


C# OCR Image to Text Tutorial: Convert Images to Text Without Tesseract
想在 C# 中將圖像轉換為文字,而不需要複雜的 Tesseract 配置麻煩嗎? 這份詳盡的 IronOCR C# 教學指南展示了如何在您的 .NET 應用程式中簡單實現強大的光學字元識別,僅需幾行程式碼。
快速入門:一行程式碼從圖像中提取文字
此範例展示了掌握 IronOCR 的容易程度——僅需一行 C# 程式碼即可將圖像轉換為文字。 它展示了如何初始化 OCR 引擎並直接讀取和檢索文字,而不需要複雜的設置。
簡化工作流程(5 步驟)
- 下載 IronOCR - 用於圖像轉文字轉換的 C# OCR 程式庫
- 使用
IronTesseract類即時從圖像中讀取文字 - 應用圖像過濾器以提高低質量掃描的 OCR 準確性
- 使用可下載的語言包處理多語言
- 將結果匯出為可搜尋的 PDF 或提取文字字串
如何在 .NET 應用程式中讀取圖像中的文字?
要在您的 .NET 應用程式中實現 C# OCR 圖像轉文字功能,您需要一個可靠的 OCR 程式庫。 IronOCR 提供了一個管理解決方案,使用 IronOcr.IronTesseract 類最大化準確性和速度,無需外部依賴。
首先,將 IronOCR 安裝到您的 Visual Studio 專案中。 您可以直接下載 IronOCR DLL 或使用 NuGet 套件管理器。
Install-Package IronOcr
為什麼選擇 IronOCR 進行 C# OCR 而不是 Tesseract?
當您需要在 C# 中將圖像轉換為文字時,IronOCR 提供了相對於傳統 Tesseract 實現的重大優勢:
- 在純 .NET 環境中即刻運行
- 無需安裝或配置 Tesseract
- 運行最新引擎:Tesseract 5(以及 Tesseract 4 和 3)
- 與 .NET Framework 4.6.2+、.NET Standard 2+ 和 .NET Core 2、3、5、6、7、8、9 和 10 相容
- 與普通 Tesseract 相比,準確性和速度都有所提升
- 支援 Xamarin、Mono、Azure 和 Docker 部署
- 通過 NuGet 套件管理複雜的 Tesseract 詞典
- 自動處理 PDF、多幀 TIFF 及所有主要圖像格式
- 修正低質量的掃描並校正傾斜圖像以獲得最佳結果
如何使用 IronOCR C# 教學進行基本 OCR?
這個 Iron Tesseract C# 範例展示了使用 IronOCR 從圖像中讀取文字的最簡單方法。 IronOcr.IronTesseract 類提取文字並將其作為字串返回。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-3.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageindices);
input.Deskew(); // removes rotation and perspective
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
Private pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.LowQuality.tiff", pageindices)
input.Deskew() ' removes rotation and perspective
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)這段程式碼在清晰圖片上達到 100% 的準確性,提取文字時完全符合圖片顯示:
IronOCR Simple Example
In this simple example we test the accuracy of our C# OCR library to read text from a PNG Image. This is a very basic test, but things will get more complicated as the tutorial continues.
