

C# ve IronWebScraper kullanarak Çevrimiçi Film Web Sitesi Kazıma
IronWebScraper, film verilerini HTML ögelerini ayrıştırarak, yapılandırılmış veri depolama için türlendirilmiş nesneler yaratarak ve sayfalar arasında dolaşırken meta verileri kullanarak kapsamlı film bilgi veri setleri oluşturup sitelerden çeker. Bu C# Web Scraper kütüphanesi, yapısal olmayan web içeriğini organize, analiz edilebilir verilere dönüştürmeyi basitleştirir.
Hızlı Başlangıç: C#'ta Filmleri Kazıyın
- IronWebScraper'ı NuGet Paket Yöneticisi aracılığıyla yükleyin
WebScrapersınıfından türetilen bir sınıf oluşturunInit()metodunu geçersiz kılarak lisansı ayarlayın ve hedef URL'yi talep edin- Film verilerini CSS seçicileri kullanarak çıkarmak için
Parse()metodunu geçersiz kılın - Verileri JSON formatında kaydetmek için
Scrape()metodunu kullanın
-
NuGet Paket Yöneticisi ile https://www.nuget.org/packages/IronWebScraper yükleyin
PM > Install-Package IronWebScraper -
Bu kod parçasını kopyalayıp çalıştırın.
using IronWebScraper; using System; public class QuickstartMovieScraper : WebScraper { public override void Init() { // Set your license key License.LicenseKey = "YOUR-LICENSE-KEY"; // Configure scraper settings this.LoggingLevel = LogLevel.All; this.WorkingDirectory = @"C:\MovieData\Output\"; // Start scraping from the homepage this.Request("https://example-movie-site.com", Parse); } public override void Parse(Response response) { // Extract movie titles using CSS selectors foreach (var movieDiv in response.Css(".movie-item")) { var title = movieDiv.Css("h2")[0].TextContentClean; var url = movieDiv.Css("a")[0].Attributes["href"]; // Save the scraped data Scrape(new { Title = title, Url = url }, "movies.json"); } } } // Run the scraper var scraper = new QuickstartMovieScraper(); scraper.Start(); -
Canlı ortamınızda test etmek için dağıtın
Bugün projenizde IronWebScraper kullanmaya başlayın ücretsiz deneme ile

Film Kazıyıcı Sınıfını Nasıl Kurarım?
Gerçek dünya web sitesi örneğiyle başlayın. Web Kazıma C# eğitimimizde açıklanan teknikleri kullanarak bir film web sitesini kazıyacağız.
Yeni bir sınıf ekleyin ve adını MovieScraper olarak koyun:

