



Teste em um ambiente real
Teste em produção sem marcas d'água.
Funciona onde você precisar.

using IronOcr;
string imageText = new IronTesseract().Read(@"images\image.png").Text;Imports IronOcr
Private imageText As String = (New IronTesseract()).Read("images\image.png").TextInstall-Package IronOcr
IronOCR é único em sua capacidade de detectar e ler automaticamente texto de imagens e documentos PDF escaneados imperfeitamente. A classe IronTesseract fornece a API mais simples.
Experimente outros exemplos de código para obter controle fino de suas operações de OCR em C#.
IronOCR fornece a construção mais avançada de Tesseract conhecida em qualquer lugar, em qualquer plataforma, com maior velocidade, precisão e um DLL e API nativos.
Supports Tesseract 3, Tesseract 4, and Tesseract 5 for .NET Framework, Standard, Core, Xamarin, and Mono.
IronTesseract para usar APIs intuitivasRead para realizar OCR em VB.NETTextusing IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
O IronOCR suporta 125 idiomas internacionais. Além do inglês, que é instalado por padrão, pacotes de idiomas adicionais podem ser adicionados ao seu projeto .NET via NuGet ou baixados da nossa página de idiomas . A maioria dos idiomas está disponível em qualidade Suporte a idiomas do IronOCR
Fast, Standard (recomendado) e Best. A opção de qualidade Best pode oferecer resultados mais precisos, mas também será mais lenta no tempo de processamento.
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR retorna um objeto de resultado avançado para cada página que escaneia usando Tesseract 5. Isso contém dados de localização, imagens, texto, confiança estatística, escolhas de símbolos alternativos, nomes de fonte, tamanhos de fonte, decoração, pesos de fonte e posição para cada:
PageParagraphWordBarcode
Seja para dúvidas sobre produtos, integração ou licenciamento, a equipe de desenvolvimento de produtos da Iron está à disposição para ajudar com todas as suas perguntas. Entre em contato e inicie um diálogo com a Iron para aproveitar ao máximo nossa biblioteca em seu projeto.
Faça uma pergunta
A biblioteca IronOCR (Reconhecimento Óptico de Caracteres) permite que os desenvolvedores obtenham resultados rápidos e eficientes na conversão de imagens em texto. O IronOCR funciona com .NET, VB.NET e C#. Nossos principais aplicativos .NET para frameworks .NET são projetados especificamente para você, desenvolvedor, para ajudá-lo a alcançar o desempenho ideal em seus projetos.
O OCR recebe e reconhece arquivos de texto, códigos de barras, conteúdo de QR Code e muito mais. No entanto, o IronOCR também oferece diversos métodos que permitem adicionar leitura de OCR e texto a partir de imagens em projetos .NET para web, desktop Windows ou console, com suporte para uma gama praticamente ilimitada de formatos e arquivos de imagem, como JPG, PNG, GIF, TIFF, BMP, JPEG ou PDF.
Embora os resultados do reconhecimento de texto simples, caracteres, linhas e parágrafos a partir de imagens possam não parecer óbvios à primeira vista, você descobrirá que o funcionamento interno do IronOCR é, na verdade, mais simples do que você imaginava. O IronOCR escaneia a imagem para alinhamento, utiliza sua ferramenta de remoção de ruído e filtros para verificar a qualidade e a resolução. Ele analisa suas propriedades, otimiza o mecanismo de OCR e usa uma rede de inteligência artificial treinada para, então, reconhecer o texto (a partir de imagens) tão bem quanto um ser humano.
O reconhecimento óptico de caracteres (OCR) não é um processo simples, nem mesmo para um computador. No entanto, o IronOCR torna todo o processo de criação de documentos pesquisáveis mais rápido e direto, com 100% de precisão e um mínimo de linhas de código.
Leia o tutorial
O software não se limita a fronteiras geográficas — as empresas operam além-fronteiras e dependem de vários idiomas para alcançar seus resultados. Da mesma forma, uma ferramenta de reconhecimento óptico de caracteres (OCR) que realiza o reconhecimento de documentos em apenas um idioma é um grande NÃO em todos os sentidos!
Com uma biblioteca OCR multilíngue que oferece diversas funcionalidades de OCR, você se beneficia da criação de um documento PDF pesquisável a partir de um PDF ou imagem digitalizada em vários idiomas (do francês ao chinês!). Seu tempo e esforço são otimizados com um documento PDF dinâmico e pesquisável por palavras, que você, seus clientes ou sua organização podem usar e reutilizar sem limites.
Com foco em você, no seu negócio e nas suas necessidades de OCR, seja com recursos integrados ou sob demanda, a biblioteca IronOCR oferece suporte a uma ampla variedade de linguagens. Seu próximo projeto .NET estará livre de preocupações com compatibilidade de idiomas!
Seja árabe, espanhol, francês, alemão, hebraico, italiano, japonês, chinês simplificado, chinês tradicional (mandarim), dinamarquês, inglês, finlandês, português, russo, espanhol ou sueco, basta especificar os idiomas e nós os fornecemos! Você pode baixar os pacotes de idiomas de sua preferência ou entrar em contato com nosso suporte 24 horas por dia, 7 dias por semana, para obter mais idiomas.
O primeiro passo é usar nosso instalador de pacotes NuGet para Windows Visual Studio.
Baixar pacotes de idiomas
