



Testez dans un environnement en direct
Testez en production sans filigranes.
Fonctionne où que vous en ayez besoin.

using IronOcr;
string imageText = new IronTesseract().Read(@"images\image.png").Text;Imports IronOcr
Private imageText As String = (New IronTesseract()).Read("images\image.png").TextInstall-Package IronOcr
IronOCR est unique par sa capacité à détecter et lire automatiquement le texte d'images et de documents PDF scannés imparfaitement. La classe IronTesseract offre l'API la plus simple.
Essayez d'autres exemples de code pour obtenir un contrôle plus précis de vos opérations OCR en C#.
IronOCR fournit la construction la plus avancée de Tesseract connue partout, sur n'importe quelle plateforme, avec une vitesse accrue, une précision, et une DLL native et une API.
Prend en charge Tesseract 3, Tesseract 4, et Tesseract 5 for .NET Framework, Standard, Core, Xamarin et Mono.
IronTesseract pour utiliser des API intuitives.Read pour effectuer une reconnaissance optique de caractères (OCR) en VB.NET.Textusing IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR prend en charge 125 langues internationales. Outre l'anglais, installé par défaut, des modules linguistiques supplémentaires peuvent être ajoutés à votre projet .NET via NuGet ou téléchargés depuis notre page Langues . La plupart des langues sont disponibles en Explorez la reconnaissance optique de caractères (OCR) en plusieurs langues avec IronOCR.Prise en charge linguistique d'IronOCR
Fast, Standard (recommandé), et Best qualité. L'option de qualité Best peut offrir des résultats plus précis, mais sera également plus lente en temps de traitement.
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR retourne un objet résultat avancé pour chaque page qu'il balaie en utilisant Tesseract 5. Cela contient des données de localisation, des images, du texte, la confiance statistique, des choix de symboles alternatifs, des noms de polices, des tailles de polices, des décorations, des poids de polices, et des positions pour chacun :
PageParagraphWordBarcodeDécouvrez comment lire les résultats de la reconnaissance optique de caractères (OCR) avec IronOCR.