The quick brown fox jumps over the lazy dogIronTesseract 類在內部處理復雜的 OCR 操作。 它自動掃描對齊,優化解析度,使用 AI 從圖像中讀取文字,使用 IronOCR 具有媲美人類的準確性。
儘管在背景中進行著高度複雜的處理 - 包括圖像分析、引擎優化和智能文字識別,但 OCR 過程匹配人類閱讀速度的同時保持了卓越的準確性水準。
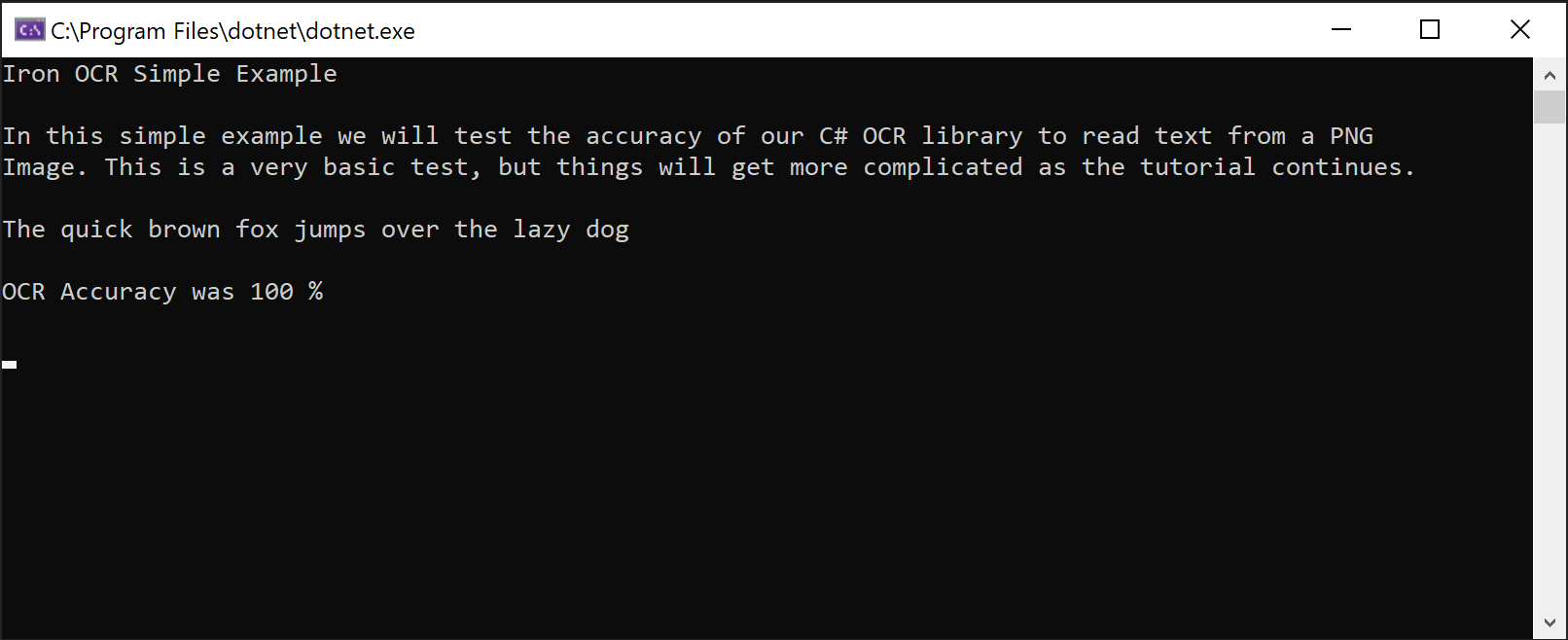 截圖展示 IronOCR 能夠從 PNG 圖片中精確提取文字的能力
截圖展示 IronOCR 能夠從 PNG 圖片中精確提取文字的能力
如何實現無需 Tesseract 配置的進階 C# OCR?
對於需要最佳效能的生產應用程式,當您在 C# 中將圖像轉換為文字時,請一起使用 OcrInput 和 IronTesseract 類。 此方法提供對 OCR 過程的精細控制。
OcrInput 類功能
- 處理多種圖像格式:JPEG、TIFF、GIF、BMP、PNG
- 匯入完整的 PDF 或特定頁面
- 自動增強對比度、解析度和圖像品質
- 修正旋轉、掃描噪點、傾斜和負片圖像
IronTesseract 類功能
- 存取 127 種以上的預打包語言
- 包括 Tesseract 5、4 和 3 引擎
- 文件型別規範(截圖、片段或完整文件)
- 整合條碼閱讀功能
- 多種輸出格式:可搜尋的 PDF、HOCR HTML、DOM 物件和字串
如何開始使用 OcrInput 和 IronTesseract?
這是這個 IronOCR C# 教學的推薦配置,適用於大多數文件型別:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-5.csusing IronOcr;
using IronSoftware.Drawing;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
// restrict OCR to a content area for faster processing
Rectangle contentArea = new Rectangle(x: 215, y: 1250, height: 280, width: 1335);
input.LoadImage("img/ComSci.png", contentArea);
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Imports IronSoftware.Drawing
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' restrict OCR to a content area for faster processing
Dim contentArea As New Rectangle(x:=215, y:=1250, height:=280, width:=1335)
input.LoadImage("img/ComSci.png", contentArea)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End Using這個配置在中等質量掃描上穩定實現接近完美的準確性。 LoadImageFrames 方法高效處理多頁文件,使其成為批量處理場景的理想選擇。

範例 TIFF 文件展示 IronOCR 的多頁文字提取能力
能夠從掃描文件如 TIFF 中的圖像和條碼中讀取文字顯示了 IronOCR 如何簡化複雜的 OCR 任務。 該程式庫在現實世界中文件中表現出色,無縫處理多頁 TIFF 和 PDF 文字提取。
IronOCR 如何處理低質量掃描?

