


C# OCR Image to Text Tutorial: Convert Images to Text Without Tesseract
¿Buscas convertir imágenes a texto en C# sin las complicaciones de configuraciones complejas de Tesseract? Este completo tutorial de IronOCR en C# te muestra cómo implementar un potente reconocimiento óptico de caracteres en tus aplicaciones .NET con solo unas pocas líneas de código.
Guía rápida: Extraer texto de una imagen en una sola línea
Este ejemplo muestra lo fácil que es entender IronOCR: solo una línea de C# convierte tu imagen en texto. Demuestra la inicialización del motor de OCR y cómo leer y recuperar texto de inmediato sin una configuración compleja.
-
Instala IronOCR con el Administrador de Paquetes NuGet
-
Copie y ejecute este fragmento de código.
string text = new IronTesseract().Read("image.png").Text; -
Despliegue para probar en su entorno real
Comienza a usar IronOCR en tu proyecto hoy mismo con una prueba gratuita

Flujo de trabajo mínimo (5 pasos)
- Descargue IronOCR: la biblioteca de OCR de C# para la conversión de imágenes a texto
- Utilice la clase
IronTesseractpara leer texto de imágenes al instante - Aplicar filtros de imagen para mejorar la precisión del OCR en escaneos de baja calidad
- Procese varios idiomas con paquetes de idiomas descargables
- Exportar resultados como archivos PDF con capacidad de búsqueda o extraer cadenas de texto
¿Cómo leo texto de imágenes en aplicaciones .NET?
Para lograr la funcionalidad de OCR de imagen a texto en C# en tus aplicaciones .NET, necesitarás una biblioteca OCR confiable. IronOCR proporciona una solución gestionada utilizando la clase IronOcr.IronTesseract que maximiza tanto la precisión como la velocidad sin requerir dependencias externas.
Primero, instala IronOCR en tu proyecto de Visual Studio. Puedes descargar el DLL de IronOCR directamente o usar el Administrador de paquetes NuGet.
Install-Package IronOcr
¿Por qué elegir IronOCR para OCR en C# sin Tesseract?
Cuando necesitas convertir imágenes a texto en C#, IronOCR ofrece ventajas significativas sobre las implementaciones tradicionales de Tesseract:
- Funciona inmediatamente en entornos .NET puros
- No necesita instalación o configuración de Tesseract
- Ejecuta los motores más recientes: Tesseract 5 (además de Tesseract 4 y 3)
- Compatible con .NET Framework 4.6.2+, .NET Standard 2+ y .NET Core 2, 3, 5, 6, 7, 8, 9 y 10
- Mejora la precisión y la velocidad comparado con Tesseract sin modificar
- Soporta implementaciones en Xamarin, Mono, Azure, y Docker
- Gestiona diccionarios complejos de Tesseract a través de paquetes NuGet
- Maneja PDFs, TIFFs de múltiples cuadros y todos los formatos de imagen principales automáticamente
- Corrige escaneos de baja calidad y torcidos para obtener resultados óptimos
¿Cómo usar el tutorial de C# de IronOCR para OCR básico?
Este ejemplo de C# usando Iron Tesseract demuestra la manera más simple de leer texto de una imagen con IronOCR. La clase IronOcr.IronTesseract extrae texto y lo devuelve como una cadena.
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-3.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageindices);
input.Deskew(); // removes rotation and perspective
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
Private pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.LowQuality.tiff", pageindices)
input.Deskew() ' removes rotation and perspective
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)Este código extrae texto limpio de imágenes de alta calidad, exactamente como aparece:
IronOCR Simple Example
In this simple example we test the accuracy of our C# OCR library to read text from a PNG Image. This is a very basic test, but things will get more complicated as the tutorial continues.
The quick brown fox jumps over the lazy dogLa clase IronTesseract maneja internamente operaciones complejas de OCR. Escanea automáticamente para alineación, optimiza la resolución y utiliza inteligencia artificial para leer texto de imagen usando IronOCR.
A pesar del sofisticado procesamiento que ocurre detrás de escenas, que incluye análisis de imagen, optimización del motor y reconocimiento inteligente de texto, el proceso de OCR sigue siendo eficiente.
