









在實際環境中進行測試
在生產環境中測試,無浮水印。
無論您在哪裡需要,它都能運作。

using IronOcr;
string imageText = new IronTesseract().Read(@"images\image.png").Text;Imports IronOcr
Private imageText As String = (New IronTesseract()).Read("images\image.png").TextInstall-Package IronOcr
IronOCR 具備獨特能力,能自動偵測並讀取來自掃描品質不佳的圖像及 PDF 文件中的文字。 IronTesseract 類別提供了最簡單的 API。
嘗試其他程式碼範例,以精細控制您的 C# OCR 操作。
IronOCR 提供目前已知最先進的 Tesseract 版本,適用於任何平台,具備更快的速度、更高的精準度,並包含原生 DLL 及 API。
支援 Tesseract 3、Tesseract 4 及 Tesseract 5 版本,適用於 .NET Framework、.NET Standard、Core、Xamarin 及 Mono。
IronTesseract 實例以使用直觀的 APIRead 方法執行 OCRText 屬性取得 OCR 結果using IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR 支援 125 種國際語言。 除了預設安裝的英文外,您可透過 NuGet 將其他語言套件新增至您的 .NET 專案,或從我們的語言頁面下載。 多數語言皆提供 IronOCR 語言支援
Standard(建議)及 Best 品質等級。 Best 品質選項雖能提供更精準的結果,但處理時間也會較長。
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR 會針對其掃描的每一頁,使用 Tesseract 5\ 返回一個進階結果物件。 此內容包含位置資料、圖片、文字、統計置信度、替代符號選項、字型名稱、字型大小、裝飾效果、字型粗細,以及各項的相對位置:
PageParagraphWordBarcode

