

How to Scrape Data from Websites in C
IronWebScraper, web kazıma, web veri çıkarma ve web içeriği ayrıştırma için bir .NET Kütüphanesidir. Geliştirme ve üretimde kullanılmak üzere Microsoft Visual Studio projelerine eklenebilecek kullanımı kolay bir kütüphanedir.
IronWebScraper, izin verilen ve yasaklanan sayfaları, nesneleri, medyaları vb. kontrol etme gibi birçok benzersiz özellik ve yeteneğe sahiptir. Ayrıca birden çok kimlik, web önbelleği ve diğer birçok özelliği yönetme imkanı da sağlar ki bunları bu eğitimde ele alacağız.
IronWebScraper ile Başlayın
Bugün IronWebScraper ile projenizde ücretsiz bir deneme ile başlayın.
Hedef Kitle
Bu öğretici, ileri düzey kazıma yetenekleri (web sitelerinden kazıma, web sitesi veri toplama ve çıkarma, web sitesi içeriği ayrıştırma, web hasadı) için çözümler oluşturmak ve uygulamak isteyen temel veya ileri düzeyde programlama becerilerine sahip yazılım geliştiricileri hedefler.

Gereken Yetenekler
- C# veya VB.NET gibi Microsoft Programlama dillerinden birini kullanarak programlamanın temel bilgileri
- Web Teknolojileri (HTML, JavaScript, JQuery, CSS, vb.) hakkında temel bir anlayış ve nasıl çalıştıkları
- DOM, XPath, HTML ve CSS Seçicileri hakkında temel bilgi
Araçlar
- Microsoft Visual Studio 2010 veya üstü
- Tarayıcılar için web geliştirici uzantıları, örneğin Chrome için web inspector veya Firefox için Firebug gibi
Neden Kazınıyor? (Reasons and Concepts)
Ürün veya çözüm oluşturmak isteyen kullanıcılara sahipseniz ve imkanları tanımak istiyorsanız:
- Web sitesi verilerini çıkarın
- Birden fazla web sitesinin içeriklerini, fiyatlarını, özelliklerini karşılaştırın
- Web sitesi içeriğini tarama ve önbellekleme
Yukarıdaki nedenlerden bir veya daha fazla sahibiyseniz, IronWebScraper ihtiyaçlarınızı karşılamak için harika bir kütüphanedir.
IronWebScraper Nasıl Kurulur?
Sen Create a New Project (Ek A'ya bakın) yaptıktan sonra, kütüphaneyi NuGet kullanarak otomatik olarak veya DLL'i manuel olarak yükleyerek projenize ekleyebilirsiniz.
NuGet Kullanarak Kurulum
NuGet kullanarak projeye IronWebScraper kütüphanesini eklemek için, görsel arayüz (NuGet Paket Yöneticisi) veya Paket Yöneticisi Konsolunu kullanarak komutla yapabiliriz.
NuGet Paket Yöneticisini Kullanarak
- Fareyi kullanarak -> proje adına sağ tıklayın -> NuGet Paketlerini Yönet'i seçin
- Gözat sekmesinden ->
IronWebScraperarayın -> Kurun - Tamam'ı tıklayın
- Ve bitiyoruz
NuGet Paket Konsolunu Kullanarak
- Araçlar menüsünden -> NuGet Paket Yöneticisi -> Paket Yöneticisi Konsolu
- Varsayılan Proje olarak Sınıf Kütüphanesi Projesi'ni seçin
- Komut çalıştır ->
Install-Package IronWebScraper
Manuel Kurulum
- https://ironsoftware.com adresine gidin
- IronWebScraper'e tıklayın veya URL https://ironsoftware.com/csharp/webscraper/ kullanarak sayfasını doğrudan ziyaret edin
- DLL İndir'e tıklayın.