帶有噪點的低解析度文件,IronOCR 可以使用圖像濾波器准確處理
處理包含失真和數位噪點的不完美掃描時,IronOCR 優於其他 C# OCR 程式庫。 它專為現實世界場景設計,而非完美的測試圖片。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-6.cs// PM> Install IronOcr.Languages.Arabic
using IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using OcrInput input = new OcrInput();
input.LoadImageFrame("img/arabic.gif", 1);
// add image filters if needed
// In this case, even thought input is very low quality
// IronTesseract can read what conventional Tesseract cannot.
OcrResult result = ocr.Read(input);
// Console can't print Arabic on Windows easily.
// Let's save to disk instead.
result.SaveAsTextFile("arabic.txt");' PM> Install IronOcr.Languages.Arabic
Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.Arabic
Using input As New OcrInput()
input.LoadImageFrame("img/arabic.gif", 1)
' add image filters if needed
' In this case, even thought input is very low quality
' IronTesseract can read what conventional Tesseract cannot.
Dim result As OcrResult = ocr.Read(input)
' Console can't print Arabic on Windows easily.
' Let's save to disk instead.
result.SaveAsTextFile("arabic.txt")
End Usingusing Input.Deskew(),在低品質掃描上準確性提高到 99.8%,幾乎匹敵高質量結果。 這證明了 IronOCR 是 C# OCR 不需要 Tesseract 複雜設定的首選。
圖像濾波器可能略微增加處理時間,但顯著減少整體 OCR 持續時間。 尋找合適的平衡取決於您的文件質量。
對於大多數情況,Input.Deskew() 和 Input.DeNoise() 為 OCR 性能提供可靠增強。 了解更多 圖像預處理技術。
如何優化 OCR 性能和速度?
當您在 C# 中將圖像轉換為文字時,影響 OCR 速度的最重要因素是輸入品質。 更高的 DPI(約 200 dpi)和最小噪點產生最快和最準確的結果。
雖然 IronOCR 擅長修正不完美文件,但此類增強需要額外的處理時間。
選擇編碼壓縮失真最小的圖像格式。 由於數位噪聲較低,TIFF 和 PNG 的速度通常比 JPEG 快。
哪些圖像濾鏡可以提高 OCR 速度?
以下濾鏡可以顯著提升您 C# OCR 圖像轉文字工作流程的性能:
OcrInput.Rotate(double degrees): 順時針旋轉圖片(負數為逆時針)OcrInput.Binarize(): 轉換為黑白,改善低對比場景下的性能OcrInput.ToGrayScale(): 轉換為灰階,潛在提升速度OcrInput.Contrast(): 自動調整對比度以提高準確性OcrInput.DeNoise(): 當預期有噪點時,移除數位偽影OcrInput.Invert(): 反轉顏色以顯示黑底白字OcrInput.Dilate(): 擴展文字邊界OcrInput.Erode(): 減少文字邊界OcrInput.Deskew(): 修正對齊 - 對傾斜文件至關重要OcrInput.DeepCleanBackgroundNoise(): 積極噪點移除OcrInput.EnhanceResolution: 提升低解析度圖像質量OcrInput.DetectPageOrientation():檢測並修正頁面旋轉。 傳遞OrientationDetectionMode以控制準確性/速度的折中:Detailed或ExtremeDetailed(新增 v2025.8.6)
Scale() 和 EnhanceResolution() 與 SaveAsSearchablePdf() 不相容,因為在 v2025.12.3 中已知的問題。所有其他過濾器與可搜索的 PDF 輸出一起正常工作。
如何為最大速度配置 IronOCR?
使用這些設定來優化高質量掃描的處理速度:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-7.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.ChineseSimplified;
// We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Optionally add custom tesseract .traineddata files by specifying a file path
using OcrInput input = new OcrInput();
input.LoadImage("img/MultiLanguage.jpeg");
OcrResult result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.ChineseSimplified
' We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English)
' Optionally add custom tesseract .traineddata files by specifying a file path
Using input As New OcrInput()
input.LoadImage("img/MultiLanguage.jpeg")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsTextFile("MultiLanguage.txt")
End Using此優化設置在保持 99.8% 的準確性的同時,比預設設置提高了 35% 的速度改善。
如何使用 C# OCR 讀取特定區域的圖像?
