

How to Build an Azure OCR Service using IronOCR
Iron Software has created an OCR (Optical Character Recognition) library that takes the interoperability issues out of Azure OCR integration. Working with OCR libraries on Azure has always been a bit of a pain for developers. The solution for this and many other OCR headaches is IronOCR.
IronOCR features for Microsoft Azure
IronOCR includes the following features for building an OCR Service on Microsoft Azure:
- Turns PDFs into searchable documents so that it is easy to extract text
- Turns images into searchable documents by extracting text from images
- Reads barcodes as well as QR codes
- Exceptional accuracy
- Runs locally and requires no SaaS (Software as a Service), which is a software distribution model where a cloud provider, such as Microsoft Azure, hosts various applications and makes these applications available to end-users.
- Lightning-fast speed
Let’s have a look at how the best OCR engine, Iron Software’s IronOCR, makes it easier for developers to extract text from any input document.
Let’s get started with our Azure OCR Service
In order to get started with the sample, we need to install IronOCR first.
- Create a new Console application with C#.
- Install IronOCR via NuGet either by entering:
Install-Package IronOcror by selecting Manage NuGet packages and searching for IronOCR. This is shown below. -
Edit your
Program.csfile to look like the following:- We import the IronOCR namespace to make use of its OCR capabilities to read and extract the contents of the PDF file.
- We create a new IronTesseract object so that we can extract text from an image.
using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string[] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput())
{
Input.LoadImage("..\\Images\\Purgatory.PNG");
var result = ocr.Read(Input); // Read PNG image File
Console.WriteLine(result.Text); // Output extracted text to console
Console.ReadLine();
}
}
}
}using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string[] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput())
{
Input.LoadImage("..\\Images\\Purgatory.PNG");
var result = ocr.Read(Input); // Read PNG image File
Console.WriteLine(result.Text); // Output extracted text to console
Console.ReadLine();
}
}
}
}Imports IronOcr
Imports System
Namespace IronOCR_Ex
Class Program
Shared Sub Main(args As String())
Dim ocr = New IronTesseract()
Using Input = New OcrInput()
Input.LoadImage("..\Images\Purgatory.PNG")
Dim result = ocr.Read(Input) ' Read PNG image File
Console.WriteLine(result.Text) ' Output extracted text to console
Console.ReadLine()
End Using
End Sub
End Class
End Namespace- Next, we open an image named Purgatory.PNG. This image forms part of the Divine Comedy by Dante - one of my favorite books. The picture looks like the next image.

Figure 2 - The text to be extracted with the optical character reading capabilities of IronOCR
- The output after the above text has been extracted from the above input image text.
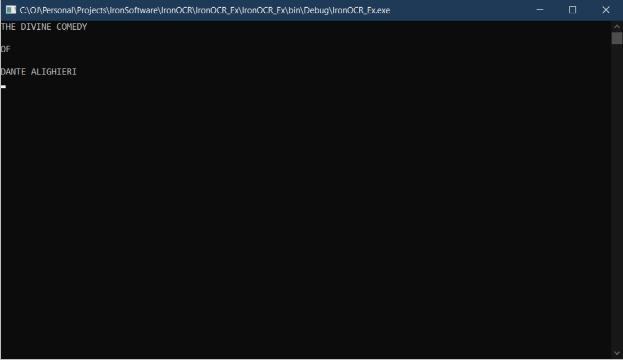
Figure 3 - Extracted text
- Let’s do the same with a PDF document. The PDF document contains the same text to extract as Figure 2.
The only difference is that we will use a PDF document instead of an image. Enter the following code:
:path=/static-assets/ocr/content-code-examples/get-started/azure-2.csvar OCR = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; // Give title to input document
// Supply optional password and name of document
input.LoadPdf("..\\Documents\\Purgatorio.pdf", Password: "dante");
var result = OCR.Read(input); // Read the input file
result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
}
Imports IronTesseract
Dim OCR As New IronTesseract()
Using input As New OcrInput()
input.Title = "Divine Comedy - Purgatory" ' Give title to input document
' Supply optional password and name of document
input.LoadPdf("..\Documents\Purgatorio.pdf", Password:="dante")
Dim result = OCR.Read(input) ' Read the input file
result.SaveAsSearchablePdf("SearchablePDFDocument.pdf")
End UsingThis code is almost the same as the previous code that extracts text from an image.
Here we make use of the OcrInput method to read the current PDF document, in this case: Purgatorio.pdf. If there is metadata in the PDF file, such as a title or a password, we can also feed it in.