- İndirilen sıkıştırılmış dosyayı çıkartın
- Visual Studio'da projeye sağ tıklayın -> ekleyin -> referans -> göz at
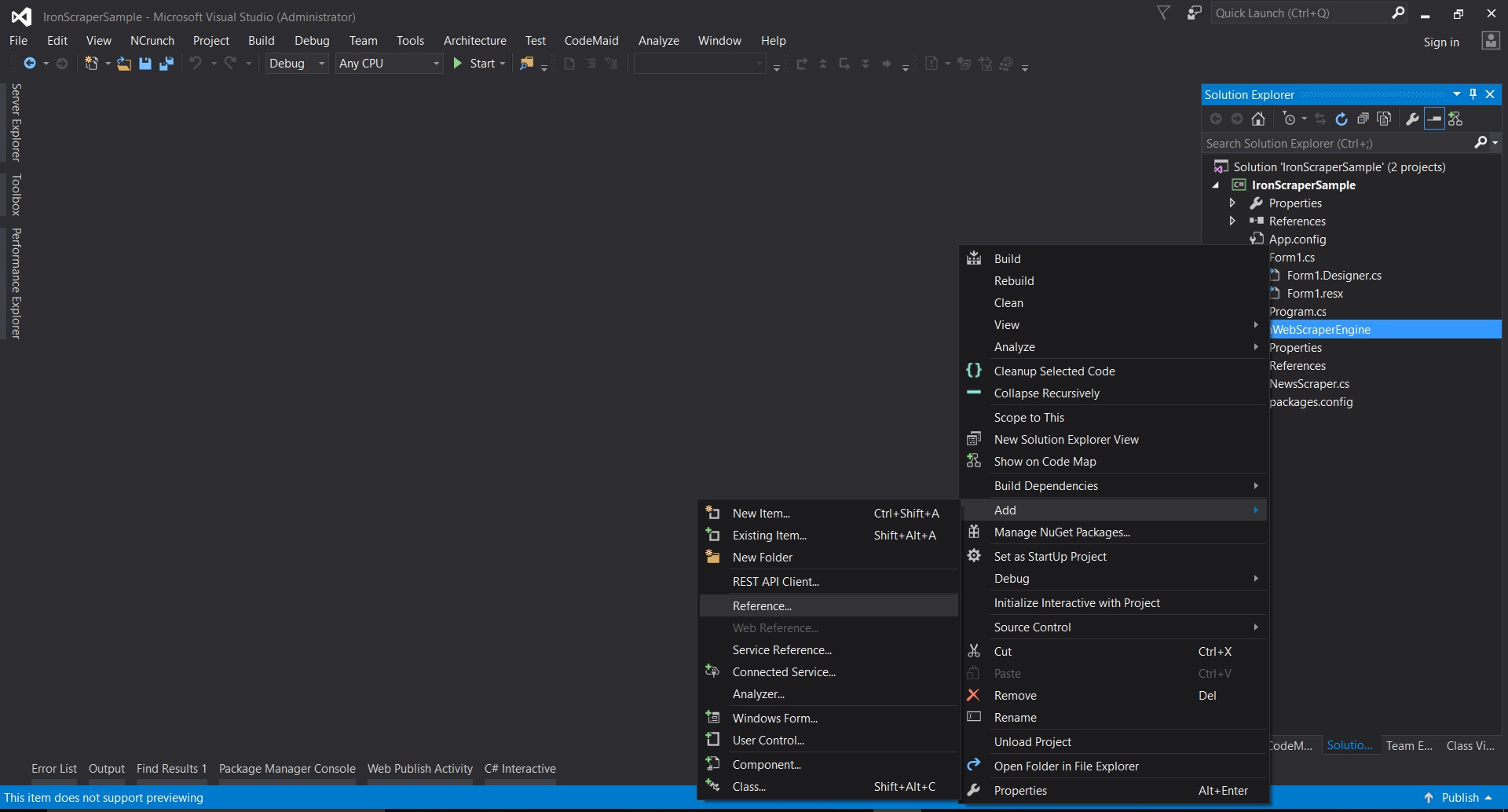
- Çıkartılan klasöre gidin ->
netstandard2.0-> ve tüm.dlldosyalarını seçin
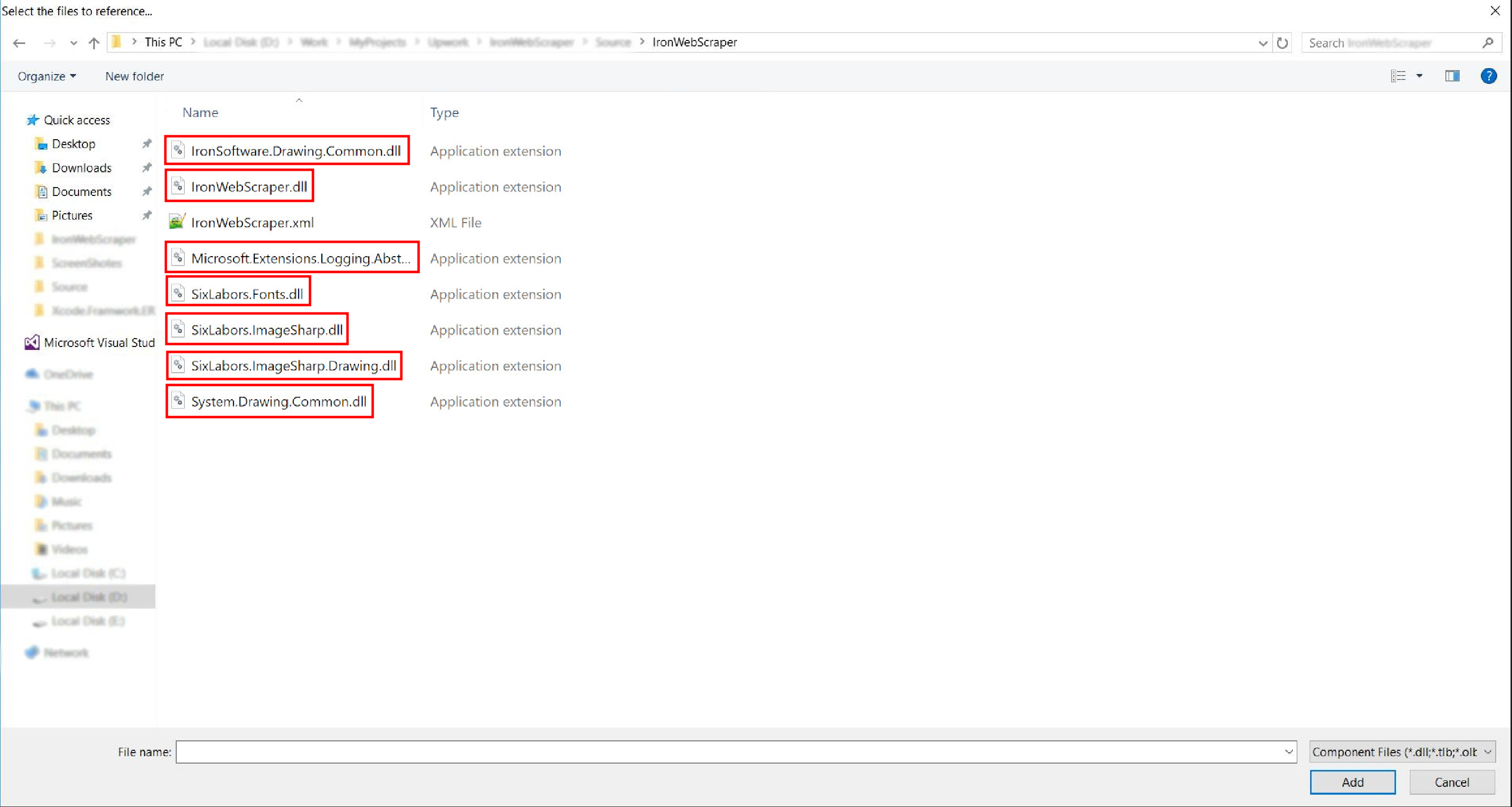
- Ve işimiz bitiyor!
