

IronOCR を使用して Azure OCR サービスを構築する方法
Iron Software は、Azure OCR 統合の相互運用性の問題を解消する OCR (光学式文字認識) ライブラリを作成しました。 Azure 上で OCR ライブラリを操作することは、開発者にとって常に少々面倒なことでした。 この問題やその他の多くの OCR の悩みを解決するのが IronOCR です。
Microsoft Azure 向け IronOCR 機能
IronOCR には、Microsoft Azure 上で OCR サービスを構築するための次の機能が含まれています。
- PDFを検索可能な文書に変換し、テキストを簡単に抽出できるようにします
- 画像からテキストを抽出して画像を検索可能な文書に変換します
- バーコードとQRコードを読み取ります
- 優れた精度
- ローカルで実行され、SaaS (Software as a Service) は必要ありません。SaaS は、Microsoft Azure などのクラウド プロバイダーがさまざまなアプリケーションをホストし、これらのアプリケーションをエンド ユーザーが利用できるようにするソフトウェア配布モデルです。
- 超高速
最高の OCR エンジンである Iron Software の IronOCR を使用すると、開発者が入力ドキュメントからテキストを簡単に抽出できるようになる仕組みを見てみましょう。
Azure OCRサービスを使い始めましょう
サンプルを開始するには、まず IronOCR をインストールする必要があります。
- C# を使用して新しいコンソール アプリケーションを作成します。
- IronOCRをNuGet経由でインストールします。次の手順を入力するか、NuGetパッケージを管理してIronOCRを検索します。
Install-Package IronOcr以下に示します。 -
以下のように
Program.csファイルを編集します。- OCR機能を利用してPDFファイルの内容を読み取り抽出するために、IronOCRの名前空間をインポートします。
- 画像からテキストを抽出できるように、新しい IronTesseract オブジェクトを作成します。
using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string[] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); // Read PNG image File
Console.WriteLine(result.Text); // Output extracted text to console
Console.ReadLine();
}
}
}
}using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string[] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); // Read PNG image File
Console.WriteLine(result.Text); // Output extracted text to console
Console.ReadLine();
}
}
}
}Imports IronOcr
Imports System
Namespace IronOCR_Ex
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim ocr = New IronTesseract()
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim result = ocr.Read(Input) ' Read PNG image File
Console.WriteLine(result.Text) ' Output extracted text to console
Console.ReadLine()
End Using
End Sub
End Class
End Namespace- 次に、Purgatory.PNG という名前の画像を開きます。 この画像は私のお気に入りの本の一つ、ダンテの"神曲"の一部です。 写真は次の画像のようになります。

図2 - IronOCRの光学文字読み取り機能で抽出されるテキスト
- 上記のテキストの後の出力は、上記の入力画像テキストから抽出されています。
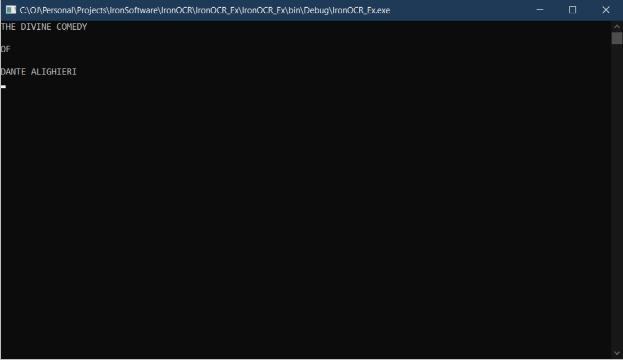
図3 - 抽出されたテキスト
- PDF ドキュメントでも同じことを行います。 PDF ドキュメントには、図 2 と同じ抽出対象テキストが含まれています。
唯一の違いは、画像の代わりにPDFドキュメントを使用することです。 次のコードを入力してください:
:path=/static-assets/ocr/content-code-examples/get-started/azure-2.csvar OCR = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; // Give title to input document
// Supply optional password and name of document
