



Probar en un entorno en vivo
Probar en producción sin marcas de agua.
Funciona donde lo necesites.

using IronOcr;
string imageText = new IronTesseract().Read(@"images\image.png").Text;Imports IronOcr
Private imageText As String = (New IronTesseract()).Read("images\image.png").TextInstall-Package IronOcr
IronOCR es único en su capacidad de detectar y leer automáticamente texto de imágenes y documentos PDF escaneados imperfectamente. La clase IronTesseract proporciona la API más sencilla.
Prueba otros ejemplos de código para obtener un control detallado de tus operaciones OCR en C#.
IronOCR ofrece la versión más avanzada de Tesseract conocida en cualquier parte, en cualquier plataforma, con mayor velocidad, precisión y un DLL y API nativo.
Compatible con Tesseract 3, Tesseract 4, y Tesseract 5 for .NET Framework, Standard, Core, Xamarin, y Mono.
IronTesseract para usar API intuitivasRead para realizar OCR en VB.NETTextusing IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR admite 125 idiomas internacionales. Además del inglés, que se instala por defecto, los paquetes de idiomas adicionales se pueden agregar a su proyecto .NET a través de NuGet o descargarlos de nuestra Página de Idiomas. En España, el soporte multilingüe es especialmente relevante: la LOPDGDD exige que el tratamiento de datos personales sea preciso y trazable con independencia del idioma del documento, por lo que un OCR con cobertura de los cuatro idiomas cooficiales del país es un requisito de cumplimiento, no una opción. La mayoría de los idiomas están disponibles en España es un país con cuatro lenguas cooficiales: castellano, catalán, euskera (vasco) y gallego. Esta pluralidad lingüística no es únicamente cultural; tiene implicaciones regulatorias directas que los sistemas de OCR deben contemplar. LOPDGDD y precisión multilingüe. La Ley Orgánica de Protección de Datos y Garantía de los Derechos Digitales (LOPDGDD), que transpone el RGPD al ordenamiento jurídico español, exige que los datos personales extraídos de documentos sean exactos y estén actualizados. Cuando un documento contiene nombres propios, direcciones o referencias fiscales en catalán, euskera o gallego, un motor OCR que no maneje correctamente estos idiomas puede generar errores que constituyan una infracción del principio de exactitud. La AEPD (Agencia Española de Protección de Datos) ha sancionado a organizaciones por inexactitudes en el tratamiento automatizado de datos personales. TicketBAI y el euskera en Bizkaia. El sistema TicketBAI, implantado en los territorios históricos de Bizkaia, Gipuzkoa y Araba, obliga a los contribuyentes a emitir y conservar tiques de venta con firma electrónica. Muchos de estos documentos incluyen campos en euskera, como eIDAS y documentos multilingües. Los certificados digitales emitidos por la FNMT (Fábrica Nacional de Moneda y Timbre) en el marco del reglamento eIDAS pueden acompañar documentos redactados en cualquiera de las lenguas cooficiales. La extracción de metadatos de firma mediante OCR requiere que el motor reconozca correctamente el texto independientemente del idioma del documento firmado. Ventaja competitiva en el sector público. Las administraciones autonómicas —Generalitat de Catalunya, Eusko Jaurlaritza, Xunta de Galicia— generan volúmenes masivos de documentación en sus respectivas lenguas. Las empresas que ofrezcan soluciones de digitalización con OCR preciso en todos los idiomas cooficiales tendrán una ventaja clara en licitaciones públicas relacionadas con digitalización documental y gestión de expedientes electrónicos. Escenario: Una asesoría fiscal de Bilbao necesita digitalizar e indexar automáticamente tiques TicketBAI emitidos por sus clientes del País Vasco. Los tiques están redactados en euskera e incluyen el La configuración recomendada con IronOCR es la siguiente: Con el paquete La compatibilidad multilingüe de IronOCR con los 125 idiomas disponibles, incluyendo los cuatro idiomas cooficiales de España, convierte a esta biblioteca en una solución idónea para proyectos de digitalización en el mercado español. El cumplimiento de la LOPDGDD, la integración con flujos TicketBAI supervisados por la AEPD, y la compatibilidad con documentos firmados bajo eIDAS con certificados FNMT son casos de uso reales que IronOCR resuelve con una configuración mínima. Si su organización opera en entornos regulados en España, IronOCR proporciona la precisión multilingüe necesaria para garantizar la conformidad normativa en cada extracción de texto.Compatibilidad con idiomas de IronOCR
Fast, Standard (recomendado), y Best calidad. La opción de calidad Best puede ofrecer resultados más precisos, pero también será más lenta en tiempo de procesamiento.Aplicaciones regulatorias en España
Faktura-zenbakia (número de factura) o BEZ-oinarria (base imponible del IVA). Los sistemas de archivo y auditoría que emplean OCR para indexar estos tiques deben reconocer correctamente el texto en euskera para cumplir con las obligaciones de conservación ante la Hacienda Foral correspondiente.Ejemplo práctico
Número de identificación fiscal (NIF/CIF) del emisor y el BEZ-oinarria (base imponible). El sistema debe extraer estos campos con precisión para alimentar el software de contabilidad y generar el rastro de auditoría exigido por la Hacienda Foral de Bizkaia.using IronOcr;
// Instalar: IronOcr + IronOcr.Languages.Basque vía NuGet