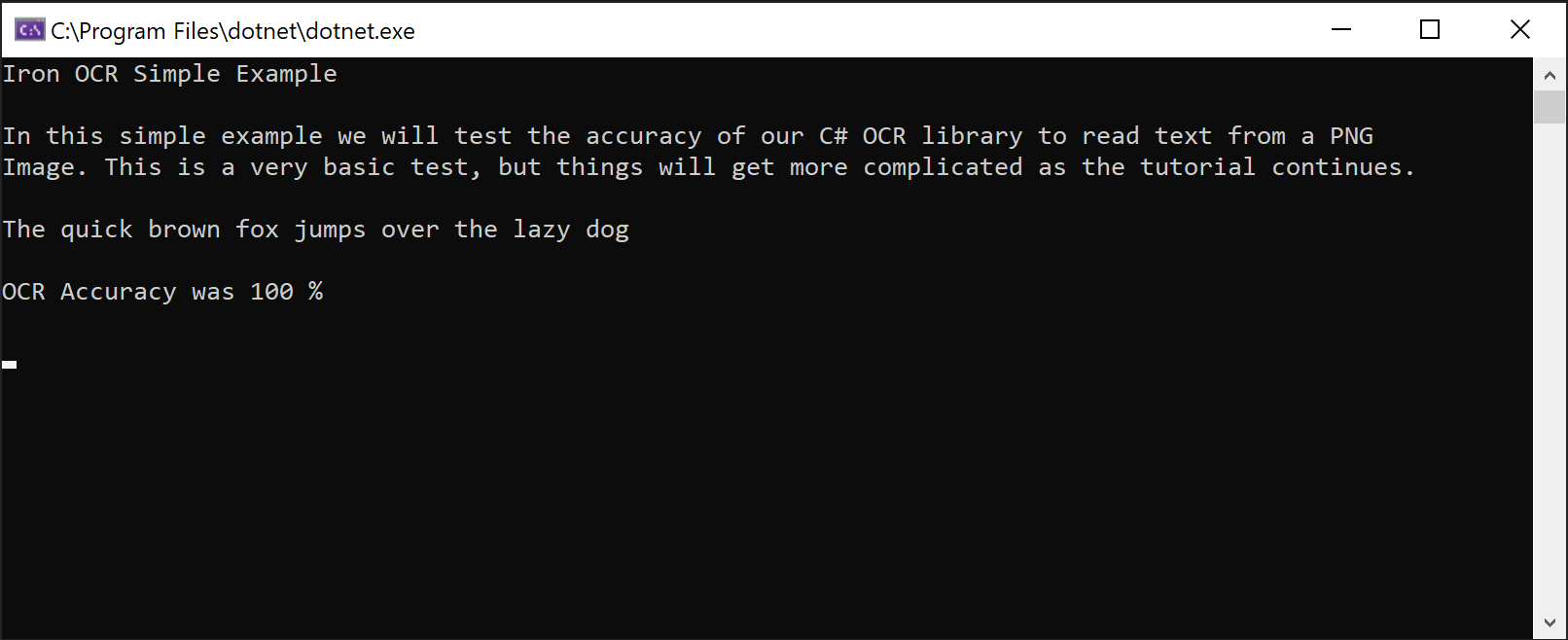 Captura de pantalla demostrando la capacidad de IronOCR para extraer texto de una imagen PNG
Captura de pantalla demostrando la capacidad de IronOCR para extraer texto de una imagen PNG
¿Cómo implementar OCR avanzado en C# sin la configuración de Tesseract?
Para aplicaciones de producción que requieren un rendimiento óptimo al convertir imágenes a texto en C#, utilice las clases OcrInput y IronTesseract juntas. Este enfoque proporciona un control detallado sobre el proceso de OCR.
Características de la clase OcrInput
- Procesa múltiples formatos de imagen: JPEG, TIFF, GIF, BMP, PNG
- Importa páginas completas de PDFs o páginas específicas
- Mejora el contraste, la resolución y la calidad de la imagen automáticamente
- Corrige rotación, ruido de escaneo, desvíos e imágenes negativas
Características de la clase IronTesseract
- Acceso a más de 127 idiomas preconfigurados
- Incluye motores Tesseract 5, 4 y 3
- Especificación del tipo de documento (captura de pantalla, fragmento o documento completo)
- Capacidades de lectura de códigos de barras integradas
- Múltiples formatos de salida: PDFs buscables, HOCR HTML, objetos DOM, y cadenas
¿Cómo empezar con OcrInput y IronTesseract?