input.LoadPdf("..\\Documents\\Purgatorio.pdf", Password: "dante");
var result = OCR.Read(input); // Read the input file
result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
}
Imports IronTesseract
Dim OCR As New IronTesseract()
Using input As New OcrInput()
input.Title = "Divine Comedy - Purgatory" ' Give title to input document
' Supply optional password and name of document
input.LoadPdf("..\Documents\Purgatorio.pdf", Password:="dante")
Dim result = OCR.Read(input) ' Read the input file
result.SaveAsSearchablePdf("SearchablePDFDocument.pdf")
End Usingこのコードは、画像からテキストを抽出する前のコードとほぼ同じです。
ここではOcrInputメソッドを使用して現在のPDFドキュメントを読み込みます。この場合はPurgatorio.pdfです。 PDF ファイルにタイトルやパスワードなどのメタデータがある場合は、それを取り込むこともできます。
結果は検索可能な PDF ドキュメントとして保存され、その中でテキストを検索できます。
注意: PDF ファイルが大きすぎる場合は、例外がスローされる可能性があります。
- Windows アプリケーションでは十分です。 Microsoft Azure で OCR を使用する方法を見てみましょう。
IronOCR の優れた点は、マイクロサービス アーキテクチャの Azure 関数として Microsoft Azure と非常にうまく連携することです。 IronOCR と連携する Microsoft Azure 関数の簡単な例を以下に示します。この Microsoft Azure 関数は、画像からテキストを抽出します。
public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} Public Module OCRFunction
Public hcClient As New HttpClient()
<FunctionName("IronOCRFunction_EX")>
Public Async Function Run(<HttpTrigger> ByVal hrRequest As HttpRequest, ByVal ecContext As ExecutionContext) As Task(Of IActionResult)
Dim URI = hrRequest.Query("image")
Dim saStream = Await hcClient.GetStreamAsync(URI)
Dim ocr = New IronTesseract()
Using inputOCR = New OcrInput(saStream)
Dim outputOCR = ocr.Read(inputOCR)
Return New OkObjectResult(outputOCR.Text)
End Using
End Function
End Moduleこれにより、関数によって受信された画像が OCR エンジンに直接送られ、抽出されたテキストが出力されます。
Microsoft による Microsoft Azure の簡単な概要:
Microsoft Azure マイクロサービスは、各コア機能またはサービスが個別に構築および展開されるアプリケーションを構築するためのアーキテクチャ アプローチです。 マイクロサービスアーキテクチャは分散型で疎結合であるため、1つのコンポーネントに障害が発生してもアプリ全体に影響が出ることはありません。独立したコンポーネントは連携して動作し、明確に定義されたAPIコントラクトに基づいて通信します。 急速に変化するビジネス ニーズに対応し、新しい機能をより早く市場に投入するために、マイクロサービス アプリケーションを構築します。
.NET または Microsoft Azure を使用した IronOCR のその他の機能には、次のものがあります
- ほぼすべてのファイル、画像、PDF に対して OCR を実行する機能。
- OCR入力の処理速度が超高速
- 優れた精度
- バーコードとQRコードを読み取ります
- SaaS を必要とせず、ローカルで実行
- PDFや画像を検索可能な文書に変換できます
- Microsoft Cognitive Services の Azure OCR の優れた代替手段
OCRパフォーマンスを向上させる画像フィルター