var ocr = new IronTesseract();
ocr.Language = OcrLanguage.BasqueBest; // Euskera, calidad máxima
using var input = new OcrInput();
input.LoadImage("ticketbai_bizkaia_2024_001.tiff");
OcrResult result = ocr.Read(input);
// Extraer campos clave del tique TicketBAI
Console.WriteLine("Texto extraído del tique TicketBAI:");
Console.WriteLine(result.Text);
// Salida esperada incluye: NIF/CIF, Faktura-zenbakia, BEZ-oinarria, IVA tipo aplicable
using IronOcr;
// Instalar: IronOcr + IronOcr.Languages.Basque vía NuGet
var ocr = new IronTesseract();
ocr.Language = OcrLanguage.BasqueBest; // Euskera, calidad máxima
using var input = new OcrInput();
input.LoadImage("ticketbai_bizkaia_2024_001.tiff");
OcrResult result = ocr.Read(input);
// Extraer campos clave del tique TicketBAI
Console.WriteLine("Texto extraído del tique TicketBAI:");
Console.WriteLine(result.Text);
// Salida esperada incluye: NIF/CIF, Faktura-zenbakia, BEZ-oinarria, IVA tipo aplicableImports IronOcr
' Instalar: IronOcr + IronOcr.Languages.Basque vía NuGet
Dim ocr As New IronTesseract()
ocr.Language = OcrLanguage.BasqueBest ' Euskera, calidad máxima
Using input As New OcrInput()
input.LoadImage("ticketbai_bizkaia_2024_001.tiff")
Dim result As OcrResult = ocr.Read(input)
' Extraer campos clave del tique TicketBAI
Console.WriteLine("Texto extraído del tique TicketBAI:")
Console.WriteLine(result.Text)
' Salida esperada incluye: NIF/CIF, Faktura-zenbakia, BEZ-oinarria, IVA tipo aplicable
End Using
$vbLabelText
$csharpLabel
IronOcr.Languages.Basque en modo Best, IronOCR reconoce con precisión los caracteres específicos del euskera (como tx, tz o ñ en contextos mixtos), garantizando que los datos extraídos sean fiables para el cumplimiento ante la AEPD y la Hacienda Foral.Conclusión
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR devuelve un objeto de resultado avanzado para cada página que escanea utilizando Tesseract 5. Esto contiene datos de ubicación, imágenes, texto, confianza estadística, alternativas de símbolos, nombres de fuentes, tamaños de fuentes, decoración, pesos de fuentes y posición para cada:
PageParagraphWordBarcode
Ya sean consultas sobre productos, integración o licencias, el equipo de desarrollo de productos Iron está disponible para apoyar todas tus preguntas. Ponerse en contacto y comenzar un diálogo con Iron para aprovechar al máximo nuestra biblioteca en tu proyecto.
Hacer una pregunta
La biblioteca IronOCR (Reconocimiento Óptico de Caracteres) permite a los desarrolladores obtener resultados rápidos y eficientes al convertir Imágenes en Texto. IronOCR funciona con .NET, VB .NET y C#. Nuestras principales aplicaciones .NET para marcos .NET, específicamente diseñadas para ti, el desarrollador, para apoyarte en lograr un rendimiento óptimo para tus proyectos.
OCR recibe y reconoce archivos de texto, códigos de barras, contenido QR y más. Sin embargo, IronOCR también ofrece numerosos métodos que te permiten añadir lectura OCR y texto de imágenes en proyectos web, de escritorio de Windows o consola .NET con soporte para prácticamente formatos de imagen y archivos ilimitados, como JPG, PNG, GIF, TIFF, BMP, JPEG o PDF.
Aunque los resultados de reconocimiento de texto simple, caracteres, líneas y párrafos de la salida de imagen pueden no parecer sencillos, descubrirás que bajo el capó de IronOCR los resultados son de hecho más fáciles de lo que podrías haber pensado inicialmente. IronOCR escanea la imagen para alinear, emplea su eliminación de ruido y filtros para verificar la calidad y resolución. Observa sus propiedades, optimiza el motor OCR y utiliza una red de inteligencia artificial entrenada para luego reconocer texto (de imágenes) tan bien como cualquier humano.
OCR no es un proceso simple incluso para una computadora. Sin embargo, IronOCR hace que el proceso general de crear documentos buscables sea más rápido y sencillo, con un 100% de precisión y líneas mínimas de código.
Lee el Tutorial
El software no está limitado por fronteras geográficas — las empresas funcionan a través de fronteras y dependen de múltiples idiomas para lograr sus resultados. De manera similar, una herramienta de reconocimiento óptico de caracteres (OCR) que solo realiza el reconocimiento de documentos en un solo idioma es un gran NO en todos los aspectos!
Con una biblioteca OCR multilingüe que proporciona múltiples funcionalidades OCR, te beneficias de crear un documento PDF buscable a partir de un PDF escaneado o una imagen escaneada en múltiples idiomas (¡de francés a chino!). Tu tiempo y esfuerzo se agilizan con un documento PDF dinámico, buscable por palabras, que tú, tus clientes o tu organización pueden usar y reutilizar sin límites.
Con un fuerte enfoque en ti, tu negocio y tus necesidades OCR, ya sea integrado o a petición, la biblioteca IronOCR tiene una amplia gama de idiomas soportados. ¡Tu próximo proyecto .NET puede estar libre de preocupaciones por la compatibilidad de idiomas!
Ya sea árabe, español, francés, alemán, hebreo, italiano, japonés, chino simplificado, chino tradicional (mandarín), danés, inglés, finlandés, portugués, ruso, español o sueco, simplemente nombra los idiomas y los proporcionamos para ti! Puedes descargar tus paquetes de idiomas preferidos o contactar con nuestro soporte 24/7 para más idiomas.
El primer paso es utilizar nuestro instalador de paquetes NuGet para Windows Visual Studio.