Como o IronOCR se diferencia de seus concorrentes? Além de permitir que você adicione facilmente funcionalidades de OCR, extraia texto e digitalize imagens rotacionadas, ele também tem a capacidade de realizar OCR a partir de digitalizações imperfeitas! Em contraste, muitos dos diversos produtos prontos para uso disponíveis no mercado atualmente são frequentemente rígidos e imprecisos, fadados ao fracasso em aplicações reais, sejam elas individuais ou corporativas, já que a maioria deles trabalha com texto impresso em alta resolução e perfeitamente alinhado.
O IronOCR amplia as capacidades do Google Tesseract com sua poderosa DLL IronTesseract — uma biblioteca OCR nativa em C# com estabilidade aprimorada e maior precisão do que a biblioteca gratuita Tesseract.
Com a melhor ferramenta em mãos, mesmo que você tenha uma imagem digitalizada com qualidade inferior ou uma imagem armazenada em sua pasta, a conversão da biblioteca de processamento de imagens do IronOCR remove ruídos, rotaciona, reduz distorções e desalinhamentos, além de melhorar a resolução e o contraste. As configurações avançadas de Reconhecimento Óptico de Caracteres (OCR) fornecem a você — o programador — as ferramentas e o código para gerar os melhores resultados de busca possíveis, sempre.
Pesquise as palavras que você precisa e nunca se decepcione com os resultados de 99,8 a 100% de precisão e o suporte ilimitado para documentos PDF, arquivos TIFF multiframe, JPEG e JPEG2000, GIF, PNG, BMP, WBMP, System.Drawing.Image, System.Drawing.Bitmap, System.IO.Streams de imagens, dados binários de imagem (byte[]) e muito mais!
Uma alternativa ao Tesseract
Ao contrário de outros aplicativos .NET no framework .NET, você descobrirá que o Reconhecimento Óptico de Caracteres (OCR) avançado, presente no console do gerenciador de pacotes e no console de texto reconhecido do IronOCR, permite que seus usuários leiam diversas fontes (de Times New Roman a qualquer fonte sofisticada ou supostamente difícil de entender), pesos e estilos para uma leitura precisa de texto em imagens inteiras ou digitalizadas. Nossa capacidade de selecionar áreas específicas de uma imagem ajuda a melhorar a velocidade e a precisão. O processamento multithread, de algumas linhas a alguns parágrafos, acelera o mecanismo de OCR e permite a leitura de vários documentos em máquinas com múltiplos núcleos.
Nossas alegações de velocidade e precisão não se limitam ao processo de reconhecimento de caracteres. Na verdade, as melhorias começam já na instalação, pois o mecanismo OCR .NET do IronOCR é uma biblioteca de software .NET completa, bem documentada e fácil de instalar. Há uma única instalação via gerenciador de pacotes NuGet para o Visual Studio, além de compatibilidade com multithreading em aplicações MVC, WebApp, Desktop, Console e Servidor.
Você pode alcançar uma precisão de OCR de 99,8 a 100% sem serviços web externos, taxas recorrentes ou a necessidade de enviar documentos confidenciais pela internet. Sem a complexidade da programação em C++, o IronOCR é a escolha ideal quando você precisa de suporte completo para OCR em PDFs, abrangendo múltiplos caracteres, palavras, linhas, parágrafos, textos e documentos.
Oferecemos as melhores opções para desenvolvedores que buscam aperfeiçoar sua programação, pois o IronOCR funciona imediatamente, sem necessidade de ajustes de desempenho ou modificações significativas nas imagens de entrada. A versão mais recente do IronOCR é incrivelmente rápida — até dez vezes mais rápida e com mais de 250% menos erros do que as versões anteriores. Atualizamos nossas próprias versões para atender aos seus objetivos, fornecendo a plataforma perfeita para OCR!
Veja a lista completa de funções.
Mesmo em dispositivos móveis, nossa biblioteca OCR .NET perfeita permite que os desenvolvedores programem sem preocupações, pois o IronOCR suporta a exportação de conteúdo como um conjunto simples de texto direto e complexo, texto codificado por máquina, dados de código de barras ou dados de modelo de objeto estruturado. Você pode dividir o conteúdo em parágrafos, linhas, palavras, caracteres e resultados de strings de imagem para uso direto em seus aplicativos .NET.
Do código-fonte ao resultado final, os dados gerados seriam inúteis se você não pudesse exportá-los para sua aplicação. O IronOCR entende isso e permite exportar o resultado do OCR para XHTML, possibilitando o trabalho com um formato consistente em uma ampla gama de aplicações e a integração com sites complexos, além de tempos de carregamento mais rápidos!
No entanto, o suporte não termina aí. A capacidade de exportar OCR para documentos PDF pesquisáveis facilita o armazenamento e a recuperação de documentos PDF sempre que necessário, tanto para você quanto para seus clientes e organizações! Isso é especialmente vantajoso quando você tem um contrato de 30 páginas que pode ser encontrado em seu banco de dados com algumas palavras-chave, além de permitir que sua empresa demonstre conformidade com as normas, visto que documentos PDF pesquisáveis são comprovadamente benéficos para pessoas com deficiência visual.
Além do exposto acima, você pode exportar seus resultados para o formato OCR que representa a saída do OCR, informações de layout e estilo, e incorporar as informações relacionadas em HTML padrão.
Saber maisLicenças gratuitas para desenvolvimento comunitário. Licenças comerciais a partir de US$ 749.