HelloScraper - İlk IronWebScraper Örneğimiz
Her zamanki gibi, IronWebScraper'ı kullanarak ilk adımımızı atmak için Hello Scraper Uygulamasını oluşturmakla başlayacağız.
- "IronWebScraperSample" adında yeni bir Konsol Uygulaması oluşturduk
IronWebScraper Örneği Oluşturma Adımları
- Bir Klasör oluşturun ve adını "HelloScraperSample" koyun
-
Ardından yeni bir sınıf ekleyin ve adını
HelloScraperolarak verin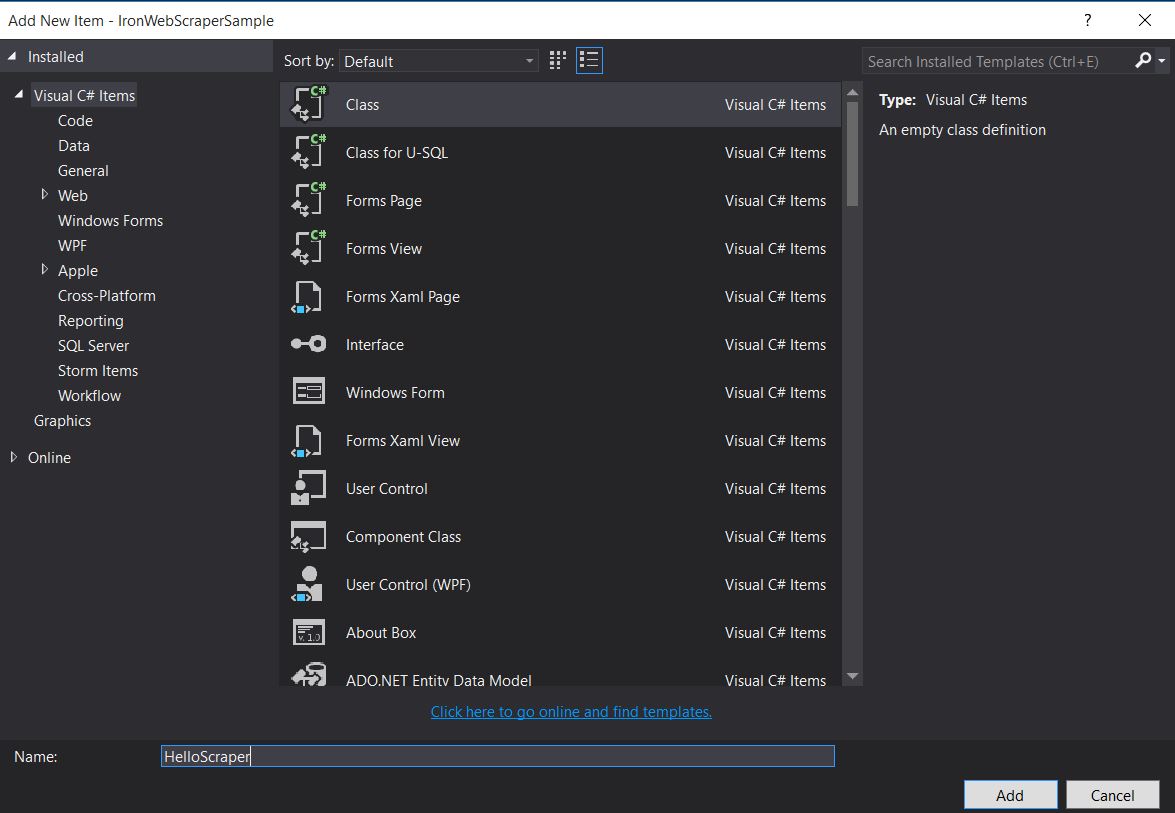
-
Bu kod örneğini
HelloScraperekleyinpublic class HelloScraper : WebScraper { /// <summary> /// Override this method to initialize your web scraper. /// Important tasks will be to request at least one start URL and set allowed/banned domain or URL patterns. /// </summary> public override void Init() { License.LicenseKey = "LicenseKey"; // Write License Key this.LoggingLevel = WebScraper.LogLevel.All; // Log all events this.Request("https://blog.scrapinghub.com", Parse); // Initialize a web request to the given URL } /// <summary> /// Override this method to create the default Response handler for your web scraper. /// If you have multiple page types, you can add additional similar methods. /// </summary> /// <param name="response">The HTTP Response object to parse</param> public override void Parse(Response response) { // Set working directory for the project this.WorkingDirectory = AppSetting.GetAppRoot() + @"\HelloScraperSample\Output\"; // Loop on all links foreach (var titleLink in response.Css("h2.entry-title a")) { // Read link text string title = titleLink.TextContentClean; // Save result to file Scrape(new ScrapedData() { { "Title", title } }, "HelloScraper.json"); } // Loop on all links for pagination if (response.CssExists("div.prev-post > a[href]")) { // Get next page URL var nextPage = response.Css("div.prev-post > a[href]")[0].Attributes["href"]; // Scrape next URL this.Request(nextPage, Parse); } } }public class HelloScraper : WebScraper { /// <summary> /// Override this method to initialize your web scraper. /// Important tasks will be to request at least one start URL and set allowed/banned domain or URL patterns. /// </summary> public override void Init() { License.LicenseKey = "LicenseKey"; // Write License Key this.LoggingLevel = WebScraper.LogLevel.All; // Log all events this.Request("https://blog.scrapinghub.com", Parse); // Initialize a web request to the given URL } /// <summary> /// Override this method to create the default Response handler for your web scraper. /// If you have multiple page types, you can add additional similar methods. /// </summary> /// <param name="response">The HTTP Response object to parse</param> public override void Parse(Response response) { // Set working directory for the project this.WorkingDirectory = AppSetting.GetAppRoot() + @"\HelloScraperSample\Output\"; // Loop on all links foreach (var titleLink in response.Css("h2.entry-title a")) { // Read link text string title = titleLink.TextContentClean; // Save result