Descargar Paquetes de Idiomas
¿Cómo se diferencia IronOCR de sus competidores? Además de permitir añadir fácilmente funcionalidades OCR, extraer texto y escanear imágenes rotadas, ¡también tiene la capacidad de realizar OCR de escaneos imperfectos! En contraste, muchos de los diversos productos listos para usar en el mercado de hoy a menudo son rígidos e inexactos, destinados a fallar en aplicaciones reales individuales y corporativas, ya que la mayoría de ellos trabajan con texto impreso con máquina, de alta resolución y perfectamente ajustado.
IronOCR extiende las capacidades de Google Tesseract con su poderosa DLL IronTesseract — una biblioteca OCR de C# nativa con una estabilidad mejorada y mayor precisión que la biblioteca Tesseract gratuita.
Con la mejor herramienta en tus manos, incluso si tienes una imagen escaneada menos que perfecta o una imagen almacenada en tu carpeta de almacenamiento — la biblioteca de procesamiento de imágenes de IronOCR limpia el ruido, rota, reduce la distorsión y alineación sesgada, y mejora la resolución y el contraste. Los ajustes avanzados de Reconocimiento Óptico de Caracteres (OCR) te dan — los programadores — las herramientas y el código para generar los mejores resultados buscables posibles, una y otra vez.
Busca las palabras que necesitas y nunca te sientas decepcionado con los resultados 99,8-100% precisos y el soporte ilimitado para documentos PDF, archivos TIFF de múltiples tramas, JPEG y JPEG2000, GIF, PNG, BMP, WBMP, System.Drawing.Image, System.Drawing.Bitmap, System.IO.Streams de imágenes, datos de imagen binaria (byte[]), ¡y todo lo demás!
Una Alternativa a Tesseract
A diferencia de otras aplicaciones .NET en el marco .NET, encontrarás que el avanzado Reconocimiento Óptico de Caracteres, dentro del gestor de paquetes de IronOCR y la consola de texto reconocido, permite a tus usuarios leer múltiples fuentes del texto (desde Times New Roman hasta cualquier cosa elegante o supuestamente difícil de entender), pesos y estilos para una lectura precisa de texto de una imagen completa o imágenes escaneadas. Nuestra capacidad de seleccionar ciertas áreas de una imagen ayuda a mejorar la velocidad y precisión. La multiprocesamiento desde unas pocas líneas a unos pocos párrafos acelera el motor OCR y permite la lectura de múltiples documentos en máquinas multinúcleo.
Nuestras afirmaciones de velocidad y precisión no se limitan al proceso de reconocimiento de caracteres. Más bien, las mejoras comienzan desde el punto de instalación ya que el motor OCR .NET de IronOCR es una biblioteca de software .NET fácil de instalar, completa y bien documentada. Hay una única instalación del gestor de paquetes NuGet para Visual Studio, y compatibilidad con multiprocesamiento con MVC, WebApp, Escritorio, Consola y Aplicaciones de Servidor.
Puedes lograr un 99,8-100% de precisión de OCR sin ningún servicio web externo, tarifas continuas o tener que enviar documentos confidenciales por internet. Sin la engorrosa codificación en C++, IronOCR es la elección clara cuando necesitas soporte completo de OCR para PDF para múltiples caracteres, palabras, líneas, párrafos, texto y documentos.
Ofrecemos las mejores opciones para desarrolladores que buscan perfeccionar su codificación, ya que IronOCR funciona de inmediato sin necesidad de ajuste de rendimiento o de modificar en gran medida imágenes de entrada. La última versión de IronOCR trabaja increíblemente rápido — hasta diez veces más rápido, y comete más de un 250% menos de errores que las compilaciones anteriores. ¡Actualizamos nuestras propias compilaciones para apoyar tus objetivos proporcionando la plataforma perfecta para OCR!
Ver Lista Completa de Funciones
Incluso al usar dispositivos móviles, nuestra biblioteca .NET OCR perfecta permite a los desarrolladores codificar 'libres de preocupaciones' ya que IronOCR soporta la exportación de contenido como un conjunto simple de texto sencillo y complejo, texto codificado por máquina, datos de código de barras o datos de modelo de objeto estructurado. Puedes dividir los resultados de contenido en párrafos, líneas, palabras, caracteres e imagen para uso directo dentro de tus aplicaciones .NET.
Desde el código fuente hasta el resultado final — los datos resultantes serían inútiles si no pudieras exportarlos a tu aplicación. IronOCR entiende esto y te permite exportar el resultado OCR a XHTML para poder trabajar con un formato sostenible a través de un rango más amplio de aplicaciones y con integración en sitios web complejos, sin mencionar tiempos de carga más rápidos!
Sin embargo, el soporte no termina ahí. La capacidad de exportar OCR a documentos PDF buscables facilita a ti, tus clientes y organizaciones almacenar y recuperar documentos PDF siempre que sea necesario! Esto es especialmente beneficioso cuando tienes un contrato de 30 páginas que puedes buscar en tu base de datos con unas pocas palabras clave, y también te permite presentar tu empresa como amigable para el cumplimiento, dado que los documentos PDF buscables han demostrado ser beneficiosos para las personas con discapacidad visual.
Además de lo anterior, puedes exportar tus resultados al formato OCR que representa tu salida OCR, información de diseño e información de estilo, e incorpora la información relacionada en HTML estándar.
Aprender MásLicencias de desarrollo comunitario gratuitas. Licencias comerciales desde $749.