OcrInput.Rotate- 数度時計回りに画像を回転させます。反時計回りにする場合は負の数を使用します。OcrInput.Binarize()- すべてのピクセルを黒または白にする画像フィルターです。 これにより、OCR のパフォーマンスが向上します。OcrInput.ToGrayScale()- すべてのピクセルをグレースケールの色合いに変えます。 これにより、OCR 速度が向上します。OcrInput.Contrast()- コントラストを自動的に増します。 このフィルターは、低コントラストのスキャンにおける OCR の速度と精度を向上させます。OcrInput.DeNoise()- デジタルノイズを除去します。このフィルターは入力ドキュメントにノイズが予想される場合にのみ使用してください。OcrInput.Invert()- すべての色を反転させます。OcrInput.Dilate()- 拡張により、画像内のオブジェクトの境界にピクセルが追加されます。OcrInput.Erode()- 侵食により、オブジェクトの境界のピクセルが削除されます。OcrInput.Deskew()- 画像を正しい向きにして直交します。 Tesseract の斜めスキャンの許容度は 5 度程度まで下げることができるため、これは OCR に非常に役立ちます。OcrInput.DeepCleanBackgroundNoise()- 重度のバックグラウンドノイズ除去。OcrInput.EnhanceResolution- 低品質の画像の解像度を向上させます。
スピードパフォーマンス
次に例を示します。
:path=/static-assets/ocr/content-code-examples/get-started/azure-4.csvar OCR = new IronTesseract();
OCR.Configuration.BlackListCharacters = "~`$#^*_}{][|\\";
OCR.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
OCR.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
OCR.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
OCR.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput())
{
Input.LoadImage("..\\Images\\Purgatory.PNG");
var Result = OCR.Read(Input);
Console.WriteLine(Result.Text);
}
Imports IronOcr
Dim OCR As New IronTesseract()
OCR.Configuration.BlackListCharacters = "~`$#^*_}{][|\"
OCR.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
OCR.Configuration.TesseractVersion = TesseractVersion.Tesseract5
OCR.Configuration.EngineMode = TesseractEngineMode.LstmOnly
OCR.Language = OcrLanguage.EnglishFast
Using Input As New OcrInput()
Input.LoadImage("..\Images\Purgatory.PNG")
Dim Result = OCR.Read(Input)
Console.WriteLine(Result.Text)
End Using価格とライセンスオプション
基本的に 3 つの有料ライセンス レベルがあり、すべて 1 回の購入で生涯ライセンスが適用される原則に基づいて機能します。
はい、開発目的であればこれらは無料です。
詳細情報
Azure やその他のシステムで OCR を実行する .NET アプリケーション向けの IronOCR 機能
- IronOCRは125か国語に対応しています。 各言語は、高速、標準、最高品質でご利用いただけます。 利用可能な言語パックには次のようなものがあります:
- ブルガリア語
- アルメニア語
- クロアチア語
- アフリカーンス語
- デンマーク語
- チェコ語
- フィリピン語
- フィンランド語
- フランス語
- ドイツ語
- 他にも多くの言語パックが用意されています。ご覧になるには、次のリンクをクリックしてください。 IronOCR言語パック
- .NETですぐに使える
- Xamarinのサポート
- Monoのサポート
- Microsoft Azureのサポート
- Microsoft Azure 上の Docker のサポート
- PDFドキュメントをサポート
- マルチフレームTIFFをサポート
- すべての主要な画像形式をサポート
- 次の .NET Framework がサポートされています。
- .NET Framework 4.5以降
- .NET Standard 2
- .NET Core 2
- .NET Core 3
- .NET Core 5
- IronOCR が動作するために、Tesseract (Unicode と 100 以上の言語をサポートするオープンソースの OCR エンジン) をインストールする必要はありません。
- Tesseract よりも精度が向上しました。
- Tesseract よりも速度が向上しました。
- ドキュメントまたはファイルの低品質スキャンを修正します。
- ドキュメントまたはファイルの低品質の歪んだスキャンを修正します。
光学式文字認識 (OCR) とは何ですか?