to file Scrape(new ScrapedData() { { "Title", title } }, "HelloScraper.json"); } // Loop on all links for pagination if (response.CssExists("div.prev-post > a[href]")) { // Get next page URL var nextPage = response.Css("div.prev-post > a[href]")[0].Attributes["href"]; // Scrape next URL this.Request(nextPage, Parse); } } }Public Class HelloScraper Inherits WebScraper ''' <summary> ''' Override this method to initialize your web scraper. ''' Important tasks will be to request at least one start URL and set allowed/banned domain or URL patterns. ''' </summary> Public Overrides Sub Init() License.LicenseKey = "LicenseKey" ' Write License Key Me.LoggingLevel = WebScraper.LogLevel.All ' Log all events Me.Request("https://blog.scrapinghub.com", AddressOf Parse) ' Initialize a web request to the given URL End Sub ''' <summary> ''' Override this method to create the default Response handler for your web scraper. ''' If you have multiple page types, you can add additional similar methods. ''' </summary> ''' <param name="response">The HTTP Response object to parse</param> Public Overrides Sub Parse(ByVal response As Response) ' Set working directory for the project Me.WorkingDirectory = AppSetting.GetAppRoot() & "\HelloScraperSample\Output\" ' Loop on all links For Each titleLink In response.Css("h2.entry-title a") ' Read link text Dim title As String = titleLink.TextContentClean ' Save result to file Scrape(New ScrapedData() From { { "Title", title } }, "HelloScraper.json") Next titleLink ' Loop on all links for pagination If response.CssExists("div.prev-post > a[href]") Then ' Get next page URL Dim nextPage = response.Css("div.prev-post > a[href]")(0).Attributes("href") ' Scrape next URL Me.Request(nextPage, AddressOf Parse) End If End Sub End Class$vbLabelText $csharpLabel -
Şimdi Kazımayı başlatmak için, bu kod örneğini
Mainekleyinstatic void Main(string[] args) { // Create Object From Hello Scrape class HelloScraperSample.HelloScraper scrape = new HelloScraperSample.HelloScraper(); // Start Scraping scrape.Start(); }static void Main(string[] args) { // Create Object From Hello Scrape class HelloScraperSample.HelloScraper scrape = new HelloScraperSample.HelloScraper(); // Start Scraping scrape.Start(); }Shared Sub Main(ByVal args() As String) ' Create Object From Hello Scrape class Dim scrape As New HelloScraperSample.HelloScraper() ' Start Scraping scrape.Start() End Sub$vbLabelText $csharpLabel - Sonuç,
WebScraper.WorkingDirectory/classname.Jsonformatında bir dosyaya kaydedilecektir
Kod Genel Bakış
Scrape.Start(), kazıma mantığını şu şekilde tetikler:
- Değişkenleri başlatmak, kazıma özelliklerini ve davranış niteliklerini tanımlamak için
Init()yöntemini çağırır. Init()içinde başlangıç sayfası isteğiniRequest("https://blog.scrapinghub.com", Parse)ile ayarlar.- Kodun senkronize kalmasını ve hata ayıklanmasının daha kolay olmasını sağlayarak çoklu HTTP isteklerini ve iş parçacıklarını paralel olarak ele alır.