Özel bir kazıyıcı sınıfı oluşturmak, kodunuzu düzenli hale getirir ve tekrar kullanılabilir yapar. Bu yaklaşım, nesne yönelimli ilkeleri izler ve gelecekte işlevsellik eklemeyi kolaylaştırır.
Hedef Web Sitesi Yapısı Nasıl Görünüyor?
Kazıma için site yapısını inceleyin. Web sitesinin yapısını anlamak, etkili web kazıma için kritiktir. Çevrimiçi Film Web Sitesinden Kazıma rehberimize benzer şekilde, önce HTML yapısını analiz edin:
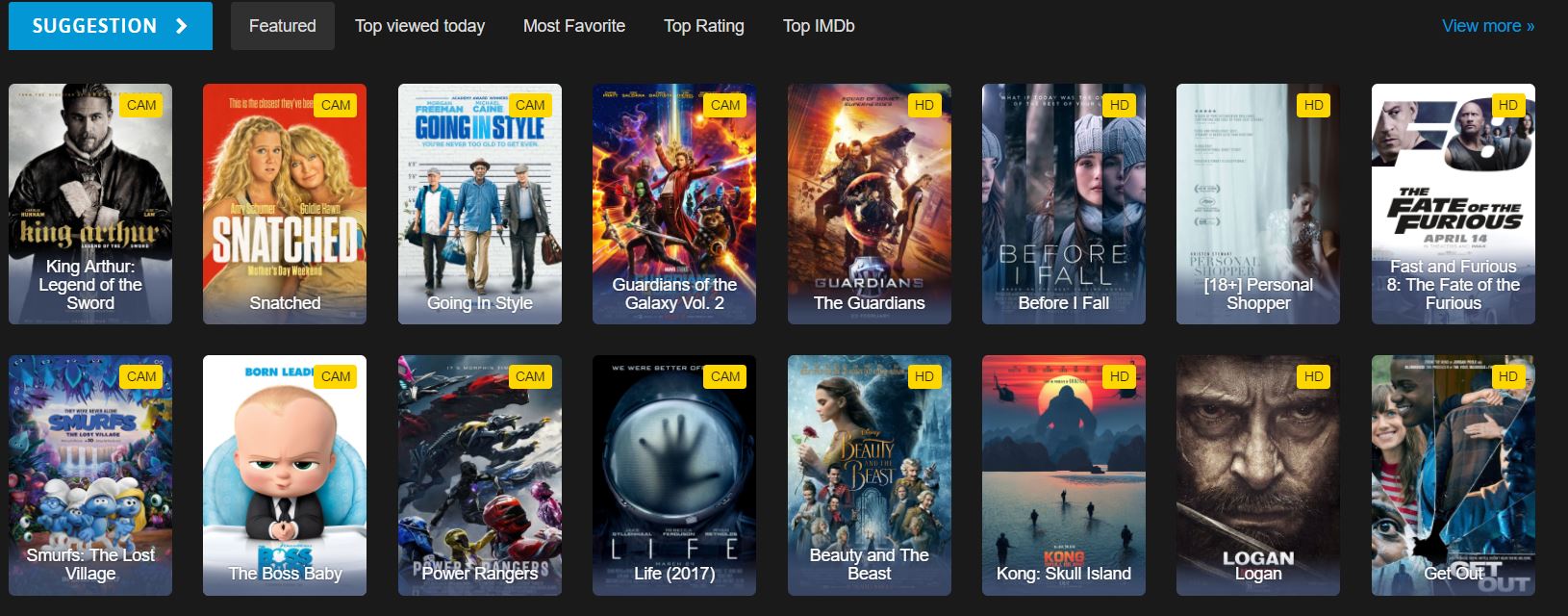
Hangi HTML Öğeleri Film Verilerini İçeriyor?
Bu, web sitesinde gördüğümüz ana sayfa HTML'inin bir parçasıdır. HTML yapısını incelemek, hangi CSS seçicilerini doğru kullanacağınızı belirlemenize yardımcı olur:
<div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div><div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div>Bir film kimliği, başlık ve detaylı bir sayfaya bağlantımız var. Her film ml-item sınıfına sahip div elementi içinde bulunur ve tanımlama için benzersiz bir data-movie-id özniteliği içerir.
Temel Film Kazıma İşlemini Nasıl Uygularım?
Bu veri kümesini kazımaya başlayın. Herhangi bir kazıyıcıyı çalıştırmadan önce, aşağıda gösterildiği gibi lisans anahtarınızı düzgün şekilde yapılandırdığınızdan emin olun:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("www.website.com", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"))
Dim link = div.Css("a")(0)
Dim movieTitle = link.TextContentClean
' Scrape and store movie data as key-value pairs
Scrape(New ScrapedData() From {
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
},
"Movie.Jsonl")
End If
Next div
End Sub
End ClassÇalışma Dizini Özelliği Ne İçindir?
Bu koddaki yenilik ne?
Çalışma Dizini özelliği, kazınılan tüm veriler ve ilgili dosyalar için ana çalışma dizinini ayarlar. Bu, tüm çıktı dosyalarının tek bir yerde organize edilmesini sağlar, bu da büyük ölçekli kazıma projeleri yönetmeyi kolaylaştırır. Dizin mevcut değilse otomatik olarak oluşturulacaktır.
Ne Zaman CSS Seçicileri ve Öznitelikleri Kullanmalıyım?
Ek hususlar:
CSS seçicileri, yapısal konum veya sınıf adlarına göre eleman hedeflemek için idealdir; doğrudan öznitelik erişimi ise kimlikler veya özel veri öznitelikleri gibi belirli değerleri çıkarmak için daha iyidir. Örneğimizde, DOM yapısında gezinmek için CSS seçicilerini (#movie-featured > div) ve belirli değerleri çıkarmak için öznitelikleri (data-movie-id) kullanıyoruz.
Kazınılan Veriler İçin Türlendirilmiş Nesneleri Nasıl Oluşturabilirim?
Kazınılan verileri biçimli nesnelerde tutmak için türlendirilmiş nesneler oluşturun. Güçlü türde nesneler kullanmak, daha iyi kod organizasyonu, IntelliSense desteği ve derleme zamanında tür denetlemeyi sağlar.
Biçimlendirilmiş verileri tutacak bir Movie sınıfı uygulayın:
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
End ClassTürlendirilmiş Nesneler Kullanarak Veri Organizasyonu Nasıl Gelişir?
Kodu güncelleyerek genel ScrapedData sözlüğü yerine türlendirilmiş Movie sınıfını kullanın:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://website.com/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Scrape and store movie object
Scrape(movie, "Movie.Jsonl")
End If
Next div
End Sub
End ClassKazıma Yöntemi Türlendirilmiş Nesneler İçin Hangi Formatı Kullanır?
Yenilik nedir?
- Kazınmış verileri tutmak için tür güvenliği ve daha iyi kod organizasyonu sağlayan bir
Moviesınıfı uyguladık. - Aşağıda gösterildiği gibi formatımızı anlayan
Scrapemetoduna film nesnelerini geçiriyoruz ve tanımlanan bir şekilde kaydediyoruz.