The result gets saved as a searchable PDF document in which we can search for the text.
Note, if the PDF file is too big, an exception may be thrown.
- Enough on Windows applications; let’s have a look at how we can use OCR with Microsoft Azure.
The beauty of IronOCR is that it works very well with Microsoft Azure as an Azure Function in a microservice architecture. Here is a very quick example of what a Microsoft Azure Function that works with IronOCR would look like. This Microsoft Azure function extracts text from images.
public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput())
{
inputOCR.LoadImage(saStream);
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput())
{
inputOCR.LoadImage(saStream);
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} Imports System.Net.Http
Imports Microsoft.Azure.WebJobs
Imports Microsoft.AspNetCore.Mvc
Imports Microsoft.AspNetCore.Http
Imports System.Threading.Tasks
Public Module OCRFunction
Public hcClient As New HttpClient()
<FunctionName("IronOCRFunction_EX")>
Public Async Function Run(<HttpTrigger> hrRequest As HttpRequest, ecContext As ExecutionContext) As Task(Of IActionResult)
Dim URI = hrRequest.Query("image")
Dim saStream = Await hcClient.GetStreamAsync(URI)
Dim ocr = New IronTesseract()
Using inputOCR = New OcrInput()
inputOCR.LoadImage(saStream)
Dim outputOCR = ocr.Read(inputOCR)
Return New OkObjectResult(outputOCR.Text)
End Using
End Function
End ModuleThis feeds the image received by the function directly to the OCR engine to output the extracted text.
A quick recap on Microsoft Azure according to Microsoft:
Microsoft Azure Microservices are an architectural approach to building applications where each core function, or service, is built and deployed independently. Microservice architecture is distributed and loosely coupled, so one component’s failure won’t break the whole app. Independent components work together and communicate with well-defined API contracts. Build microservice applications to meet rapidly changing business needs and bring new functionalities to market faster.
A few more features of IronOCR with .NET or Microsoft Azure include the following:
- The ability to perform OCR on almost any file, image, or PDF.
- Lightning-fast speed in processing OCR input
- Exceptional accuracy
- Reads barcodes and QR codes
- Runs locally, with no SaaS required
- Can turn PDFs and images into searchable documents
- Excellent Alternative to Azure OCR from Microsoft Cognitive Services
Image Filters to improve OCR performance
OcrInput.Rotate- Rotates images by several degrees clockwise. For anti-clockwise, use negative numbers.OcrInput.Binarize()- This image filter turns every pixel black or white with no middle ground. This improves OCR performance.OcrInput.ToGrayScale()- This image filter turns every pixel into a shade of grayscale. This improves OCR speed.OcrInput.Contrast()- Increases contrast automatically. This filter improves OCR speed and accuracy in low contrast scans.OcrInput.DeNoise()- Removes digital noise. This filter should only be used where noise is expected in input documents.OcrInput.Invert()- Inverts every color.OcrInput.Dilate()- Dilation adds pixels to the boundaries of any object in an image.OcrInput.Erode()- Erosion removes pixels on object boundaries.OcrInput.Deskew()- Rotates an image so it is the right way up and orthogonal. This is very useful for OCR because Tesseract tolerance for skewed scans can be as low as 5 degrees.OcrInput.Despeckle()- Heavy background noise removal.OcrInput.EnhanceResolution- Enhances the resolution of a low-quality image.
Speed performance
An example follows:
:path=/static-assets/ocr/content-code-examples/get-started/azure-4.csvar OCR = new IronTesseract();
OCR.Configuration.BlackListCharacters = "~`$#^*_}{][|\\";
OCR.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
OCR.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
OCR.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
OCR.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput())
{
Input.LoadImage("..\\Images\\Purgatory.PNG");
var Result = OCR.Read(Input);
Console.WriteLine(Result.Text);
}
Imports IronOcr
Dim OCR As New IronTesseract()
OCR.Configuration.BlackListCharacters = "~`$#^*_}{][|\"
OCR.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
OCR.Configuration.TesseractVersion = TesseractVersion.Tesseract5
OCR.Configuration.EngineMode = TesseractEngineMode.LstmOnly
OCR.Language = OcrLanguage.EnglishFast
Using Input As New OcrInput()
Input.LoadImage("..\Images\Purgatory.PNG")
Dim Result = OCR.Read(Input)
Console.WriteLine(Result.Text)
End UsingPricing and licensing options
There are essentially three paid licensing tiers that all work on a one-time purchase, lifetime license principle.
And yes, these are free for development purposes.