Parse()yöntemi,Init()sonrası yanıtı işlemek, CSS seçicilerini kullanarak verileri çıkarmak ve JSON formatında kaydetmek için tetiklenir.
IronWebScraper Kütüphane İşlevleri ve Seçenekleri
Güncellenmiş dokümantasyon, manuel kurulum yöntemiyle indirilen zip dosyası içinde bulunabilir (IronWebScraper Documentation.chm File), veya kütüphanenin en son güncellemesini çevrimiçi dokümantasyonda https://ironsoftware.com/csharp/webscraper/object-reference/ adresinden kontrol edebilirsiniz.
IronWebScraper'u projenizde kullanmaya başlamak için, sınıf kütüphanenizi genişleten ve kazıma işlevselliği ekleyen IronWebScraper.WebScraper sınıfından miras almanız gerekir. Ayrıca Init() ve Parse(Response response) yöntemlerini uygulamanız gerekmektedir.
namespace IronWebScraperEngine
{
public class NewsScraper : IronWebScraper.WebScraper
{
public override void Init()
{
throw new NotImplementedException();
}
public override void Parse(Response response)
{
throw new NotImplementedException();
}
}
}namespace IronWebScraperEngine
{
public class NewsScraper : IronWebScraper.WebScraper
{
public override void Init()
{
throw new NotImplementedException();
}
public override void Parse(Response response)
{
throw new NotImplementedException();
}
}
}Namespace IronWebScraperEngine
Public Class NewsScraper
Inherits IronWebScraper.WebScraper
Public Overrides Sub Init()
Throw New NotImplementedException()
End Sub
Public Overrides Sub Parse(ByVal response As Response)
Throw New NotImplementedException()
End Sub
End Class
End Namespace| Özellikler \ işlevler | Tür | Açıklama |
|---|---|---|
Init () |
Yöntem | Kazıyıcıyı ayarlamak için kullanılır |
Parse (Response response) |
Yöntem | Kazıyıcının kullanacağı mantığı ve bunu nasıl işleyeceğini uygulamak için kullanılır. Farklı sayfa davranışları veya yapıları için birden fazla yöntem uygulayabilirsiniz. |
BannedUrls, AllowedUrls, BannedDomains |
Koleksiyonlar | URL'leri ve/veya alan adlarını yasaklamak/izin vermek için kullanılır. Ör: BannedUrls.Add("*.zip", "*.exe", "*.gz", "*.pdf"); joker karakterleri ve düzenli ifadeleri destekler. |
ObeyRobotsDotTxt |
Boole | robots.txt içindeki direktifleri okuma ve takip etmeyi etkinleştirmek veya devre dışı bırakmak için kullanılır. |
ObeyRobotsDotTxtForHost (string Host) |
Yöntem | Belirli bir alan için robots.txt içindeki direktifleri okuma ve takip etmeyi etkinleştirmek veya devre dışı bırakmak için kullanılır. |
Scrape, ScrapeUnique |
Yöntem | |
ThrottleMode |
Numaralandırma | Enum Seçenekleri: ByIpAddress, ByDomainHostName. İstekleri ana bilgisayar IP adreslerine veya alan adı ana bilgisayar adlarına saygılı olacak şekilde akıllıca sınırlamayı (throttling) etkinleştirir. |
EnableWebCache, EnableWebCache (TimeSpan cacheDuration) |
Yöntem | Web istekleri için önbelleklemeyi etkinleştirir. |
MaxHttpConnectionLimit |
Int | İzin verilen toplam açık HTTP istek sayısını (iş parçacıkları) ayarlar. |
RateLimitPerHost |
TimeSpan | Belirli bir domain veya IP adresine yapılan istekler arasında minimum nazik gecikme (duraklama) süresini ayarlar. |
OpenConnectionLimitPerHost |
Int | Her ana bilgisayar adı veya IP adresi için izin verilen eşzamanlı HTTP isteklerinin (iş parçacıklarının) sayısını ayarlar. |
WorkingDirectory |
string | Veri depolamak için bir çalışma dizini yolu ayarlar. |
Gerçek Dünya Örnekleri ve Uygulama
Çevrimiçi Bir Film Web Sitesini Kazıma
Bir örnek oluşturarak bir film web sitesini kazıyacağız.