IronOCR(光學字元辨識)程式庫能讓開發人員在將圖像轉換為文字時,獲得快速且高效的成果。IronOCR 支援 .NET、VB .NET 及 C#。我們專為 .NET Framework 打造的頂級 .NET 應用程式,是專為您——開發人員——設計,以協助您在專案中實現最佳效能。
OCR 能接收並辨識文字檔案、BarCode、QR 碼內容等。此外,IronOCR 還提供多種方法,讓您能將 OCR 讀取功能及圖像文字整合至網頁、Windows 桌面或主控台 .NET 專案中,並支援幾乎無限的圖像格式與檔案類型,例如 JPG、PNG、GIF、TIFF、BMP、JPEG 或 PDF。
儘管從影像輸出中識別純文字、字元、行與段落的結果看似複雜,但您會發現,IronOCR 背後的運作機制其實比您最初想像的更為簡單。 IronOCR 會掃描圖像以進行對齊,並運用其雜訊去除與濾鏡功能來檢查品質與解析度。它會檢視圖像屬性、優化 OCR 引擎,並使用經過訓練的人工智慧網路,進而像人類一樣精準地識別(圖像中的)文字。
即使對電腦而言,OCR 也不是一個簡單的過程。然而,IronOCR 讓建立可搜尋文件的整體流程變得更快、更直觀,不僅準確度達 100%,且僅需極少的程式碼。
閱讀教學指南
軟體不受地理邊界的限制——企業的營運跨越國界,並仰賴多種語言來達成目標。同樣地,一款僅能對單一語言進行文件辨識的光學字元辨識(OCR)工具,在各方面都是絕對不可接受的!
透過具備多種 OCR 功能的跨語言 OCR 函式庫,您將能從多語言的掃描 PDF 或掃描圖像(從法語到中文!)中,建立可搜尋的 PDF 文件。動態且支援文字搜尋的 PDF 文件能有效節省您的時間與精力,讓您、您的客戶或您的組織都能無限制地使用與重複利用。
IronOCR程式庫以您、您的業務及 OCR 需求為核心,無論是內建功能或客製化需求,皆支援廣泛的語言。您的下一個 .NET 專案將不再受限於語言相容性的困擾!
無論是阿拉伯語、西班牙語、法語、德語、希伯來語、義大利語、日語、簡體中文、繁體中文(普通話)、丹麥語、英語、芬蘭語、葡萄牙語、俄語、西班牙語或瑞典語,您只需說出語言名稱,我們便能為您提供!您可以下載您偏好的語言套件,或聯繫我們的 24/7 支援服務以獲取更多語言選項。
第一步是使用我們的 NuGet 套件安裝程式,適用於 Windows Visual Studio。
下載語言套件
IronOCR 與競爭對手有何不同?除了讓您輕鬆添加 OCR 功能、擷取文字及掃描旋轉過的影像外,它還能對掃描品質不佳的文件進行 OCR 處理!相較之下,目前市面上許多現成的產品往往僵化且不精準,在實際的個人與企業應用中注定會失敗,因為其中多數僅適用於機器列印、高解析度且調整完美的文字。
IronOCR 透過其強大的 IronTesseract DLL 擴展了 Google Tesseract 的功能——這是一個原生 C# OCR 程式庫,其穩定性與準確度均優於免費的 Tesseract 程式庫。
手握最佳工具,即使您擁有的只是掃描品質欠佳的影像,或是儲存於資料夾中的舊有影像——IronOCR 的影像處理程式庫轉換功能能清除雜訊、旋轉影像、減少變形與傾斜對齊,並提升解析度與對比度。進階的光學字元辨識 (OCR) 設定為您——程式設計師——提供工具與程式碼,讓您一次又一次地產生最佳的可搜尋結果。
搜尋您所需的文字,99.8% 至 100% 的精準結果絕不讓您失望,且支援範圍無遠弗屆:PDF 文件、多幀 TIFF 檔案、JPEG 與 JPEG2000、GIF、PNG、BMP、WBMP、System.Drawing.Image、System.Drawing.Bitmap、System.IO.Streams 影像流、二進位影像資料 (byte[]),以及更多!
Tesseract 的替代方案
與 .NET Framework 中的其他 .NET 應用程式不同,您會發現 IronOCR 套件管理主控台及文字辨識主控台內建的高階光學字元辨識功能,能讓使用者讀取多種字型(從 Times New Roman 到任何花俏或看似難以辨識的字型)、字重及樣式,從而從整張圖片或掃描影像中精準讀取文字。我們能選取圖片特定區域的功能,有助於提升速度與準確度。 從數行到數段落的多執行緒處理,不僅加速了 OCR 引擎的運作,更能在多核心機器上同時讀取多份文件。
我們對速度與精準度的承諾不僅限於字元辨識的過程。事實上,這些改進從安裝階段便已開始,因為 IronOCR 的 .NET OCR 引擎是一款易於安裝、功能完備且文件詳盡的 .NET 軟體函式庫。它提供單一的 NuGet 套件管理器安裝方案,適用於 Visual Studio,並與 MVC、WebApp、桌面、主控台及伺服器應用程式具備多執行緒相容性。
您無需任何外部網路服務、持續性費用,亦無需透過網際網路傳送機密文件,即可達成 99.8% 至 100% 的 OCR 準確度。摒棄繁瑣的 C++ 編碼,當您需要針對多字元、單詞、行、段落、文字及文件提供完整的 PDF OCR 支援時,IronOCR 無疑是您的首選。
對於追求程式碼完善的開發者,我們提供最佳解決方案,因為 IronOCR 開箱即用,完全無需進行效能調校或大幅修改輸入影像。最新版本的 IronOCR 運作速度驚人——比先前版本快達十倍,且錯誤率降低超過 250%。我們持續升級產品,透過提供完美的 OCR 平台來支援您的目標!
查看完整功能清單
即使使用行動裝置,我們完美的 .NET OCR 程式庫也能讓開發人員「無後顧之憂」地編寫程式,因為 IronOCR 支援將內容匯出為一系列簡單或複雜的純文字、機器編碼文字、BarCode 資料,或結構化物件模型資料。您可以將內容拆分為段落、行、單字、字元及圖像字串結果,以便直接在您的 .NET 應用程式中使用。
從原始碼到最終結果 —— 若無法將資料匯出至您的應用程式,這些結果便毫無用處。IronOCR 深知此點,因此允許您將 OCR 結果匯出為 XHTML,以便在更廣泛的應用程式中使用此可持續格式,並能整合至複雜的網站中,更不用說還能加快載入速度!
然而,支援功能不僅止於此。將 OCR 結果匯出為可搜尋 PDF 文件的能力,讓您、您的客戶及組織能輕鬆儲存並在需要時隨時檢索 PDF 文件!當您手邊有一份 30 頁的合約時,這尤其有益——您只需輸入幾個關鍵字即可在資料庫中搜尋,同時也能讓您的公司展現對法規合規的重視,畢竟可搜尋的 PDF 文件已被證實對視障人士大有裨益。
除了上述功能外,您還能將結果匯出為 OCR 格式,該格式包含您的 OCR 輸出內容、版面配置資訊及樣式資訊,並將相關資訊嵌入標準 HTML 中。
了解更多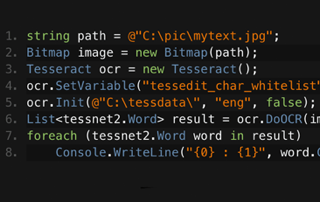
C# Tesseract OCR

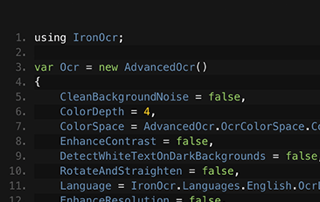
C# OCR ASP.NET






Team Iron 在 .NET 軟體元件市場擁有超過 10 年的經驗。








Install-Package IronOcr
無需信用卡
您的試用金鑰應已寄至您的電子郵件。![]() 試用表單已成功提交
試用表單已成功提交
。
若未收到,請聯絡
support@ironsoftware.com
在生產環境中測試,無浮水印。
無論您在哪裡需要,它都能運作。
立即獲取 30 天完整功能版產品。
幾分鐘內即可完成安裝並開始使用。
在產品試用期間,您可隨時聯繫我們的技術支援團隊
我們產品及其關鍵功能的即時示範
獲取專案特定的功能建議
我們已為您解答所有疑問,確保您獲得所需的所有資訊。(完全無需承擔任何義務。)





預約無義務諮詢

預約 30 分鐘的專屬示範。
無合約、無信用卡資訊、無任何承諾。