Further information
- Additional resources can be found at the next link: Resources
- API References can be found here: API References
- Support for IronOCR products can be found here: Support
- Contact Iron Software: Contact Information
IronOCR features for .NET applications running OCR on Azure and other Systems
- IronOCR supports 125 international languages. Each language is available in Fast, Standard and Best quality. Some of the language packs available include:
- Bulgarian
- Armenian
- Croatian
- Afrikaans
- Danish
- Czech
- Filipino
- Finnish
- French
- German
- There are many more language packs available, to have a look at them, please follow the next link. IronOCR language packs
- It works out of the box in .NET
- Support for Xamarin
- Support for Mono
- Support for Microsoft Azure
- Support for Docker on Microsoft Azure
- Supports PDF documents
- Supports Multiframe Tiffs
- Support for all major image formats
- The following .NET Frameworks are supported:
- .NET Framework 4.5 and higher
- .NET Standard 2
- .NET Core 2
- .NET Core 3
- .NET Core 5
- You don’t have to have Tesseract (an open-source OCR engine which supports Unicode and more than 100 languages) installed for IronOCR to work.
- Has improved accuracy over Tesseract.
- Has improved speed over Tesseract.
- Corrects low-quality scans of documents or files.
- Corrects low-quality skewed scans of documents or files.
What is Optical Character Recognition (OCR)?
According to Wikipedia: Optical character recognition is the electronic or mechanical conversion of images of typed, printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo or from subtitle text superimposed on an image. OCR stands for Optical Character Recognition. There are essentially four types of optical character recognition:
- OCR - Optical Character Recognition, targets typewritten text from an input document, one character, or glyph (elemental symbol within an agreed set of symbols, for example, ‘a’ in different fonts) at a time.
- OWR - Optical Word Recognition, targets typewritten text from an input document, one word at a time.
- ICR - Intelligent Character Recognition, targets printed text such as print script (characters with no joining to other letters) and cursive text, one character or glyph at a time.
- IWR - Intelligent Word Recognition, targets cursive text.
Frequently Asked Questions
How can I integrate OCR capabilities in a C# application on Azure?
You can integrate OCR capabilities in a C# application on Azure by creating a new Console application and installing IronOCR via NuGet. Use the command Install-Package IronOcr or search for IronOCR in the NuGet package manager.
What are the advantages of using IronOCR over Azure’s native OCR service?
IronOCR offers several advantages over Azure’s native OCR service, including improved accuracy, faster processing speeds, and the ability to run locally without needing SaaS. It also supports a wide range of languages and provides image filters to enhance OCR performance.
How do I set up a Microsoft Azure Function for OCR text extraction?
To set up a Microsoft Azure Function for OCR text extraction, you can use IronOCR to create a function that extracts text from images. This is part of a microservice architecture, allowing you to integrate OCR capabilities seamlessly into your Azure applications.
Can IronOCR handle multiple languages in OCR processing?
Yes, IronOCR supports 125 international languages, each available in Fast, Standard, and Best quality, making it versatile for global applications.
What image processing options does IronOCR offer to improve OCR accuracy?
IronOCR provides a variety of image processing options such as Rotate, Binarize, ToGrayScale, Contrast, DeNoise, Invert, Dilate, Erode, Deskew, Despeckle, and EnhanceResolution to improve the accuracy and reliability of OCR results.
Is IronOCR compatible with various .NET frameworks for Azure deployment?
Yes, IronOCR is compatible with .NET Framework 4.5 and higher, .NET Standard 2, .NET Core 2, .NET Core 3, and .NET Core 5. It also supports Xamarin, Mono, and can be deployed with Docker on Microsoft Azure.
Do I need any additional software to run IronOCR on Azure?
No additional software is required to run IronOCR on Azure. It functions independently and provides improved accuracy and speed compared to Tesseract without needing its installation.
What licensing options are available for IronOCR?
IronOCR offers three paid licensing tiers based on a one-time purchase, lifetime license model. These licenses are free for development purposes, providing flexibility for project scaling.
How can I convert images and PDFs into searchable documents using IronOCR?
IronOCR allows you to convert images and PDFs into searchable documents by utilizing its OCR capabilities to extract and recognize text, making them easily searchable and indexable.
What is the process of using IronOCR to read barcodes and QR codes?
IronOCR can read barcodes and QR codes by using its built-in features to scan and extract data from these codes, facilitating their integration into C# applications on Azure.


Still Scrolling?
Want proof fast? PM > Install-Package IronOcr
run a sample watch your image become searchable text.