下面的 Iron Tesseract C# 範例展示了如何使用 System.Drawing.Rectangle 針對特定區域。 此技術在處理標準化表單時非常寶貴,因為文字出現在可預測的位置。
IronOCR 能否處理裁剪區域以獲得更快的結果?
使用基於像素的座標,您可以將 OCR 限制在特定區域,大大提高速度並防止提取不需要的文字:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-8.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", pageindices);
OcrResult result = ocr.Read(input);
Console.WriteLine($"{result.Pages.Length} Pages"); // 3 PagesImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("image3.gif", pageindices)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine($"{result.Pages.Length} Pages") ' 3 Pages這種目標方法在提取相關文字同時提供 41% 的速度改善。 非常適合結構化文件,如 發票、支票和表格。 相同的裁剪技術在 PDF OCR 操作中無縫工作。
 文件展示使用 IronOCR 的矩形選擇的精確基於區域的文字提取
文件展示使用 IronOCR 的矩形選擇的精確基於區域的文字提取
IronOCR 支援多少語言?
IronOCR 通過方便的語言包提供 127 國際語言。 從我們的網站或通過 NuGet Package Manager 下載它們作為 DLL。
通過 NuGet 介面安裝語言包(搜尋 "IronOcr.Languages")或存取 完整的語言包列表。
支援的語言包括阿拉伯語、中文(簡體/繁體)、日語、韓語、印地語、俄語、德語、法語、西班牙語和 115 多種其他語言,每種語言都針對準確的文字識別進行優化。
如何實現多語言 OCR?
此 IronOCR C# 教學範例展示了阿拉伯文字識別:
Install-Package IronOcr.Languages.Arabic

IronOCR 準確地從 GIF 圖像中提取阿拉伯文字
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-10.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadPdf("example.pdf", Password: "password");
// We can also select specific PDF page numbers to OCR
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Length} Pages");
// 1 page for every page of the PDFImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadPdf("example.pdf", Password:= "password")
' We can also select specific PDF page numbers to OCR
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
Console.WriteLine($"{result.Pages.Length} Pages")
' 1 page for every page of the PDFIronOCR 能否處理包含多種語言的文件?
當文件包含混合語言時,配置 IronOCR 以獲得多語言支援:
Install-Package IronOcr.Languages.ChineseSimplified
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-12.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Metadata Name";
input.LoadPdf("example.pdf", Password: "password");
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Metadata Name"
input.LoadPdf("example.pdf", Password:= "password")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")如何使用 C# OCR 處理多頁文件?
IronOCR 無縫將多頁或圖片合併到單個 OcrResult 中。 這一功能使您能够進行強大功能,如建立可搜尋的 PDF並從整個文件集提取文字。
混合和匹配各種來源 - 圖像、TIFF 幀和 PDF 頁面 - 在單次 OCR 操作中:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-13.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Title";
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Title"
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")高效地處理所有頁面的 TIFF 文件:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-14.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Html Title";
// Add more content as required...
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf",Password: "password");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Html Title"
' Add more content as required...