Wikipedia によると、光学式文字認識とは、スキャンした文書、文書の写真、風景写真、または画像に重ねられた字幕テキストなど、入力された印刷テキストの画像を機械でエンコードされたテキストに電子的または機械的に変換することです。 OCRは光学文字認識の略です。 光学文字認識には基本的に 4 つの種類があります。
- OCR - 光学式文字認識は、入力ドキュメントから入力されたテキスト、一度に 1 つの文字またはグリフ (合意された記号セット内の基本記号、たとえば異なるフォントでの"a") を対象とします。
- OWR - 光学式単語認識は、入力文書からタイプされたテキストを 1 単語ずつ認識します。
- ICR - インテリジェント文字認識は、印刷体(他の文字と結合されていない文字)や筆記体テキストなどの印刷テキストを、一度に 1 文字または 1 グリフずつ対象とします。
- IWR - インテリジェント単語認識、筆記体テキストを対象とします。
よくある質問
Azure上のC#アプリケーションにOCR機能を統合するにはどうすれば良いですか?
Azure上のC#アプリケーションにOCR機能を統合するには、新しいコンソールアプリケーションを作成し、NuGet経由でIronOCRをインストールします。Install-Package IronOcrコマンドを使用するか、NuGetパッケージマネージャーでIronOCRを検索します。
AzureのネイティブOCRサービスよりIronOCRを使用する利点は何ですか?
IronOCRは、精度の向上、高速な処理速度、SaaSを必要としないローカル実行能力など、AzureのネイティブOCRサービスに対するいくつかの利点を提供します。また、幅広い言語をサポートし、OCRパフォーマンスを向上させるイメージフィルターも備えています。
Microsoft Azure FunctionでOCRテキスト抽出を設定する方法は?
Microsoft Azure FunctionでOCRテキスト抽出を設定するには、IronOCRを使用して画像からテキストを抽出する機能を作成できます。これはマイクロサービスアーキテクチャの一部であり、AzureアプリケーションにOCR機能をシームレスに統合できます。
IronOCRはOCR処理で複数の言語を扱うことができますか?
はい、IronOCRは125の国際言語をサポートしており、それぞれがFast, Standard, Bestの品質で利用可能です。これにより、グローバルなアプリケーションに対応できます。
IronOCRはOCR精度を向上させるためにどのような画像処理オプションを提供していますか?
IronOCRは、Rotate, Binarize, ToGrayScale, Contrast, DeNoise, Invert, Dilate, Erode, Deskew, DeepCleanBackgroundNoise, EnhanceResolutionなど、OCR結果の精度と信頼性を向上させるための様々な画像処理オプションを提供します。
IronOCRはAzure展開用にさまざまな.NETフレームワークと互換性がありますか?
はい、IronOCRは.NET Framework 4.5以降、.NET Standard 2、.NET Core 2、.NET Core 3、.NET Core 5と互換性があります。また、Xamarin、Monoにも対応しており、Microsoft Azure上でDockerと一緒に展開できます。
IronOCRをAzureで実行するために追加のソフトウェアが必要ですか?
IronOCRをAzureで実行するために追加のソフトウェアは必要ありません。それは独立して機能し、インストールなしでTesseractよりも精度と速度が向上しています。
IronOCRのライセンスオプションにはどのようなものがありますか?
IronOCRは、一度の購入、永久ライセンスモデルに基づく3つの有料ライセンス層を提供しています。これらのライセンスは開発目的で無料であり、プロジェクトのスケーリングに柔軟性を提供します。
IronOCRを使用して画像とPDFを検索可能なドキュメントに変換するにはどうすれば良いですか?
IronOCRはOCR機能を利用してテキストを抽出し認識することにより、画像とPDFを検索可能なドキュメントに変換できます。これにより、簡単に検索またはインデックスに追加できます。
IronOCRを使用してバーコードとQRコードを読み取るプロセスは何ですか?
IronOCRは、これらのコードからデータをスキャンして抽出するための内蔵機能を使用して、バーコードとQRコードを読み取ります。これにより、C#アプリケーションでの統合が容易になります。


まだスクロールしていますか?
すぐに証拠が欲しいですか? PM > Install-Package IronOcr
サンプルを実行 あなたの画像が検索可能なテキストになるのをご覧ください。