Aquí está una configuración recomendada para este tutorial de IronOCR en C# que funciona bien con la mayoría de los tipos de documentos:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-5.csusing IronOcr;
using IronSoftware.Drawing;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
// restrict OCR to a content area for faster processing
Rectangle contentArea = new Rectangle(x: 215, y: 1250, height: 280, width: 1335);
input.LoadImage("img/ComSci.png", contentArea);
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Imports IronSoftware.Drawing
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' restrict OCR to a content area for faster processing
Dim contentArea As New Rectangle(x:=215, y:=1250, height:=280, width:=1335)
input.LoadImage("img/ComSci.png", contentArea)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End UsingEsta configuración logra consistentemente una precisión casi perfecta en escaneos de calidad media. El método LoadImageFrames maneja eficientemente documentos de varias páginas, lo que lo hace ideal para escenarios de procesamiento por lotes.

Documento TIFF de muestra que demuestra las capacidades de extracción de texto de varias páginas de IronOCR
La capacidad de leer texto de imágenes y códigos de barras en documentos escaneados como TIFFs muestra cómo IronOCR simplifica tareas de OCR complejas. La biblioteca sobresale con documentos del mundo real, manejando sin problemas TIFFs de múltiples páginas y extracción de texto de PDFs.
¿Cómo gestiona IronOCR los escaneos de baja calidad?

Documento de baja resolución con ruido que IronOCR puede procesar con precisión utilizando filtros de imagen
Al trabajar con escaneos imperfectos que contienen distorsión y ruido digital, IronOCR supera a otras bibliotecas OCR de C#. Está diseñado específicamente para escenarios del mundo real en lugar de imágenes de prueba prístinas.
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-6.cs// PM> Install IronOcr.Languages.Arabic
using IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using OcrInput input = new OcrInput();
input.LoadImageFrame("img/arabic.gif", 1);
// add image filters if needed
// In this case, even thought input is very low quality
// IronTesseract can read what conventional Tesseract cannot.
OcrResult result = ocr.Read(input);
// Console can't print Arabic on Windows easily.
// Let's save to disk instead.
result.SaveAsTextFile("arabic.txt");' PM> Install IronOcr.Languages.Arabic
Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.Arabic
Using input As New OcrInput()
input.LoadImageFrame("img/arabic.gif", 1)
' add image filters if needed
' In this case, even thought input is very low quality
' IronTesseract can read what conventional Tesseract cannot.
Dim result As OcrResult = ocr.Read(input)
' Console can't print Arabic on Windows easily.
' Let's save to disk instead.
result.SaveAsTextFile("arabic.txt")
End UsingUsando Input.Deskew(), la precisión mejora significativamente en escaneos de baja calidad, casi igualando los resultados de alta calidad. Esto demuestra por qué IronOCR es la elección preferida para OCR en C# sin complicaciones de Tesseract.
Los filtros de imagen pueden aumentar ligeramente el tiempo de procesamiento pero reducen significativamente la duración total del OCR. Encontrar el equilibrio correcto depende de la calidad de tu documento.
Para la mayoría de los escenarios, Input.Deskew() y Input.DeNoise() proporcionan mejoras confiables en el rendimiento de OCR. Aprende más sobre técnicas de preprocesamiento de imagen.
¿Cómo optimizar el rendimiento y la velocidad del OCR?
El factor más significativo que afecta la velocidad del OCR al convertir imágenes a texto en C# es la calidad de entrada. Un DPI más alto (~200 dpi) con ruido mínimo produce los resultados más rápidos y precisos.
Aunque IronOCR se destaca en corregir documentos imperfectos, esta mejora requiere tiempo de procesamiento adicional.
Elige formatos de imagen con artefactos mínimos de compresión. TIFF y PNG generalmente brindan resultados más rápidos que JPEG debido a un menor ruido digital.
¿Qué filtros de imagen mejoran la velocidad del OCR?