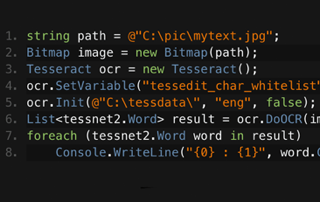
C# Tesseract OCR

Jim tem sido uma figura fundamental no desenvolvimento do IronOCR. Ele projeta e constrói algoritmos de processamento de imagem e métodos de leitura para OCR.
Veja a comparação.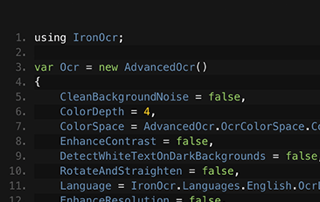
C# OCR ASP.NET

Aprenda como a equipe de Gemma usa o IronOCR para ler texto de imagens para seu software de arquivamento. Gemma compartilha seus próprios exemplos de código.
Tutorial .NET de conversão de imagem em texto




A equipe da Iron possui mais de 10 anos de experiência no mercado de componentes de software .NET.








Install-Package IronOcr

Não é necessário cartão de crédito.
Sua chave de avaliação deve estar no e-mail.![]() O formulário de inscrição para o teste foi enviado.
O formulário de inscrição para o teste foi enviado.
Com sucesso .
Caso contrário, entre em contato.
support@ironsoftware.com
Não é necessário cartão de crédito.
Teste em produção sem marcas d'água.
Funciona onde você precisar.
Receba 30 dias de produto totalmente funcional.
Deixe-o pronto para usar em minutos.
Acesso total à nossa equipe de suporte técnico durante o período de teste do produto.
Uma demonstração ao vivo do nosso produto e suas principais funcionalidades.
Receba recomendações de funcionalidades específicas para o seu projeto.
Todas as suas dúvidas serão respondidas para garantir que você tenha todas as informações necessárias. (Sem qualquer compromisso.)





Agende uma consulta sem compromisso.

Preencha o formulário abaixo ou envie um e-mail para sales@ironsoftware.com
Os seus dados serão sempre mantidos em sigilo.

Agende uma demonstração personalizada de 30 minutos.
Sem contrato, sem necessidade de dados de cartão, sem compromissos.