Yeni bir sınıf ekleyin ve adını MovieScraper olarak verin:
HTML Yapısı
Bu, web sitesinde gördüğümüz ana sayfa HTML'sinin bir parçasıdır:
<div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/" >
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div><div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/" >
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div>Gördüğümüz gibi, bir film kimliği, Başlık ve Ayrıntılı Bir Sayfaya Bağlantımız var. Bu verileri kazımaya başlayalım:
public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movieId = div.GetAttribute("data-movie-id");
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
Scrape(new ScrapedData() { { "MovieId", movieId }, { "MovieTitle", movieTitle } }, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movieId = div.GetAttribute("data-movie-id");
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
Scrape(new ScrapedData() { { "MovieId", movieId }, { "MovieTitle", movieTitle } }, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
Me.Request("www.website.com", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each div In response.Css("#movie-featured > div")
If div.GetAttribute("class") <> "clearfix" Then
Dim movieId = div.GetAttribute("data-movie-id")
Dim link = div.Css("a")(0)
Dim movieTitle = link.TextContentClean
Scrape(New ScrapedData() From {
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
},
"Movie.Jsonl")
End If
Next div
End Sub
End ClassYapısal Film Sınıfı
Biçimlendirilmiş verilerimizi tutmak için bir film sınıfı uygulayalım:
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
End ClassŞimdi kodumuzu Movie sınıfını kullanacak şekilde güncelleyelim:
public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
Scrape(movie, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
Scrape(movie, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
Me.Request("https://website.com/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each div In response.Css("#movie-featured > div")
If div.GetAttribute("class") <> "clearfix" Then
Dim movie As New Movie With {
.Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
.Title = div.Css("a")(0).TextContentClean,
.URL = div.Css("a")(0).Attributes("href")
}
Scrape(movie, "Movie.Jsonl")
End If
Next div
End Sub
End ClassAyrıntılı Sayfa Kazıma
Çok detaylı bilgi için yeni özellikler ekleyerek Movie sınıfımızı genişletelim:
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
Public Property Description As String
Public Property Genre As List(Of String)
Public Property Actor As List(Of String)
End ClassArdından, genişletilmiş IronWebScraper yeteneklerini kullanarak onu kazımak için Ayrıntılı sayfaya gidin:
public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
movie.Description = div.Css("div.desc")[0].TextContentClean;
movie.Genre = div.Css("div > p > a").Select(element => element.TextContentClean).ToList();
movie.Actor = div.Css("div > p:nth-child(2) > a").Select(element => element.TextContentClean).ToList();
Scrape(movie, "Movie.Jsonl");
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
movie.Description = div.Css("div.desc")[0].TextContentClean;
movie.Genre = div.Css("div > p > a").Select(element => element.TextContentClean).ToList();
movie.Actor = div.Css("div > p:nth-child(2) > a").Select(element => element.TextContentClean).ToList();
Scrape(movie, "Movie.Jsonl");
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
Me.Request("https://domain/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each div In response.Css("#movie-featured > div")
If div.GetAttribute("class") <> "clearfix" Then
Dim movie As New Movie With {
.Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
.Title = div.Css("a")(0).TextContentClean,
.URL = div.Css("a")(0).Attributes("href")
}
Me.Request(movie.URL, AddressOf ParseDetails, New MetaData() From {
{ "movie", movie }
})
End If
Next div
End Sub
Public Sub ParseDetails(ByVal response As Response)
Dim movie = response.MetaData.Get(Of Movie)("movie")
Dim div = response.Css("div.mvic-desc")(0)
movie.Description = div.Css("div.desc")(0).TextContentClean
movie.Genre = div.Css("div > p > a").Select(Function(element) element.TextContentClean).ToList()
movie.Actor = div.Css("div > p:nth-child(2) > a").Select(Function(element) element.TextContentClean).ToList()
Scrape(movie, "Movie.Jsonl")
End Sub
End ClassIronWebScraper Kütüphane Özellikleri
HttpIdentity Özelliği
Bazı sistemlerin içeriği görmek için kullanıcının oturum açmasını gerektirir; kimlik bilgileri için HttpIdentity kullanın:
HttpIdentity id = new HttpIdentity
{
NetworkUsername = "username",
NetworkPassword = "pwd"
};
Identities.Add(id);HttpIdentity id = new HttpIdentity
{
NetworkUsername = "username",
NetworkPassword = "pwd"
};
Identities.Add(id);Dim id As New HttpIdentity With {
.NetworkUsername = "username",
.NetworkPassword = "pwd"
}
Identities.Add(id)Web Önbelleğini Etkinleştirin
Geliştirme sırasında yeniden kullanım için talep edilen sayfaları önbelleğe alın:
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
EnableWebCache();
this.Request("http://www.WebSite.com", Parse);
}public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
EnableWebCache();
this.Request("http://www.WebSite.com", Parse);
}Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\ShoppingSiteSample\Output\"
EnableWebCache()
Me.Request("http://www.WebSite.com", Parse)
End SubThrottle Ayarı
Bağlantı numaralarını ve hızını kontrol edin:
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
this.MaxHttpConnectionLimit = 80;
this.RateLimitPerHost = TimeSpan.FromMilliseconds(50);
this.OpenConnectionLimitPerHost = 25;
this.ObeyRobotsDotTxt = false;
this.ThrottleMode = Throttle.ByDomainHostName;
this.Request("https://www.Website.com", Parse);
}public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
this.MaxHttpConnectionLimit = 80;
this.RateLimitPerHost = TimeSpan.FromMilliseconds(50);
this.OpenConnectionLimitPerHost = 25;
this.ObeyRobotsDotTxt = false;
this.ThrottleMode = Throttle.ByDomainHostName;
this.Request("https://www.Website.com", Parse);
}Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\ShoppingSiteSample\Output\"
Me.MaxHttpConnectionLimit = 80
Me.RateLimitPerHost = TimeSpan.FromMilliseconds(50)
Me.OpenConnectionLimitPerHost = 25
Me.ObeyRobotsDotTxt = False
Me.ThrottleMode = Throttle.ByDomainHostName
Me.Request("https://www.Website.com", Parse)
End SubThrottle özellikleri
MaxHttpConnectionLimit
izin verilen toplam açık HTTP istek sayısı (iş parçacıkları)RateLimitPerHost
belirli bir alan veya IP adresine yapılan istekler arasında minimum saygılı gecikme (duraklama)OpenConnectionLimitPerHost
her ana bilgisayar adı veya IP adresi başına izin verilen eşzamanlı HTTP istek sayısı (iş parçacıkları)ThrottleMode
WebScraper'ı yalnızca ana bilgisayar adıyla değil, aynı zamanda sunucu IP adresleri ile de talepleri zekice sınırlayacak şekilde yapar. Birden fazla kazınan alan adının aynı makinede barındırıldığı durumlarda nazik olunması önemlidir.