Los siguientes filtros pueden mejorar dramáticamente el rendimiento en tu flujo de trabajo de imagen a texto en OCR de C#:
OcrInput.Rotate(double degrees): Rota imágenes en el sentido de las agujas del reloj (negativo para sentido contrario)OcrInput.Binarize(): Convierte a blanco/negro, mejorando el rendimiento en escenarios de bajo contrasteOcrInput.ToGrayScale(): Convierte a escala de grises para posibles mejoras de velocidadOcrInput.Contrast(): Ajusta automáticamente el contraste para mejor precisiónOcrInput.DeNoise(): Elimina artefactos digitales cuando se espera ruidoOcrInput.Invert(): Invierte colores para texto blanco sobre negroOcrInput.Dilate(): Expande los límites del textoOcrInput.Erode(): Reduce los límites del textoOcrInput.Deskew(): Corrige la alineación; esencial para documentos inclinadosOcrInput.Despeckle(): Eliminación agresiva de ruidoOcrInput.EnhanceResolution: Mejora la calidad de imagen de baja resoluciónOcrInput.DetectPageOrientation(): Detecta y corrige la rotación de página. Pase unOrientationDetectionModepara controlar el equilibrio entre precisión y velocidad:Fast,Balanced,Detailed, oExtremeDetailed(añadido v2025.8.6)
Scale() y EnhanceResolution() son incompatibles con SaveAsSearchablePdf() debido a un problema conocido en v2025.12.3. Todos los demás filtros funcionan correctamente con la salida PDF con capacidad de búsqueda.
¿Cómo configurar IronOCR para obtener la máxima velocidad?
Usa estas configuraciones para optimizar la velocidad al procesar escaneos de alta calidad:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-7.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.ChineseSimplified;
// We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Optionally add custom tesseract .traineddata files by specifying a file path
using OcrInput input = new OcrInput();
input.LoadImage("img/MultiLanguage.jpeg");
OcrResult result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.ChineseSimplified
' We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English)
' Optionally add custom tesseract .traineddata files by specifying a file path
Using input As New OcrInput()
input.LoadImage("img/MultiLanguage.jpeg")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsTextFile("MultiLanguage.txt")
End UsingEsta configuración optimizada mantiene una alta precisión mientras mejora la velocidad de procesamiento en comparación con la configuración predeterminada.
¿Cómo leer áreas específicas de imágenes usando C# OCR?
El ejemplo de C# Iron Tesseract a continuación muestra cómo enfocar regiones específicas usando System.Drawing.Rectangle. Esta técnica es invaluable para procesar formularios estandarizados donde el texto aparece en ubicaciones predecibles.
¿Puede IronOCR procesar regiones recortadas para obtener resultados más rápidos?
Usando coordenadas basadas en píxeles, puedes limitar el OCR a áreas específicas, mejorando dramáticamente la velocidad y evitando la extracción de texto no deseado:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-8.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", pageindices);
OcrResult result = ocr.Read(input);
Console.WriteLine($"{result.Pages.Length} Pages"); // 3 PagesImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("image3.gif", pageindices)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine($"{result.Pages.Length} Pages") ' 3 PagesEste enfoque dirigido mejora la velocidad de procesamiento mientras extrae solo el texto relevante. Es ideal para documentos estructurados como facturas, cheques y formularios. La misma técnica de recorte funciona sin problemas con operaciones de PDF OCR.
 Documento demostrando extracción precisa de texto basada en región usando la selección de rectángulo de IronOCR
Documento demostrando extracción precisa de texto basada en región usando la selección de rectángulo de IronOCR
¿Cuántos idiomas admite IronOCR?
IronOCR ofrece 127 idiomas internacionales a través de prácticos paquetes de idiomas. Descárgalos como DLLs desde nuestro sitio web o a través del Administrador de paquetes NuGet.
Instala paquetes de idiomas a través de la interfaz de NuGet (busca "IronOcr.Languages") o visita el listado completo de paquetes de idioma.
Los idiomas soportados incluyen árabe, chino (simplificado/tradicional), japonés, coreano, hindi, ruso, alemán, francés, español y más de 115 otros, cada uno optimizado para el reconocimiento preciso de texto.
