

Scraping einer Online-Film-Website mit C# und IronWebScraper
IronWebScraper extrahiert Filmdaten von Websites, indem es HTML-Elemente parst, typisierte Objekte für die strukturierte Datenspeicherung erstellt und mithilfe von Metadaten zwischen Seiten navigiert, um umfassende Filminformations-Datasets zu erstellen. Diese C# Web Scraper Bibliothek vereinfacht die Umwandlung von unstrukturierten Webinhalten in organisierte, analysierbare Daten.
Schnellstart: Filme in C# scrapen
- Installieren Sie
IronWebScraperüber den NuGet-Paket-Manager - Erstellen Sie eine Klasse, die von
WebScrapererbt - Überschreiben Sie
Init(), um die Lizenz festzulegen und die Ziel-URL anzufordern - Überschreiben Sie
Parse(), um Filmdaten mithilfe von CSS-Selektoren zu extrahieren - Verwenden Sie die
Scrape()Methode, um Daten im JSON-Format zu speichern
-
Installieren Sie IronWebScraper mit NuGet Package Manager
-
Kopieren Sie diesen Codeausschnitt und führen Sie ihn aus.
using IronWebScraper; using System; public class QuickstartMovieScraper : WebScraper { public override void Init() { // Set your license key License.LicenseKey = "YOUR-LICENSE-KEY"; // Configure scraper settings this.LoggingLevel = LogLevel.All; this.WorkingDirectory = @"C:\MovieData\Output\"; // Start scraping from the homepage this.Request("https://example-movie-site.com", Parse); } public override void Parse(Response response) { // Extract movie titles using CSS selectors foreach (var movieDiv in response.Css(".movie-item")) { var title = movieDiv.Css("h2")[0].TextContentClean; var url = movieDiv.Css("a")[0].Attributes["href"]; // Save the scraped data Scrape(new { Title = title, Url = url }, "movies.json"); } } } // Run the scraper var scraper = new QuickstartMovieScraper(); scraper.Start(); -
Bereitstellen zum Testen in Ihrer Live-Umgebung
Beginnen Sie noch heute, IronWebScraper in Ihrem Projekt zu verwenden, mit einer kostenlosen Testversion

Wie richte ich eine Movie Scraper-Klasse ein?
Beginnen Sie mit einem realen Website-Beispiel. Wir scrapen eine Film-Website mit den Techniken, die in unserem Webscraping in C#-Tutorial beschrieben sind.
Fügen Sie eine neue Klasse hinzu und benennen Sie sie MovieScraper:

Die Erstellung einer eigenen Scraper-Klasse hilft bei der Organisation Ihres Codes und macht ihn wiederverwendbar. Dieser Ansatz folgt objektorientierten Prinzipien und ermöglicht es Ihnen, die Funktionalität später einfach zu erweitern.
Wie sieht die Struktur der Ziel-Website aus?
Untersuchen Sie die Struktur der Website auf Scraping. Für ein effektives Web-Scraping ist es wichtig, die Struktur der Website zu verstehen. Ähnlich wie in unserem Leitfaden zum Scraping von einer Online-Film-Website analysieren Sie zunächst die HTML-Struktur:
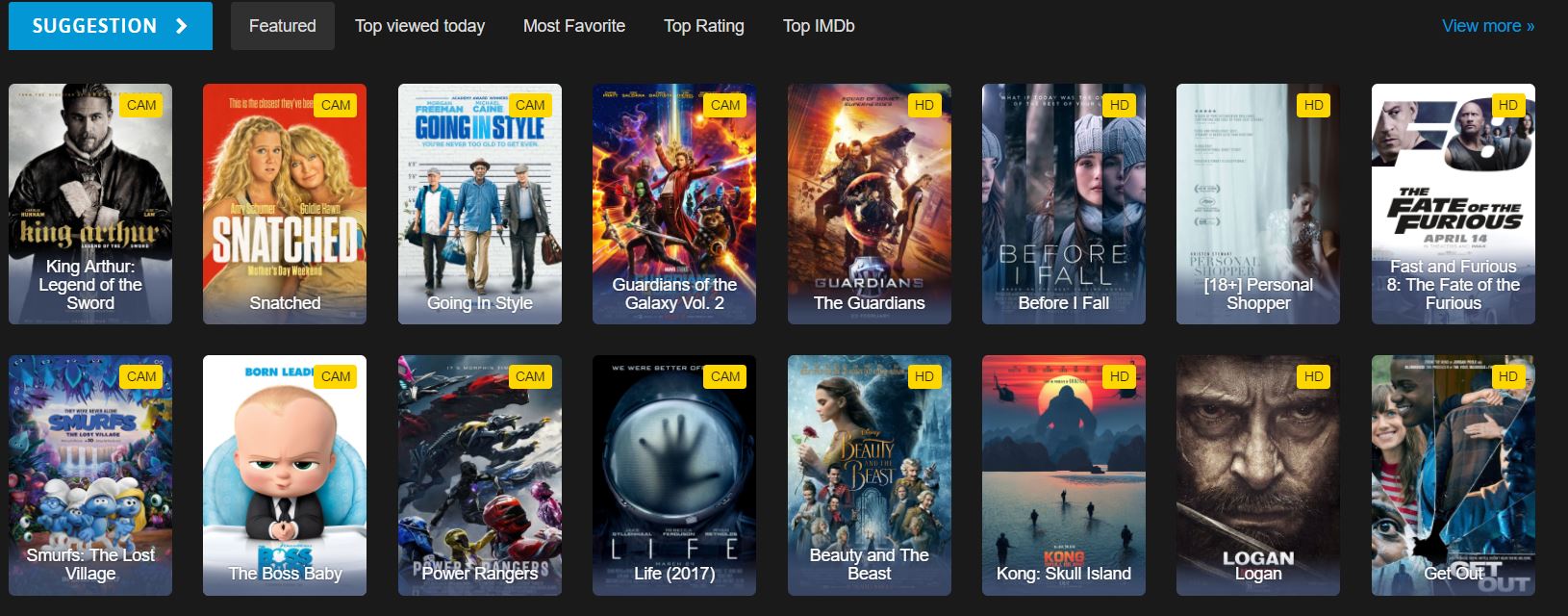
Welche HTML-Elemente enthalten Filmdaten?
Dies ist ein Teil der HTML-Homepage, die wir auf der Website sehen. Die Untersuchung der HTML-Struktur hilft dabei, die richtigen CSS-Selektoren zu identifizieren:
<div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div><div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div>Wir haben eine Film-ID, einen Titel und einen Link zu einer Detailseite. Jeder Film wird in einem div Element mit der Klasse ml-item enthalten und enthält ein einzigartiges data-movie-id Attribut zur Identifizierung.
Wie implementiere ich grundlegendes Movie Scraping?
Beginnen Sie mit dem Scrapen dieses Datensatzes. Bevor Sie einen Scraper ausführen, stellen Sie sicher, dass Sie Ihren Lizenzschlüssel richtig konfiguriert haben, wie unten gezeigt:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("www.website.com", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"))
Dim link = div.Css("a")(0)
Dim movieTitle = link.TextContentClean
' Scrape and store movie data as key-value pairs
Scrape(New ScrapedData() From {
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
},
"Movie.Jsonl")
End If
Next div
End Sub
End ClassWozu dient die Eigenschaft Arbeitsverzeichnis?
Was ist neu in diesem Code?
Die Working Directory Eigenschaft legt das Hauptarbeitsverzeichnis für alle gescrapten Daten und zugehörigen Dateien fest. Dadurch wird sichergestellt, dass alle Ausgabedateien an einem einzigen Ort organisiert sind, was die Verwaltung umfangreicher Scraping-Projekte erleichtert. Das Verzeichnis wird automatisch erstellt, wenn es noch nicht existiert.
Wann sollte ich CSS-Selektoren gegenüber Attributen verwenden?
Zusätzliche Überlegungen:
CSS-Selektoren sind ideal, um Elemente anhand ihrer strukturellen Position oder ihrer Klassennamen anzusprechen, während der direkte Zugriff auf Attribute besser geeignet ist, um bestimmte Werte wie IDs oder benutzerdefinierte Datenattribute zu extrahieren. In unserem Beispiel verwenden wir CSS-Selektoren (#movie-featured > div), um die DOM-Struktur zu navigieren und Attribute (data-movie-id), um spezifische Werte zu extrahieren.
Wie erstelle ich typisierte Objekte für gescrapte Daten?
Erstellen Sie typisierte Objekte, um gescrapte Daten in formatierten Objekten zu speichern. Die Verwendung von stark typisierten Objekten bietet eine bessere Codeorganisation, IntelliSense-Unterstützung und Typüberprüfung während der Kompilierung.
Implementieren Sie eine Movie Klasse, die formatierte Daten umfasst:
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
End ClassWie kann die Verwendung typisierter Objekte die Datenorganisation verbessern?
Aktualisieren Sie den Code, um die typisierte Movie Klasse anstelle des generischen ScrapedData Dictionaries zu verwenden:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://website.com/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Scrape and store movie object
Scrape(movie, "Movie.Jsonl")
End If
Next div
End Sub
End ClassWelches Format verwendet die Scrape-Methode für typisierte Objekte?
Was ist neu?
- Wir haben eine
MovieKlasse implementiert, um gescrapte Daten zu speichern, die Typensicherheit und bessere Codeorganisation bietet. - Wir übergeben Filmobjekte an die
ScrapeMethode, die unser Format versteht und es auf die unten gezeigte Weise speichert:

Die Ausgabe wird automatisch in das JSON-Format serialisiert, so dass sie leicht in Datenbanken oder andere Anwendungen importiert werden kann.
Wie kann ich detaillierte Filmseiten scrapen?
Beginnen Sie mit dem Scannen detaillierterer Seiten. Das Scraping von mehreren Seiten ist eine häufige Anforderung, und IronWebScraper macht dies durch seinen Mechanismus zur Verkettung von Anfragen einfach.
Welche zusätzlichen Daten kann ich aus Detailseiten extrahieren?
Die Filmseite sieht wie folgt aus und enthält umfangreiche Metadaten zu jedem Film:

<div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div><div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>Wie sollte ich meine Filmklasse um zusätzliche Eigenschaften erweitern?
Erweitern Sie die Movie Klasse mit neuen Eigenschaften (Description, Genre, Actor, Director, Country, Duration, IMDb Score), verwenden Sie jedoch nur Description, Genre und Actor für dieses Beispiel. Die Verwendung von List<string> für Genre und Schauspieler ermöglicht eine elegante Handhabung mehrerer Werte:
using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}Imports System.Collections.Generic
Public Class Movie
Public Property Id() As Integer
Public Property Title() As String
Public Property URL() As String
Public Property Description() As String
Public Property Genre() As List(Of String)
Public Property Actor() As List(Of String)
End ClassWie kann ich beim Scraping zwischen den Seiten navigieren?
Navigieren Sie zu der detaillierten Seite, um sie zu scrapen. IronWebScraper behandelt Threadsicherheit automatisch, sodass mehrere Seiten gleichzeitig verarbeitet werden können.
Warum mehrere Parse-Funktionen für verschiedene Seitentypen verwenden?
IronWebScraper ermöglicht das Hinzufügen mehrerer Scrape-Funktionen, um verschiedene Seitenformate zu verarbeiten. Diese Trennung von Belangen macht Ihren Code wartungsfreundlicher und ermöglicht einen angemessenen Umgang mit unterschiedlichen Seitenstrukturen. Jede Parse-Funktion kann sich auf die Extraktion von Daten aus einem bestimmten Seitentyp konzentrieren.
Wie helfen MetaDaten bei der Übergabe von Objekten zwischen Parse-Funktionen?
Die MetaData Funktion ist entscheidend für die Beibehaltung des Zustands zwischen Anfragen. Weitere erweiterte Webscraping-Funktionen finden Sie in unserem ausführlichen Leitfaden:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://domain/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Request detailed page
Me.Request(movie.URL, AddressOf ParseDetails, New MetaData() From {
{ "movie", movie }
})
End If
Next div
End Sub
Public Sub ParseDetails(ByVal response As Response)
' Retrieve movie object from metadata
Dim movie = response.MetaData.Get(Of Movie)("movie")
Dim div = response.Css("div.mvic-desc")(0)
' Extract description
movie.Description = div.Css("div.desc")(0).TextContentClean
' Extract genres
movie.Genre = New List(Of String)() ' Initialize genre list
For Each genre In div.Css("div > p > a")
movie.Genre.Add(genre.TextContentClean)
Next genre
' Extract actors
movie.Actor = New List(Of String)() ' Initialize actor list
For Each actor In div.Css("div > p:nth-child(2) > a")
movie.Actor.Add(actor.TextContentClean)
Next actor
' Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl")
End Sub
End ClassWas sind die Hauptmerkmale dieses Multi-Page-Scraping-Ansatzes?
Was ist neu?
- Fügen Sie Scrape-Funktionen hinzu (z. B.
ParseDetails), um detaillierte Seiten zu scrapen, ähnlich den Techniken, die beim Scraping von einer Einkaufs-Website verwendet werden. - Verschieben Sie die
ScrapeFunktion, die Dateien generiert, in die neue Funktion, um sicherzustellen, dass Daten erst nach dem Sammeln aller Details gespeichert werden. - Verwenden Sie die IronWebScraper Funktion (
MetaData), um Filmobjekte an neue Scrape-Funktionen zu übergeben und den Objektstatus über Anfragen hinweg beizubehalten. - Scrapen Sie Seiten und speichern Sie Filmobjektdaten in Dateien mit vollständigen Informationen.