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf",Password:= "password")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")將 TIFF 或 PDF 轉換為可搜索格式:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-15.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
input.LoadImage("img/Barcode.png");
OcrResult result = ocr.Read(input);
foreach (var barcode in result.Barcodes)
{
Console.WriteLine(barcode.Value);
// type and location properties also exposed
}Imports IronOcr
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
input.LoadImage("img/Barcode.png")
Dim result As OcrResult = ocr.Read(input)
For Each barcode In result.Barcodes
Console.WriteLine(barcode.Value)
' type and location properties also exposed
Next barcode
End Using將現有 PDF 轉換為可搜索版本:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-16.csusing IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageindices);
OcrResult result = ocr.Read(input);
foreach (var page in result.Pages)
{
// Page object
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// null if we don't set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap(input);
System.Drawing.Bitmap pageImageLegacy = page.ToBitmap(input);
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int paragraphNumber = paragraph.ParagraphNumber;
String paragraphText = paragraph.Text;
System.Drawing.Bitmap paragraphImage = paragraph.ToBitmap(input);
int paragraphXLocation = paragraph.X;
int paragraphYLocation = paragraph.Y;
int paragraphWidth = paragraph.Width;
int paragraphHeight = paragraph.Height;
double paragraphOcrAccuracy = paragraph.Confidence;
var paragraphTextDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int lineNumber = line.LineNumber;
String lineText = line.Text;
AnyBitmap lineImage = line.ToBitmap(input);
System.Drawing.Bitmap lineImageLegacy = line.ToBitmap(input);
int lineXLocation = line.X;
int lineYLocation = line.Y;
int lineWidth = line.Width;
int lineHeight = line.Height;
double lineOcrAccuracy = line.Confidence;
double lineSkew = line.BaselineAngle;
double lineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int wordNumber = word.WordNumber;
String wordText = word.Text;
AnyBitmap wordImage = word.ToBitmap(input);
System.Drawing.Image wordImageLegacy = word.ToBitmap(input);
int wordXLocation = word.X;
int wordYLocation = word.Y;
int wordWidth = word.Width;
int wordHeight = word.Height;
double wordOcrAccuracy = word.Confidence;
if (word.Font != null)
{
// Word.Font is only set when using Tesseract Engine Modes rather than LTSM
String fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isFixedWidth = word.Font.IsFixedWidth;
bool isItalic = word.Font.IsItalic;
bool isSerif = word.Font.IsSerif;
bool isUnderlined = word.Font.IsUnderlined;
bool fontIsCaligraphic = word.Font.IsCaligraphic;
}
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int characterNumber = character.CharacterNumber;
String characterText = character.Text;
AnyBitmap characterImage = character.ToBitmap(input);
System.Drawing.Bitmap characterImageLegacy = character.ToBitmap(input);
int characterXLocation = character.X;
int characterYLocation = character.Y;
int characterWidth = character.Width;
int characterHeight = character.Height;
double characterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spell checking
OcrResult.Choice[] characterChoices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
For Each page In result.Pages
' Page object
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' null if we don't set Ocr.Configuration.ReadBarCodes = true;
Dim barcodes() As OcrResult.Barcode = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap(input)
Dim pageImageLegacy As System.Drawing.Bitmap = page.ToBitmap(input)
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphImage As System.Drawing.Bitmap = paragraph.ToBitmap(input)
Dim paragraphXLocation As Integer = paragraph.X
Dim paragraphYLocation As Integer = paragraph.Y
Dim paragraphWidth As Integer = paragraph.Width
Dim paragraphHeight As Integer = paragraph.Height
Dim paragraphOcrAccuracy As Double = paragraph.Confidence
Dim paragraphTextDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim lineNumber As Integer = line.LineNumber
Dim lineText As String = line.Text
Dim lineImage As AnyBitmap = line.ToBitmap(input)
Dim lineImageLegacy As System.Drawing.Bitmap = line.ToBitmap(input)
Dim lineXLocation As Integer = line.X
Dim lineYLocation As Integer = line.Y
Dim lineWidth As Integer = line.Width
Dim lineHeight As Integer = line.Height
Dim lineOcrAccuracy As Double = line.Confidence
Dim lineSkew As Double = line.BaselineAngle
Dim lineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim wordNumber As Integer = word.WordNumber
Dim wordText As String = word.Text
Dim wordImage As AnyBitmap = word.ToBitmap(input)
Dim wordImageLegacy As System.Drawing.Image = word.ToBitmap(input)
Dim wordXLocation As Integer = word.X
Dim wordYLocation As Integer = word.Y
Dim wordWidth As Integer = word.Width
Dim wordHeight As Integer = word.Height
Dim wordOcrAccuracy As Double = word.Confidence
If word.Font IsNot Nothing Then
' Word.Font is only set when using Tesseract Engine Modes rather than LTSM
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isFixedWidth As Boolean = word.Font.IsFixedWidth
Dim isItalic As Boolean = word.Font.IsItalic
Dim isSerif As Boolean = word.Font.IsSerif
Dim isUnderlined As Boolean = word.Font.IsUnderlined
Dim fontIsCaligraphic As Boolean = word.Font.IsCaligraphic
End If
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim characterNumber As Integer = character.CharacterNumber
Dim characterText As String = character.Text
Dim characterImage As AnyBitmap = character.ToBitmap(input)
Dim characterImageLegacy As System.Drawing.Bitmap = character.ToBitmap(input)
Dim characterXLocation As Integer = character.X
Dim characterYLocation As Integer = character.Y
Dim characterWidth As Integer = character.Width
Dim characterHeight As Integer = character.Height
Dim characterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spell checking
Dim characterChoices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next page
End Using將相同技術應用於 TIFF 轉換:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-17.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Configure document properties
input.Title = "Scanned Archive Document";
// Select pages to process
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Create searchable PDF from TIFF
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Configure document properties
input.Title = "Scanned Archive Document"
' Select pages to process
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Create searchable PDF from TIFF
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")
End Using如何將 OCR 結果匯出為 HOCR HTML?