¿Cómo implementar OCR en varios idiomas?
Este ejemplo de tutorial de IronOCR en C# demuestra el reconocimiento de texto en árabe:
Install-Package IronOcr.Languages.Arabic

IronOCR extrae con precisión texto árabe de una imagen GIF
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-10.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadPdf("example.pdf", Password: "password");
// We can also select specific PDF page numbers to OCR
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Length} Pages");
// 1 page for every page of the PDFImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadPdf("example.pdf", Password:= "password")
' We can also select specific PDF page numbers to OCR
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
Console.WriteLine($"{result.Pages.Length} Pages")
' 1 page for every page of the PDF¿Puede IronOCR gestionar documentos con múltiples idiomas?
Cuando los documentos contienen idiomas mixtos, configura IronOCR para soporte multilingüe:
Install-Package IronOcr.Languages.ChineseSimplified
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-12.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Metadata Name";
input.LoadPdf("example.pdf", Password: "password");
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Metadata Name"
input.LoadPdf("example.pdf", Password:= "password")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")¿Cómo procesar documentos de varias páginas con C# OCR?
IronOCR combina perfectamente múltiples páginas o imágenes en un único OcrResult. Esta función habilita capacidades poderosas como crear PDFs buscables y extraer texto de conjuntos de documentos completos.
Mezcla y combina varias fuentes - imágenes, marcos de TIFF y páginas de PDF - en una sola operación de OCR:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-13.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Title";
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Title"
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")Procesa todas las páginas de un archivo TIFF de manera eficiente:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-14.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Html Title";
// Add more content as required...
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf",Password: "password");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Html Title"
' Add more content as required...
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf",Password:= "password")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")Convierte TIFFs o PDFs a formatos buscables:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-15.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
input.LoadImage("img/Barcode.png");
OcrResult result = ocr.Read(input);
foreach (var barcode in result.Barcodes)
{
Console.WriteLine(barcode.Value);
// type and location properties also exposed
}Imports IronOcr
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
input.LoadImage("img/Barcode.png")
Dim result As OcrResult = ocr.Read(input)
For Each barcode In result.Barcodes
Console.WriteLine(barcode.Value)
' type and location properties also exposed
Next barcode
End UsingConvierte PDFs existentes a versiones buscables:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-16.csusing IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageindices);
OcrResult result = ocr.Read(input);
foreach (var page in result.Pages)
{
// Page object
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// null if we don't set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap(input);
System.Drawing.Bitmap pageImageLegacy = page.ToBitmap(input);
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int paragraphNumber = paragraph.ParagraphNumber;
String paragraphText = paragraph.Text;
System.Drawing.Bitmap paragraphImage = paragraph.ToBitmap(input);
int paragraphXLocation = paragraph.X;
int paragraphYLocation = paragraph.Y;
int paragraphWidth = paragraph.Width;
int paragraphHeight = paragraph.Height;
double paragraphOcrAccuracy = paragraph.Confidence;
var paragraphTextDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int lineNumber = line.LineNumber;
String lineText = line.Text;
AnyBitmap lineImage = line.ToBitmap(input);
System.Drawing.Bitmap lineImageLegacy = line.ToBitmap(input);
int lineXLocation = line.X;
int lineYLocation = line.Y;
int lineWidth = line.Width;
int lineHeight = line.Height;
double lineOcrAccuracy = line.Confidence;
double lineSkew = line.BaselineAngle;
double lineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int wordNumber = word.WordNumber;
String wordText = word.Text;
AnyBitmap wordImage = word.ToBitmap(input);
System.Drawing.Image wordImageLegacy = word.ToBitmap(input);
int wordXLocation = word.X;
int wordYLocation = word.Y;
int wordWidth = word.Width;
int wordHeight = word.Height;
double wordOcrAccuracy = word.Confidence;
if (word.Font != null)
{
// Word.Font is only set when using Tesseract Engine Modes rather than LTSM
String fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isFixedWidth = word.Font.IsFixedWidth;
bool isItalic = word.Font.IsItalic;