Çıktı otomatik olarak JSON formatında serileştirilir, bu da veritabanlarına veya diğer uygulamalara kolayca aktarılmasını sağlar.
Detaylı Film Sayfalarını Nasıl Kazırım?
Daha detaylı sayfaları kazımaya başlayın. Çoklu sayfa kazıma yaygın bir gerekliliktir ve IronWebScraper, istek zincirleme mekanizması aracılığıyla bunu basit hale getirir.
Detay Sayfalarından Ekstra Hangi Verileri Çıkarabilirim?
Film Sayfası, her film hakkında zengin meta veriler içeren bu şekilde görünüyor:

<div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div><div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>Ek Özellikler İçin Film Sınıfımı Nasıl Genişletmeliyim?
Yeni özellikler (Description, Genre, Actor, Director, Country, Duration, IMDb Score) ile Movie sınıfını genişletin ancak bu örnek için yalnızca Description, Genre ve Actor kullanın. Türler ve aktörler için List<string> kullanarak birden çok değeri zarif bir şekilde ele almak mümkün olur:
using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}Imports System.Collections.Generic
Public Class Movie
Public Property Id() As Integer
Public Property Title() As String
Public Property URL() As String
Public Property Description() As String
Public Property Genre() As List(Of String)
Public Property Actor() As List(Of String)
End ClassSayfalar Arasında Kazıma Yaparken Nasıl Dolaşabilirim?
Kazımak için detay sayfasına gidin. IronWebScraper iş parçacığı güvenliğini otomatik olarak yönetir, bu sayede birden fazla sayfa eşzamanlı olarak işlenebilir.
Farklı Sayfa Türleri İçin Neden Birden Çok Ayrıştırma Fonksiyonu Kullanmalıyım?
IronWebScraper, farklı sayfa formatlarını işlemek için birden fazla kazıma fonksiyonu eklemenizi sağlar. Bu endişe ayırma, kodunuzu daha sürdürülebilir hale getirir ve farklı sayfa yapılarının uygun şekilde ele alınmasını sağlar. Her bir ayrıştırma fonksiyonu, belirli bir sayfa türünden veri çıkarmaya odaklanabilir.
MetaData, Ayrıştırma Fonksiyonları Arasında Nesneleri Aktarmaya Nasıl Yardımcı Olur?
MetaData özelliği, istekler arasında durumu korumak için kritiktir. Daha fazlası için gelişmiş web kazıma özellikleri, kapsamlı rehberimize göz atın:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://domain/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Request detailed page
Me.Request(movie.URL, AddressOf ParseDetails, New MetaData() From {
{ "movie", movie }
})
End If
Next div
End Sub
Public Sub ParseDetails(ByVal response As Response)
' Retrieve movie object from metadata
Dim movie = response.MetaData.Get(Of Movie)("movie")
Dim div = response.Css("div.mvic-desc")(0)
' Extract description
movie.Description = div.Css("div.desc")(0).TextContentClean
' Extract genres
movie.Genre = New List(Of String)() ' Initialize genre list
For Each genre In div.Css("div > p > a")
movie.Genre.Add(genre.TextContentClean)
Next genre
' Extract actors
movie.Actor = New List(Of String)() ' Initialize actor list
For Each actor In div.Css("div > p:nth-child(2) > a")
movie.Actor.Add(actor.TextContentClean)
Next actor
' Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl")
End Sub
End ClassBu Çok Sayfalı Kazıma Yaklaşımının Temel Özellikleri Nelerdir?
Yenilik nedir?
- Detaylı sayfaları kazımak için kazıma fonksiyonları ekleyin (örn.
ParseDetails), alışveriş sitesinden kazıma yaparken kullanılan tekniklere benzer. - Dosya üreten
Scrapefonksiyonunu yeni fonksiyona taşıyın, böylece veriler yalnızca tüm detaylar toplandıktan sonra kaydedilir. - Nesne durumunu talepler arasında koruyarak film nesnelerini yeni kazıma fonksiyonlarına geçirmek için IronWebScraper özelliğini (
MetaData) kullanın. - Sayfaları kazıyın ve film nesne verilerini eksiksiz bilgiyle dosyalara kaydedin.