IronOCR 支援 HOCR HTML 匯出,可在保持佈局資訊的同時進行結構化 PDF 到 HTML 及 TIFF 到 HTML 轉換:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-18.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set HTML title
input.Title = "Document Archive";
// Process multiple document types
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf", "password");
// Add TIFF pages
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Export as HOCR with position data
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Set HTML title
input.Title = "Document Archive"
' Process multiple document types
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf", "password")
' Add TIFF pages
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Export as HOCR with position data
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")
End UsingIronOCR 能否與文字一起讀取條碼?
IronOCR 獨特地將文字識別與條碼讀取功能相結合,消除使用單獨程式庫的需要:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-19.cs// Enable combined text and barcode recognition
using IronOcr;
var ocr = new IronTesseract();
// Enable barcode detection
ocr.Configuration.ReadBarCodes = true;
using (var input = new OcrInput())
{
// Load image containing both text and barcodes
input.LoadImage("img/Barcode.png");
// Process both text and barcodes
var result = ocr.Read(input);
// Extract barcode data
foreach (var barcode in result.Barcodes)
{
Console.WriteLine($"Barcode Value: {barcode.Value}");
Console.WriteLine($"Format: {barcode.Format}");
}
}
Imports IronOcr
Dim ocr As New IronTesseract()
' Enable barcode detection
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
' Load image containing both text and barcodes
input.LoadImage("img/Barcode.png")
' Process both text and barcodes
Dim result = ocr.Read(input)
' Extract barcode data
For Each barcode In result.Barcodes
Console.WriteLine($"Barcode Value: {barcode.Value}")
Console.WriteLine($"Format: {barcode.Format}")
Next
End Using如何存取詳細的 OCR 結果和元資料?
IronOCR 的結果物件提供全面的資料,供高級開發人員利用於高級應用程式。
每個 OcrResult 都包括分層集合:頁面、段落、行、單詞和字元。 所有元素都包含详细的元資料,如位置、字體資訊和信心评分。
個別元素(段落、單詞、條碼)可以匯出為圖像或位圖以供進一步處理:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-20.csusing System;
using IronOcr;
using IronSoftware.Drawing;
// Configure with barcode support
IronTesseract ocr = new IronTesseract
{
Configuration = { ReadBarCodes = true }
};
using OcrInput input = new OcrInput();
// Process multi-page document
int[] pageIndices = { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
OcrResult result = ocr.Read(input);
// Navigate the complete results hierarchy
foreach (var page in result.Pages)
{
// Page-level data
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// Extract page elements
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap();
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Paragraph properties
int paragraphNumber = paragraph.ParagraphNumber;
string paragraphText = paragraph.Text;
double paragraphConfidence = paragraph.Confidence;
var textDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Line details including baseline information
string lineText = line.Text;
double lineConfidence = line.Confidence;
double baselineAngle = line.BaselineAngle;
double baselineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Word-level data
string wordText = word.Text;
double wordConfidence = word.Confidence;
// Font information (when available)
if (word.Font != null)
{
string fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isItalic = word.Font.IsItalic;
}
foreach (var character in word.Characters)