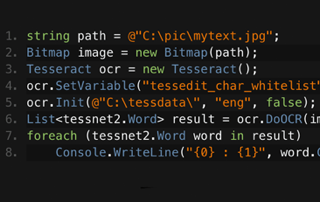
C# Tesseract OCR

Jim ha sido una figura líder en el desarrollo de IronOCR. Jim diseña y construye algoritmos de procesamiento de imágenes y métodos de lectura para OCR.
Ver comparación
C# OCR ASP.NET

Aprenda cómo el equipo de Gemma usa IronOCR para leer texto de imágenes para su software de archivo. Gemma comparte sus propios ejemplos de código.
Imagen a texto tutorial de .NET




El equipo de Iron tiene más de 10 años de experiencia en el mercado de componentes de software .NET.








Install-Package IronOcr

No se requiere tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba fue enviado
El formulario de prueba fue enviado
con éxito.
Si no es así, por favor contacte
support@ironsoftware.com
No se requiere tarjeta de crédito
Probar en producción sin marcas de agua.
Funciona donde lo necesites.
Obtén 30 días de producto completamente funcional.
Instálalo y ejecútalo en minutos.
Acceso completo a nuestro equipo de soporte técnico durante tu prueba del producto
Demostración en vivo de nuestro producto y características clave
Recomendaciones de características del proyecto
Se responde a todas sus preguntas para asegurarse de que dispone de toda la información que necesita. (Sin ningún tipo de compromiso)





Sin limitaciones. 100 % desbloqueado. Sin tarjeta de crédito.
Reserva una Consulta Sin Compromiso

Completa el formulario a continuación o envía un correo a sales@ironsoftware.com
Tus detalles siempre serán mantenidos confidenciales.

Reserve una demostración personal de 30 minutos.
Sin contrato, sin datos de tarjeta, sin compromisos.