Ek
Windows Form Uygulaması Nasıl Oluşturulur?
Visual Studio 2013 veya üzerini kullanın.
- Visual Studio'yu açın.
-
Dosya -> Yeni -> Proje

- Visual C# veya VB -> Windows -> Windows Forms Uygulaması'nı seçin.
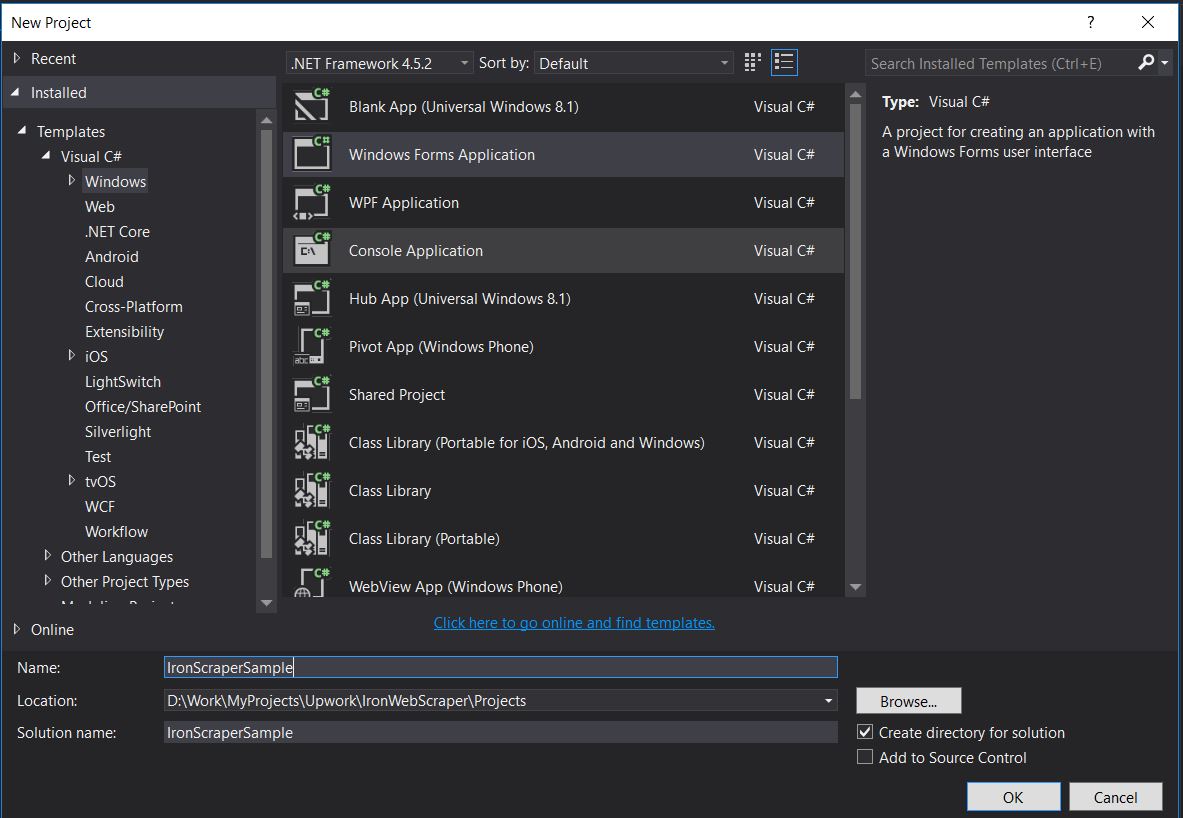
Proje Adı: IronScraperSample
Konum: Discinizde bir konum seçin.
ASP.NET Web Form Uygulaması Nasıl Oluşturulur?
-
Visual Studio'yu açın.
-
Dosya -> Yeni -> Proje
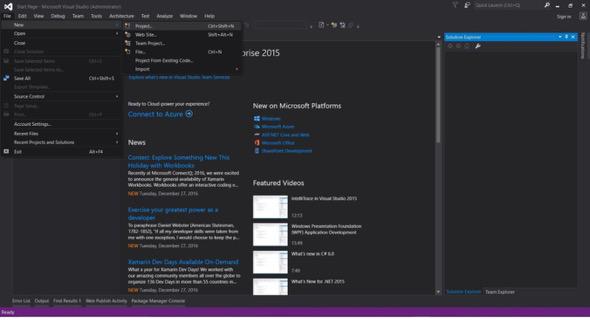
- Visual C# veya VB -> Web -> ASP.NET Web Uygulaması (.NET Çerçevesi) seçin.