Que ce soit pour des questions sur le produit, l'intégration ou les licences, l'équipe de développement de produits Iron est à disposition pour répondre à toutes vos questions. Prenez contact et démarrez un dialogue avec Iron pour tirer le meilleur parti de notre bibliothèque dans votre projet.
Poser une question
La bibliothèque IronOCR (Reconnaissance Optique de Caractères) permet aux développeurs d’obtenir des résultats rapides et efficaces lors de la conversion d’images en texte. IronOCR fonctionne avec .NET, VB .NET et C#. Nos meilleures applications .NET pour les frameworks .NET sont spécialement conçues pour vous — le développeur, pour vous soutenir dans l’atteinte d’une performance optimale pour vos projets.
OCR reçoit et reconnaît des fichiers texte, codes-barres, contenu QR, et plus encore. Cependant, IronOCR offre également de nombreuses méthodes permettant d’ajouter des capacités de lecture OCR et de texte à partir d’images dans des projets web, de bureau Windows, ou de console .NET avec un support pour des formats d’images et de fichiers virtuellement illimités, tels que JPG, PNG, GIF, TIFF, BMP, JPEG ou PDF.
Bien que les résultats de reconnaissance de texte brut, de caractères, de lignes et de paragraphes à partir des images en sortie puissent ne pas paraître simples, vous découvrirez qu’en fait, sous le capot d’IronOCR, les résultats sont plus simples que vous ne l’auriez initialement pensé. IronOCR scanne l’image pour l’alignement, utilise sa réduction de bruit et ses filtres pour vérifier la qualité et la résolution. Il examine ses propriétés, optimise le moteur OCR, et utilise un réseau d’intelligence artificielle formé pour ensuite reconnaître le texte (à partir d’images) tout aussi bien qu’un humain.
OCR n’est pas un processus simple, même pour un ordinateur. Cependant, IronOCR rend le processus global de création de documents interrogeables plus rapide et plus facile, avec 100% de précision et un nombre minimal de lignes de code.
Fonctionne avec .NET, VB.NET, C#
Lire le Tutoriel
Les logiciels ne sont pas limités par des frontières géographiques — les entreprises fonctionnent au-delà des frontières et comptent sur plusieurs langues pour atteindre leurs résultats. De même, un outil de reconnaissance optique de caractères (OCR) qui ne réalise la reconnaissance de documents que dans une seule langue est un grand NON à tous égards !
Avec une bibliothèque OCR multilingue qui offre de multiples fonctionnalités OCR, vous bénéficiez de la création d’un document PDF interrogeable à partir d’un PDF scanné ou d’une image scannée dans plusieurs langues (du français au chinois !). Votre temps et vos efforts sont rationalisés avec un document PDF dynamique, qu'il soit interrogeable par mot et que vous, vos clients ou votre organisation pouvez utiliser et réutiliser sans limites.
Avec un fort accent sur vous, votre entreprise, et vos besoins en OCR, que ce soit en intégré ou sur demande, la bibliothèque IronOCR dispose d'une vaste gamme de langues prises en charge. Votre prochain projet .NET peut être exempt de soucis de compatibilité linguistique !
Que ce soit l’arabe, l’espagnol, le français, l’allemand, l’hébreu, l’italien, le japonais, le chinois simplifié, le chinois traditionnel (mandarin), le danois, l’anglais, le finnois, le portugais, le russe, l’espagnol ou le suédois, vous nommez simplement les langues et nous vous les fournissons ! Vous pouvez télécharger vos packs linguistiques préférés ou contacter notre support 24/7 pour plus de langues.
La première étape consiste à utiliser notre installateur de paquet NuGet pour Windows Visual Studio.
Télécharger les Packs Linguistiques
Comment IronOCR se différencie-t-il de ses concurrents ? En plus de vous permettre d’ajouter facilement des fonctionnalités OCR, d’extraire du texte et de scanner des images tournées, il a également la capacité d'effectuer un OCR à partir de scans imparfaits ! Par contre, de nombreux produits prêts à l'emploi sur le marché aujourd'hui sont souvent rigides et inexacts, voués à l'échec dans des applications individuelles et d'entreprise réelles, car la majorité d'entre eux fonctionnent avec du texte imprimé par machine, haute résolution et parfaitement ajusté.
IronOCR étend les capacités de Google Tesseract avec sa puissante DLL IronTesseract — une bibliothèque OCR native C# avec une stabilité améliorée et une précision plus élevée que la bibliothèque Tesseract gratuite.
Avec le meilleur outil entre vos mains, même si vous avez une image scannée moins que parfaite ou une image stockée dans votre dossier de stockage — la conversion de la bibliothèque de traitement d'image d'IronOCR nettoie le bruit, tourne, réduit la distorsion et l'alignement biaisé, et améliore la résolution et le contraste. Les paramètres de Reconnaissance Optique de Caractères (OCR) avancés vous donnent — aux codeurs — les outils et le code pour générer les meilleurs résultats interrogeables possibles, encore et encore.
Recherchez les mots dont vous avez besoin et ne soyez jamais déçu avec des résultats précis de 99,8 à 100% et le support illimité pour les documents PDF, fichiers TIFF multi-images, JPEG & JPEG2000, GIF, PNG, BMP, WBMP, System.Drawing.Image, System.Drawing.Bitmap, System.IO.Streams d'images, données d'image binaires (byte[]), et tout le reste !
Une Alternative à Tesseract
Contrairement à d'autres applications .NET dans le framework .NET, vous constaterez que la Reconnaissance Optique de Caractères avancée, dans la console de gestion de paquet d'IronOCR et la console de texte reconnu, donne à vos utilisateurs la capacité de lire plusieurs polices (de Times New Roman à tout ce qui est sophistiqué ou supposément difficile à comprendre), poids, et styles pour une lecture précise du texte à partir d'une image entière ou d’images scannées. Notre capacité à sélectionner certaines zones d'une image aide à améliorer la rapidité et la précision. Le multithreading d'un certain nombre de lignes à quelques paragraphes accélère le moteur OCR et permet la lecture de plusieurs documents sur des machines multicœurs.
Nos prétentions à la rapidité et à la précision ne se limitent pas au processus de reconnaissance de caractères. Au contraire, les améliorations commencent dès le moment de l'installation car le moteur OCR .NET d'IronOCR est une bibliothèque logicielle complète, facile à installer, et bien documentée en .NET. Il y a une seule installation de gestionnaire de paquet NuGet pour Visual Studio, et une compatibilité multithreading avec MVC, applications WebApp, Bureau, Console, et Serveur.
Vous pouvez atteindre une précision OCR de 99,8 à 100% sans aucun service web externe, frais continus, ou devoir envoyer des documents confidentiels via Internet. Sans le codage C++ encombrant, IronOCR est le choix évident à faire lorsqu'il s'agit de bénéficier d’un support OCR complet pour PDF pour plusieurs caractères, mots, lignes, paragraphes, texte et documents.
Nous offrons les meilleures options pour les développeurs cherchant à perfectionner leur code, car IronOCR fonctionne directement sans besoin d'optimisation de performance ou de modifier lourdement les images d'entrée. La dernière version d'IronOCR fonctionne étonnamment vite — jusqu'à dix fois plus rapide, et fait plus de 250% moins d'erreurs que les versions précédentes. Nous mettons à niveau nos propres builds pour soutenir vos objectifs en fournissant la plateforme parfaite pour l'OCR!
Voir la liste complète des fonctionnalités
Même en utilisant des appareils mobiles, notre bibliothèque .NET OCR parfaite permet aux développeurs de coder 'sans soucis' car IronOCR permet d'exporter du contenu sous forme d'ensemble simple de texte clair et complexe, de texte encodé par machine, de données de code-barres, ou de données de modèle d'objet structuré. Vous pouvez diviser les paragraphes de contenu, les lignes, les mots, les caractères, et les résultats des chaînes d’images pour une utilisation directe dans vos applications .NET.
Du code source à l'aboutissement final — les données résultantes seraient inutiles si vous n'étiez pas capable de les exporter vers votre application. IronOCR comprend cela et vous permet d'exporter le résultat OCR vers XHTML afin de pouvoir travailler avec un format durable sur une gamme plus large d'applications et avec une intégration dans des sites web complexes, sans parler de temps de chargement plus rapides !
Cependant, le support ne s'arrête pas là. La capacité d'exporter l'OCR vers des documents PDF interrogeables vous permet, à vous, à vos clients et à vos organisations de stocker et récupérer des documents PDF chaque fois que nécessaire ! Cela est particulièrement avantageux lorsque vous avez un contrat de 30 pages que vous pouvez chercher dans votre base de données avec quelques mots-clés, et vous permet également de présenter votre entreprise comme respectueuse de la conformité, étant donné que les documents PDF interrogeables sont prouvés pour être bénéfiques pour les personnes malvoyantes.
En plus de ce qui précède, vous pouvez exporter vos résultats vers le format OCR qui représente votre sortie OCR, les informations de mise en page, et d'information de style, et intègre les informations connexes dans le HTML standard.
En savoir plusGratuit licences de développement communautaire. Licences commerciales à partir de 749 $.