bool isSerif = word.Font.IsSerif;
bool isUnderlined = word.Font.IsUnderlined;
bool fontIsCaligraphic = word.Font.IsCaligraphic;
}
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int characterNumber = character.CharacterNumber;
String characterText = character.Text;
AnyBitmap characterImage = character.ToBitmap(input);
System.Drawing.Bitmap characterImageLegacy = character.ToBitmap(input);
int characterXLocation = character.X;
int characterYLocation = character.Y;
int characterWidth = character.Width;
int characterHeight = character.Height;
double characterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spell checking
OcrResult.Choice[] characterChoices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
For Each page In result.Pages
' Page object
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' null if we don't set Ocr.Configuration.ReadBarCodes = true;
Dim barcodes() As OcrResult.Barcode = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap(input)
Dim pageImageLegacy As System.Drawing.Bitmap = page.ToBitmap(input)
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphImage As System.Drawing.Bitmap = paragraph.ToBitmap(input)
Dim paragraphXLocation As Integer = paragraph.X
Dim paragraphYLocation As Integer = paragraph.Y
Dim paragraphWidth As Integer = paragraph.Width
Dim paragraphHeight As Integer = paragraph.Height
Dim paragraphOcrAccuracy As Double = paragraph.Confidence
Dim paragraphTextDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim lineNumber As Integer = line.LineNumber
Dim lineText As String = line.Text
Dim lineImage As AnyBitmap = line.ToBitmap(input)
Dim lineImageLegacy As System.Drawing.Bitmap = line.ToBitmap(input)
Dim lineXLocation As Integer = line.X
Dim lineYLocation As Integer = line.Y
Dim lineWidth As Integer = line.Width
Dim lineHeight As Integer = line.Height
Dim lineOcrAccuracy As Double = line.Confidence
Dim lineSkew As Double = line.BaselineAngle
Dim lineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim wordNumber As Integer = word.WordNumber
Dim wordText As String = word.Text
Dim wordImage As AnyBitmap = word.ToBitmap(input)
Dim wordImageLegacy As System.Drawing.Image = word.ToBitmap(input)
Dim wordXLocation As Integer = word.X
Dim wordYLocation As Integer = word.Y
Dim wordWidth As Integer = word.Width
Dim wordHeight As Integer = word.Height
Dim wordOcrAccuracy As Double = word.Confidence
If word.Font IsNot Nothing Then
' Word.Font is only set when using Tesseract Engine Modes rather than LTSM
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isFixedWidth As Boolean = word.Font.IsFixedWidth
Dim isItalic As Boolean = word.Font.IsItalic
Dim isSerif As Boolean = word.Font.IsSerif
Dim isUnderlined As Boolean = word.Font.IsUnderlined
Dim fontIsCaligraphic As Boolean = word.Font.IsCaligraphic
End If
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim characterNumber As Integer = character.CharacterNumber
Dim characterText As String = character.Text
Dim characterImage As AnyBitmap = character.ToBitmap(input)
Dim characterImageLegacy As System.Drawing.Bitmap = character.ToBitmap(input)
Dim characterXLocation As Integer = character.X
Dim characterYLocation As Integer = character.Y
Dim characterWidth As Integer = character.Width
Dim characterHeight As Integer = character.Height
Dim characterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spell checking
Dim characterChoices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next page
End UsingAplica la misma técnica a las conversiones de TIFF:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-17.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Configure document properties
input.Title = "Scanned Archive Document";
// Select pages to process
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Create searchable PDF from TIFF
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Configure document properties
input.Title = "Scanned Archive Document"
' Select pages to process
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Create searchable PDF from TIFF
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")
End Using¿Cómo exportar resultados de OCR como HTML HOCR?
IronOCR soporta la exportación de HOCR HTML, permitiendo conversiones estructuradas de PDF a HTML y TIFF a HTML mientras preserva la información de diseño:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-18.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set HTML title
input.Title = "Document Archive";
// Process multiple document types
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf", "password");
// Add TIFF pages
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Export as HOCR with position data
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Set HTML title
input.Title = "Document Archive"
' Process multiple document types
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf", "password")
' Add TIFF pages
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Export as HOCR with position data
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")
End Using¿Puede IronOCR leer códigos de barras junto con texto?