{
// Character-level analysis
string charText = character.Text;
double charConfidence = character.Confidence;
// Alternative character choices for spell-checking
OcrResult.Choice[] alternatives = character.Choices;
}
}
}
}
}
Imports System
Imports IronOcr
Imports IronSoftware.Drawing
' Configure with barcode support
Dim ocr As New IronTesseract With {
.Configuration = New TesseractConfiguration With {
.ReadBarCodes = True
}
}
Using input As New OcrInput()
' Process multi-page document
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("img\Potter.tiff", pageIndices)
Dim result As OcrResult = ocr.Read(input)
' Navigate the complete results hierarchy
For Each page In result.Pages
' Page-level data
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' Extract page elements
Dim barcodes As OcrResult.Barcode() = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap()
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Paragraph properties
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphConfidence As Double = paragraph.Confidence
Dim textDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Line details including baseline information
Dim lineText As String = line.Text
Dim lineConfidence As Double = line.Confidence
Dim baselineAngle As Double = line.BaselineAngle
Dim baselineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Word-level data
Dim wordText As String = word.Text
Dim wordConfidence As Double = word.Confidence
' Font information (when available)
If word.Font IsNot Nothing Then
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isItalic As Boolean = word.Font.IsItalic
End If
For Each character In word.Characters
' Character-level analysis
Dim charText As String = character.Text
Dim charConfidence As Double = character.Confidence
' Alternative character choices for spell-checking
Dim alternatives As OcrResult.Choice() = character.Choices
Next
Next
Next
Next
Next
End Using總結
IronOCR 為 C# 開發人員提供了最先進的 Tesseract API 實現,在 Windows、Linux 和 Mac 平臺無縫運行。 其使用 IronOCR 的能力,準確地從圖像中讀取文字——即使從不完美的文件中——使其不同於基礎的 OCR 解決方案。
程式庫的獨特功能包括整合條碼閱讀和能夠將結果匯出為可搜尋的 PDF 或 HOCR HTML,這些能力在標準的 Tesseract 實現中無法獲得。
繼續
要繼續掌握 IronOCR:
- 探索我們的全面入門指南
- 瀏覽實用的 C# 程式碼範例
- 參考 詳細的 API 文獻
原始碼下載
準備在您的應用程式中實現 C# OCR 圖像轉文字轉換? 下載 IronOCR 並立即開始您的免費試用。
常見問題
如何在 C# 中不使用 Tesseract 將圖片轉換為文字?
您可以使用 IronOCR 在 C# 中將圖片轉換為文字,無需 Tesseract。IronOCR 內建的方法簡化了圖片到文字的直接轉換過程。
如何提高低質量圖片的 OCR 準確性?
IronOCR 提供圖像過濾器,如 Input.Deskew() 和 Input.DeNoise(),可以通過校正傾斜和降低噪聲來增強低質量圖像,從而顯著提高 OCR 的準確性。
使用 C# 中的 OCR 從多頁文件中提取文字的步驟是什麼?
要從多頁文件中提取文字,IronOCR 允許您通過 LoadPdf() 方法載入和處理每個頁面,或處理 TIFF 文件,有效地將每頁轉換為文字。
是否可以同時從一張圖片中讀取條碼和文字?
是的,IronOCR 可以從單一圖片中讀取文字和條碼。您可以啟用條碼讀取功能 ocr.Configuration.ReadBarCodes = true,以提取文字和條碼資料。
如何設置多語言文件的 OCR 處理?
IronOCR 支持超過 125 種語言,允許您使用 ocr.Language 設置主要語言,並使用 ocr.AddSecondaryLanguage() 新增其他語言以進行多語言文件處理。
有哪些方法可以將 OCR 結果導出為不同格式?
IronOCR 提供幾種方法來導出 OCR 結果,如用於 PDF 的 SaveAsSearchablePdf()、純文字的 SaveAsTextFile()、以及 HOCR HTML格式的 SaveAsHocrFile()。
如何優化大圖像文件的 OCR 處理速度?
要優化 OCR 處理速度,使用 IronOCR 的 OcrLanguage.EnglishFast 進行快速語言識別,並使用 System.Drawing.Rectangle 定義特定的 OCR 區域以減少處理時間。
如何處理受保護 PDF 文件的 OCR 處理?
處理受保護的 PDF 時,使用 LoadPdf() 方法並提供正確的密碼。IronOCR 通過自動將頁面轉換為圖像進行 OCR 處理來處理基於圖像的 PDF。
如果 OCR 結果不準確,我應該怎麼做?
如果 OCR 結果不準確,考慮使用 IronOCR 的圖像增強功能,如 Input.Deskew() 和 Input.DeNoise(),並確保安裝了正確的語言包。
我可以自訂 OCR 過程以排除某些字元嗎?
是的,IronOCR 允許通過使用 BlackListCharacters 屬性來自定義 OCR 過程,排除特定字元,以提高準確性和處理速度,只專注於相關的文字。



還在滾動?
想要快速證明? PM > Install-Package IronOcr
執行範例 觀看您的圖像轉變為可搜尋文字。