Kullanılabilir yöntemler ve özellikler hakkında daha fazla bilgi için API Referansi'na danışın. IronWebScraper, web sitelerinden yapılandırılmış veri çıkarmak için sağlam bir çerçeve sağlar ve veri toplama ve analiz projeleri için vazgeçilmez bir araç haline getirir.
Sıkça Sorulan Sorular
HTML kullanarak C# ile film başlıklarını nasıl çıkarırım?
IronWebScraper, HTML'den film başlıklarını çıkarmak için CSS seçici yöntemleri sağlar. Başlık öğelerini hedeflemek için '.movie-item h2' gibi uygun seçicilerle response.Css() yöntemini kullanın, ardından temiz metin değerini almak için TextContentClean özelliğine erişin.
Birden fazla film sayfası arasında gezinmenin en iyi yolu nedir?
IronWebScraper, sayfa gezinmeyi Request() yöntemi ile ele alır. Sayfalardan veri kazımak için CSS seçicilerini kullanarak sayfalandırma bağlantılarını çıkarabilir, ardından her URL ile birlikte Sayfalandırma() çağırabilirsiniz, böylece kapsamlı film veri kümeleri otomatik olarak oluşturulur.
Kazınmış film verilerini yapılandırılmış bir formatta nasıl kaydedebilirim?
IronWebScraper'ın Scrape() yöntemini kullanarak verileri JSON formatında kaydedin. Başlık, URL ve derecelendirme gibi film özelliklerini içeren anonim nesneler veya tiplendirilmiş sınıflar oluşturun, ardından Scrape()'e bir dosya adı ile birlikte geçirerek verileri otomatik olarak serileştirin ve kaydedin.
Film bilgilerini çıkarmak için hangi CSS seçicilerini kullanmam gerekiyor?
IronWebScraper, standart CSS seçicilerini destekler. Film web siteleri için, kapsayıcılara '.movie-item', başlıklara 'h2', bağlantılar için 'a[href]' ve dereceler veya türlere özgü sınıf adlarına seçiciler kullanın. Css() yöntemi, üzerinde döngü yapabileceğiniz koleksiyonlar döndürür.
Kazınmış verilerde 'CAM' gibi film kalitesi göstergelerini nasıl ele alırım?
IronWebScraper, belirli HTML öğelerini hedef alarak kalite göstergelerini çıkarmanıza ve işlemenize izin verir. Kalite rozetlerini veya metinlerini belirlemek için CSS seçicilerini kullanın, ardından bunları kapsamlı film bilgileri için kazınmış veri nesnelerinize özellikler olarak dahil edin.
Film kazıma işlemlerim için kayıt defteri ayarlayabilir miyim?
Evet, IronWebScraper yerleşik kayıt defteri işlevselliği içerir. Init() yönteminizde, kazıma etkinlikleri, hatalar ve ilerlemeyi izlemek için LoggingLevel özelliğini LogLevel.All olarak ayarlayın, bu da film veri çıkarımınızı hata ayıklamaya ve izlemenize yardımcı olur.
Kazınmış veriler için çalışma dizinlerini doğru bir şekilde nasıl yapılandırırım?
IronWebScraper, Init() yönteminde WorkingDirectory özelliğini ayarlamanıza olanak tanır. Kazınmış film verisi dosyalarının kaydedileceği 'C:\MovieData\Output\' gibi bir yol belirtin. Bu, çıkış yönetimini merkezileştirir ve verilerinizi düzenli tutar.
WebScraper sınıfından doğru bir şekilde nasıl türetilirim?
IronWebScraper'ın WebScraper temel sınıfından türeyen yeni bir sınıf oluşturun. Yapılandırma için Init() yöntemini ve veri çıkarım mantığı için Parse() yöntemini geçersiz kılın. Bu nesne yönelimli yaklaşım, film kazıyıcınızı yeniden kullanılabilir ve sürdürülebilir kılar.


Hala Kaydiriyor musunuz?
Hızlı bir kanit mi istiyorsunuz? PM > Install-Package IronWebScraper
bir örneği çalıştır hedef sitenizi yapılandırılmış veri haline getirin.