IronOCR combina de manera única el reconocimiento de texto con capacidades de lectura de códigos de barras, eliminando la necesidad de bibliotecas separadas:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-19.cs// Enable combined text and barcode recognition
using IronOcr;
var ocr = new IronTesseract();
// Enable barcode detection
ocr.Configuration.ReadBarCodes = true;
using (var input = new OcrInput())
{
// Load image containing both text and barcodes
input.LoadImage("img/Barcode.png");
// Process both text and barcodes
var result = ocr.Read(input);
// Extract barcode data
foreach (var barcode in result.Barcodes)
{
Console.WriteLine($"Barcode Value: {barcode.Value}");
Console.WriteLine($"Format: {barcode.Format}");
}
}
Imports IronOcr
Dim ocr As New IronTesseract()
' Enable barcode detection
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
' Load image containing both text and barcodes
input.LoadImage("img/Barcode.png")
' Process both text and barcodes
Dim result = ocr.Read(input)
' Extract barcode data
For Each barcode In result.Barcodes
Console.WriteLine($"Barcode Value: {barcode.Value}")
Console.WriteLine($"Format: {barcode.Format}")
Next
End Using¿Cómo acceder a resultados detallados de OCR y metadatos?
El objeto de resultados de IronOCR proporciona datos comprensivos que los desarrolladores avanzados pueden aprovechar para aplicaciones sofisticadas.
Cada OcrResult contiene colecciones jerárquicas: páginas, párrafos, líneas, palabras y caracteres. Todos los elementos incluyen metadatos detallados como ubicación, información de fuente, y puntuaciones de confianza.
Los elementos individuales (párrafos, palabras, códigos de barras) pueden ser exportados como imágenes o bitmaps para procesamiento adicional:
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-20.csusing System;
using IronOcr;
using IronSoftware.Drawing;
// Configure with barcode support
IronTesseract ocr = new IronTesseract
{
Configuration = { ReadBarCodes = true }
};
using OcrInput input = new OcrInput();
// Process multi-page document
int[] pageIndices = { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
OcrResult result = ocr.Read(input);
// Navigate the complete results hierarchy
foreach (var page in result.Pages)
{
// Page-level data
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// Extract page elements
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap();
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Paragraph properties
int paragraphNumber = paragraph.ParagraphNumber;
string paragraphText = paragraph.Text;
double paragraphConfidence = paragraph.Confidence;
var textDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Line details including baseline information
string lineText = line.Text;
double lineConfidence = line.Confidence;
double baselineAngle = line.BaselineAngle;
double baselineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Word-level data
string wordText = word.Text;
double wordConfidence = word.Confidence;
// Font information (when available)
if (word.Font != null)
{
string fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isItalic = word.Font.IsItalic;
}
foreach (var character in word.Characters)
{
// Character-level analysis
string charText = character.Text;
double charConfidence = character.Confidence;
// Alternative character choices for spell-checking
OcrResult.Choice[] alternatives = character.Choices;
}
}
}
}
}
Imports System
Imports IronOcr
Imports IronSoftware.Drawing
' Configure with barcode support
Dim ocr As New IronTesseract With {
.Configuration = New TesseractConfiguration With {
.ReadBarCodes = True
}
}
Using input As New OcrInput()
' Process multi-page document
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("img\Potter.tiff", pageIndices)
Dim result As OcrResult = ocr.Read(input)
' Navigate the complete results hierarchy
For Each page In result.Pages
' Page-level data
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' Extract page elements
Dim barcodes As OcrResult.Barcode() = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap()
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Paragraph properties
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphConfidence As Double = paragraph.Confidence
Dim textDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Line details including baseline information
Dim lineText As String = line.Text
Dim lineConfidence As Double = line.Confidence
Dim baselineAngle As Double = line.BaselineAngle
Dim baselineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Word-level data
Dim wordText As String = word.Text
Dim wordConfidence As Double = word.Confidence
' Font information (when available)
If word.Font IsNot Nothing Then
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isItalic As Boolean = word.Font.IsItalic
End If
For Each character In word.Characters
' Character-level analysis
Dim charText As String = character.Text
Dim charConfidence As Double = character.Confidence
' Alternative character choices for spell-checking
Dim alternatives As OcrResult.Choice() = character.Choices
Next
Next
Next
Next
Next
End UsingResumen
IronOCR proporciona a los desarrolladores de C# la implementación más avanzada del API Tesseract, funcionando sin problemas en plataformas Windows, Linux y Mac. Su capacidad de leer texto de imágenes utilizando IronOCR - incluso de documentos imperfectos - lo distingue de las soluciones básicas de OCR.
