyla IronOCR kullandığını öğrenin. Gemma, kendi kod örneklerini paylaşıyor.
Resimden Metne .NET Eğitim




Team Iron .NET yazılım bileşenleri pazarında 10 yılı aşkın deneyime sahiptir.








Install-Package IronOcr

Kredi kartı gerekmez
Deneme anahtarınız e-postada olmalıdır.![]() Deneme formu
Deneme formu
başarıyla gönderildi.
Değilse, lütfen iletişime geçin
support@ironsoftware.com
Kredi kartı gerekmez
Üretim ortamında su yas cızlar olmadan test edin.
İhtiyacınız olan her yerde çalışır.
30 gün boyunca tam işlevli ürün alın.
Dakikalar içinde çalışır hale getirin.
Ürün deneme sürecinizde destek mühendislik ekibimize tam erişim
Ürünümüzün canlı bir demosu ve ana özellikleri
Projeye özel özellik önerileri alın
Tüm sorularınız yanıtlandı, böylece ihtiyacınız olan tüm bilgilere sahipsiniz. (Herhangi bir taahhüt yok.)





Herhangi bir sınırlama yoktur. %100 erişim. Kredi kartı gerekmez.
Bağımsız Danışma Rezervasyonu

Aşağıdaki formu doldurun veya sales@ironsoftware.com adresine e-posta gönderin
Bilgileriniz daima gizli kalacaktır.

30 dakikalık, kişisel bir demo alın.
Sözleşme yok, kart bilgileri yok, taahhüt yok.