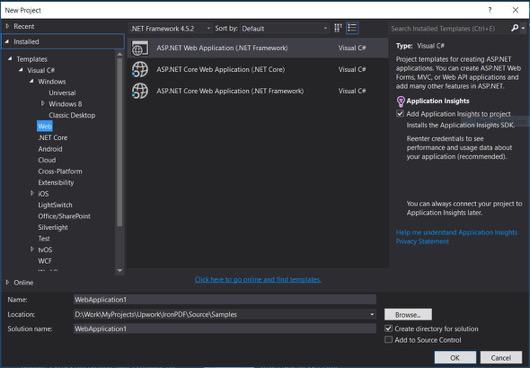
Proje Adı: IronScraperSample
Konum: Discinizde bir konum seçin.
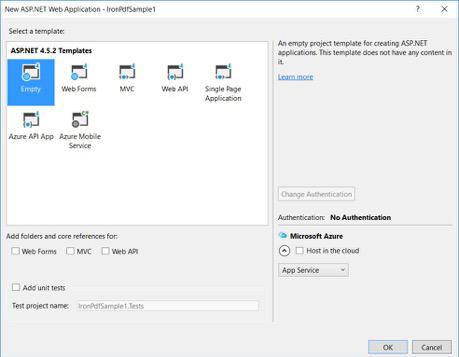
-
ASP.NET şablonlarınızdan, boş bir şablon seçin ve Web Formlarını işaretleyin.
- Temel ASP.NET Web Form Projeniz oluşturulmuştur.
Sıkça Sorulan Sorular
C# ile web sitelerinden nasıl veri kazıyabilirim?
IronWebScraper'ı kullanarak C# ile web sitelerinden veri kazıyabilirsiniz. Kütüphaneyi NuGet üzerinden yükleyerek temel bir konsol uygulaması hazırlayın ve web verilerini etkili bir şekilde çıkarmaya başlayın.
C# ile web kazıma için ön koşullar nelerdir?
C# ile web kazıma gerçekleştirmek için, temel C# veya VB.NET programlama becerilerine sahip olmalısınız ve HTML, JavaScript, CSS gibi web teknolojilerini anlamalı, ayrıca DOM, XPath ve CSS seçicileri ile aşina olmalısınız.
.NET projesine bir web kazıma kütüphanesini nasıl yükleyebilirim?
IronWebScraper'ı bir .NET projesine yüklemek için, NuGet paket yöneticisi konsolunu kullanarak Install-Package IronWebScraper komutunu çalıştırabilir veya Visual Studio'da NuGet Paket Yöneticisi arayüzü aracılığıyla gezinebilirsiniz.
Web kazıyıcıma istek kısıtlamasını nasıl uygulayabilirim?
IronWebScraper, sunucuya yapılan istek sıklığını yönetmek için istek kısıtlamasını uygulamanıza olanak tanır. Bu, MaxHttpConnectionLimit, RateLimitPerHost ve OpenConnectionLimitPerHost gibi ayarlarla yapılandırılabilir.
Web kazımada web önbelleği etkinleştirmenin amacı nedir?
Web kazımada web önbelleği etkinleştirmek, daha önceki yanıtları saklayarak ve yeniden kullanarak bir sunucuya gönderilen istek sayısını azaltmaya yardımcı olur. Bu, IronWebScraper'da EnableWebCache metodu kullanılarak sağlanabilir.
Web kazımada kimlik doğrulama nasıl ele alınabilir?
IronWebScraper ile HttpIdentity kullanarak kimlik doğrulama yönetebilir, giriş formlarının arkasındaki veya sınırlı alanlardaki içeriklere erişim sağlayarak korumalı kaynakların kazınmasını mümkün kılabilirsiniz.
C#'da basit bir web kazıyıcı örneği nedir?
Tutorialda sağlanan 'HelloScraper', IronWebScraper kullanarak temel bir web kazıyıcının nasıl kurulacağını gösteren basit bir örnektir, taleplerin nasıl başlatılacağını ve yanıtların nasıl işleneceğini içerir.
Web kazıyıcıma karmaşık sayfa yapılarıyla başa çıkması için nasıl genişletebilirim?
IronWebScraper kullanarak, karmaşık sayfa yapılarıyla başa çıkması için kazıyıcınızı genişletebilir, farklı sayfa türlerini işlemek için esnek veri çıkarma stratejilerine olanak tanıyan Parse yöntemlerini özelleştirebilirsiniz.
Bir web kazıma kütüphanesi kullanmanın faydaları nelerdir?
IronWebScraper gibi bir web kazıma kütüphanesi kullanmak, veri çıkarmayı kolaylaştırma, alan adı yönetimi, istek kısıtlama, önbellekleme ve kimlik doğrulama desteği gibi avantajlar sağlar, böylece web kazıma görevlerini etkin bir şekilde yönetebilirsiniz.


Hâlâ Kaydırıyor Musunuz?
Hızlıca kanıt ister misiniz? PM > Install-Package IronWebScraper
örnek çalıştır hedef sitenizi yapılandırılmış verilere dönüştürün.