Las características únicas de la biblioteca incluyen lectura de códigos de barras integrada y la capacidad de exportar resultados como PDFs buscables o HOCR HTML, capacidades no disponibles en implementaciones estándar de Tesseract.
Avanzando
Para continuar dominando IronOCR:
- Explora nuestra completa guía de inicio
- Explora ejemplos prácticos de código en C#
- Consulta la documentación de API detallada
Descargar código fuente
¿Listo para implementar la conversión de OCR de imagen a texto en C# en tus aplicaciones? Descarga IronOCR y comienza tu prueba gratuita hoy.
Preguntas Frecuentes
¿Cómo puedo convertir imágenes a texto en C# sin usar Tesseract?
Puedes usar IronOCR para convertir imágenes a texto en C# sin necesidad de Tesseract. IronOCR simplifica el proceso con métodos integrados que manejan la conversión de imagen a texto directamente.
¿Cómo mejoro la precisión del OCR en imágenes de baja calidad?
IronOCR proporciona filtros de imagen como Input.Deskew() y Input.DeNoise() que se pueden usar para mejorar imágenes de baja calidad corrigiendo la inclinación y reduciendo el ruido, mejorando así significativamente la precisión del OCR.
¿Cuáles son los pasos para extraer texto de un documento de varias páginas usando OCR en C#?
Para extraer texto de documentos de varias páginas, IronOCR te permite cargar y procesar cada página usando métodos como LoadPdf() para PDFs o files TIFF, convirtiendo efectivamente cada página a texto.
¿Es posible leer códigos de barras y texto simultáneamente desde una imagen?
Sí, IronOCR puede leer tanto texto como códigos de barras de una sola imagen. Puedes habilitar la lectura de códigos de barras con ocr.Configuration.ReadBarCodes = true, lo que permite la extracción tanto de datos de texto como de código de barras.
¿Cómo puedo configurar OCR para procesar documentos en varios idiomas?
IronOCR soporta más de 125 idiomas y te permite establecer un idioma principal usando ocr.Language y agregar idiomas adicionales con ocr.AddSecondaryLanguage() para el procesamiento de documentos multilingües.
¿Qué métodos están disponibles para exportar resultados de OCR en diferentes formatos?
IronOCR ofrece varios métodos para exportar resultados de OCR, como SaveAsSearchablePdf() para PDFs, SaveAsTextFile() para texto plano y SaveAsHocrFile() para formato HOCR HTML.
¿Cómo puedo optimizar la velocidad de procesamiento de OCR para archivos de imagen grandes?
Para optimizar la velocidad de procesamiento de OCR, usa el OcrLanguage.EnglishFast de IronOCR para un reconocimiento de idioma más rápido y define regiones específicas para OCR usando System.Drawing.Rectangle para reducir el tiempo de procesamiento.
¿Cómo manejo el procesamiento de OCR para archivos PDF protegidos?
Al tratar con PDFs protegidos, usa el método LoadPdf() junto con la contraseña correcta. IronOCR maneja PDFs basados en imágenes convirtiendo páginas a imágenes automáticamente para procesamiento OCR.
¿Qué debo hacer si los resultados de OCR no son exactos?
Si los resultados de OCR son inexactos, considera usar las funciones de mejora de imagen de IronOCR como Input.Deskew() y Input.DeNoise(), y asegúrate de que los paquetes de idiomas correctos estén instalados.
¿Puedo personalizar el proceso de OCR para excluir ciertos caracteres?
Sí, IronOCR permite la personalización del proceso de OCR utilizando la propiedad BlackListCharacters para excluir caracteres específicos, mejorando la precisión y la velocidad de procesamiento al centrarse solo en el texto relevante.



¿Aún desplazándote?
¿Quieres una prueba rápida? PM > Install-Package IronOcr
ejecuta una muestra y observa cómo tu imagen se convierte en texto buscable.