Weitere Informationen zu den verfügbaren Methoden und Eigenschaften finden Sie in der API-Referenz. IronWebScraper bietet ein robustes Framework für die Extraktion strukturierter Daten aus Websites und ist damit ein unverzichtbares Werkzeug für Datenerfassungs- und Analyseprojekte.
Häufig gestellte Fragen
Wie kann ich mit C# Filmtitel aus HTML extrahieren?
IronWebscraper bietet CSS-Selektor-Methoden, um Filmtitel aus HTML zu extrahieren. Verwenden Sie die response.Css()-Methode mit geeigneten Selektoren wie '.movie-item h2', um auf Titelelemente zu zielen, und greifen Sie dann auf die TextContentClean-Eigenschaft zu, um den sauberen Textwert zu erhalten.
Wie kann man am besten zwischen mehreren Filmseiten navigieren?
IronWebscraper verarbeitet die Seitennavigation über die Request()-Methode. Sie können Paginierungslinks mit CSS-Selektoren extrahieren und dann Request() mit jeder URL aufrufen, um Daten von mehreren Seiten zu scrapen und so automatisch umfassende Filmdatensätze zu erstellen.
Wie kann ich gescrapte Filmdaten in einem strukturierten Format speichern?
Verwenden Sie die Scrape()-Methode von IronWebscraper, um Daten im JSON-Format zu speichern. Erstellen Sie anonyme Objekte oder typisierte Klassen, die Filmeigenschaften wie Titel, URL und Bewertung enthalten, und übergeben Sie diese dann zusammen mit einem Dateinamen an Scrape(), um die Daten automatisch zu serialisieren und zu speichern.
Welche CSS-Selektoren sollte ich verwenden, um Filminformationen zu extrahieren?
IronWebScraper unterstützt Standard-CSS-Selektoren. Für Film-Websites sollten Selektoren wie '.movie-item' für Container, 'h2' für Titel, 'a[href]' für Links und spezifische Klassennamen für Bewertungen oder Genres verwendet werden. Die Methode Css() gibt Sammlungen zurück, durch die Sie iterieren können.
Wie gehe ich mit Filmqualitätsindikatoren wie "CAM" in gescrapten Daten um?
IronWebscraper ermöglicht es Ihnen, Qualitätsindikatoren zu extrahieren und zu verarbeiten, indem Sie deren spezifische HTML-Elemente anvisieren. Verwenden Sie CSS-Selektoren, um Qualitätsplaketten oder Text zu finden, und fügen Sie diese dann als Eigenschaften in Ihre gescrapten Datenobjekte ein, um umfassende Filminformationen zu erhalten.
Kann ich eine Protokollierung für meine Film-Scraping-Vorgänge einrichten?
Ja, IronWebscraper enthält eine integrierte Protokollierungsfunktion. Setzen Sie die Eigenschaft LoggingLevel in Ihrer Init()-Methode auf LogLevel.All, um alle Scraping-Aktivitäten, Fehler und den Fortschritt zu verfolgen, was bei der Fehlersuche und Überwachung Ihrer Filmdatenextraktion hilft.
Wie konfiguriert man Arbeitsverzeichnisse für gescrapte Daten richtig?
IronWebscraper lässt Sie eine WorkingDirectory-Eigenschaft in der Init()-Methode festlegen. Geben Sie einen Pfad wie 'C:\MovieData\Output\' an, in dem die gescrapten Filmdateien gespeichert werden sollen. Dies zentralisiert das Output-Management und hält Ihre Daten organisiert.
Wie erbe ich richtig von der WebScraper-Klasse?
Erstellen Sie eine neue Klasse, die von der WebScraper-Basisklasse von IronWebScraper erbt. Überschreiben Sie die Methode Init() für die Konfiguration und die Methode Parse() für die Datenextraktionslogik. Dieser objektorientierte Ansatz macht Ihren Movie Scraper wiederverwendbar und wartbar.


Scrollst du immer noch?
Sie brauchen schnell einen Beweis? PM > Install-Package IronWebScraper
Führen Sie ein Beispiel aus und beobachten Sie, wie Ihre Zielsite zu strukturierten Daten wird.