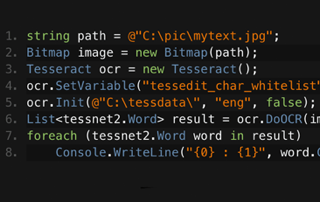
C# Tesseract OCR

Jim a été un leader dans le développement d'IronOCR. Jim conçoit et construit des algorithmes de traitement d'image et des méthodes de lecture pour l'OCR.
Voir Comparaison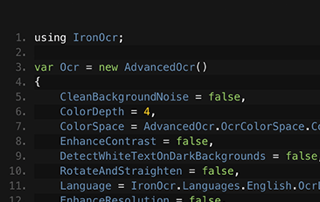
C# OCR ASP.NET

Apprenez comment l'équipe de Gemma utilise IronOCR pour lire du texte à partir d'images pour leur logiciel d'archivage. Gemma partage ses propres exemples de code.
Tutoriel Image à Texte .NET




L'équipe d'Iron a plus de 10 ans d'expérience dans le marché des composants logiciels .NET.








Install-Package IronOcr

Pas de carte de crédit requise
Votre clé d'essai devrait être dans l'e-mail.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Pas de carte de crédit requise
Testez en production sans filigranes.
Fonctionne où que vous en ayez besoin.
Profitez de 30 jours de produit entièrement fonctionnel.
Configurez-le et faites-le fonctionner en quelques minutes.
Accès complet à notre équipe de support technique durant votre essai produit
Une démonstration en direct de notre produit et de ses fonctionnalités clés
Obtenez des recommandations de fonctionnalités spécifiques au projet
Nous répondons à toutes vos questions afin de nous assurer que vous disposez de toutes les informations dont vous avez besoin. (Sans aucun engagement)





Réservez une Consultation sans Engagement

Remplissez le formulaire ci-dessous ou envoyez un email à sales@ironsoftware.com
Vos informations seront toujours gardées confidentielles.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagement.


