



Teste em um ambiente real
Teste em produção sem marcas d'água.
Funciona onde você precisar.

using IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
O IronOCR suporta 125 idiomas internacionais. Além do inglês, que é instalado por padrão, pacotes de idiomas adicionais podem ser adicionados ao seu projeto .NET via NuGet ou baixados da nossa página de idiomas . A maioria dos idiomas está disponível em qualidade Suporte a idiomas do IronOCR
Fast, Standard (recomendado) e Best. A opção de qualidade Best pode oferecer resultados mais precisos, mas também será mais lenta no tempo de processamento.
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR retorna um objeto de resultado avançado para cada página que escaneia usando Tesseract 5. Isso contém dados de localização, imagens, texto, confiança estatística, escolhas de símbolos alternativos, nomes de fonte, tamanhos de fonte, decoração, pesos de fonte e posição para cada:
PageParagraphWordBarcode
Seja para dúvidas sobre produtos, integração ou licenciamento, a equipe de desenvolvimento de produtos da Iron está à disposição para ajudar com todas as suas perguntas. Entre em contato e inicie um diálogo com a Iron para aproveitar ao máximo nossa biblioteca em seu projeto.
Faça uma pergunta
Sejam páginas de passaporte, faturas, extratos bancários, correspondências, cartões de visita ou recibos, o Reconhecimento Óptico de Caracteres (OCR) é uma área de pesquisa baseada em reconhecimento de padrões, visão computacional e aprendizado de máquina. Empresas utilizam o OCR em diversos departamentos para extrair texto em sistemas de contabilidade e finanças, digitalização de negócios, gerenciamento de conteúdo empresarial e sistemas de geração de relatórios de dados.
Além de construir outras histórias de sucesso , o IronOCR agrega valor ao Google Tesseract e ao Microsoft Azure Cognitive Services 2021 com o IronOCR – uma biblioteca OCR nativa em C#.
Se você busca converter imagens do mundo real com 99% de precisão, continue lendo para descobrir como o IronOCR permite criar um aplicativo de Reconhecimento Óptico de Caracteres (OCR) eficiente, preciso, escalável e quase humano.
O reconhecimento óptico de caracteres (OCR) é considerado um fenômeno consolidado devido à enorme confiança que diferentes APIs depositam na sua proteção. No entanto, os diversos produtos disponíveis são frequentemente rígidos e imprecisos, falhando em aplicações do mundo real. De forma semelhante, o Tesseract OCR funciona com texto impresso em alta resolução e com qualidade perfeita.
Parece bom?
No mundo real, nem sempre temos textos impressos e manuscritos perfeitos e de alta resolução. O IronOCR lida com imperfeições digitais como rotações, distorções, baixa resolução, ruído de fundo e todos os outros problemas, inclusive a extração de texto manuscrito de arquivos de imagem. Garantimos documentos pesquisáveis com precisão de 99,8% a 100% e suporte multiplataforma, incluindo Windows, Linux, macOS, Microsoft Azure, AWS e Docker. Há um motivo pelo qual desenvolvedores C# escolhem o IronOCR em vez do Tesseract OCR (básico): tudo se resume a agregar valor.
Equipe-se com o melhor!
Além disso, o IronOCR permite processar documentos de imagem rapidamente. E não para por aí: a API do IronOCR também inclui os seguintes recursos:
Transição da instalação de arquivos .dll ou .exe nativos para uma única fonte de verdade — desenvolva usando uma única biblioteca de componentes .NET nativa com APIs C# simples que oferecem suporte a:
A arte da API IronOCR não termina aí; você pode continuar explorando nossos recursos técnicos de ponta. Reduzimos as complexidades dos negócios, um passo de cada vez, desenvolvendo soluções confiáveis para otimizar aplicativos de processamento de documentos e maximizar a receita, oferecendo recursos líderes do setor incorporados:
Nosso processo de reconhecimento óptico de caracteres começa com o pré-processamento automatizado de imagens, aprimorando o arquivo de imagem e melhorando a taxa de resposta da extração. O IronOCR agrega valor ao seu trabalho, permitindo que os usuários extraiam o arquivo de imagem base de exemplo para a versão ideal do mesmo. O IronOCR abrange todas as necessidades:
Como o serviço IronOCR funciona de forma otimizada em arquivos de imagem de 300 DPI (pontos por polegada), qualquer imagem que esteja significativamente fora da faixa de 200-300 DPI é redimensionada para se ajustar ao intervalo desejado.
Isso significa reduzir a resolução de imagens de 600 DPI para 300 DPI ou aumentar a resolução de imagens de 100 DPI para 200 DPI com 99% de confiança.
Como os serviços cognitivos do IronOCR são projetados para funcionar com imagens monocromáticas, quaisquer imagens coloridas ou em tons de cinza são convertidas em monocromáticas, utilizando um algoritmo de binarização adaptativo.
O algoritmo compara as densidades de pixels dentro de uma área para determinar o limite a ser usado na conversão de pixels em monocromáticos.
O IronOCR procura linhas de texto e padrões de caracteres para corrigir automaticamente a inclinação e girar as imagens de entrada para a orientação desejada.
Com o IronOCR, os arquivos de imagem são analisados automaticamente para detectar a presença e a quantidade de ruído. O ruído consiste basicamente nos "pontos" encontrados nas imagens digitalizadas. Nosso algoritmo adaptativo remove o ruído com base no tamanho das partículas.
Assim que o arquivo de imagem de amostra é pré-processado, o IronOCR divide o arquivo de imagem de entrada em diferentes zonas de processamento.
Outra etapa de pré-preparação envolve a divisão da imagem de referência em diferentes zonas lógicas. O IronOCR primeiro localiza o texto e as imagens dentro da imagem com a ajuda de espaços em branco e padrões; a região de texto é separada das imagens.
Em seguida, o texto é dividido em zonas – parágrafos, colunas e blocos de texto. As imagens e os pixels restantes que não constituem texto são identificados para serem omitidos durante o reconhecimento de texto e incluídos na saída inteligente. O IronOCR então sinaliza as zonas de texto como tabelas com a ajuda de linhas de grade e blocos de texto.
Executa várias etapas interconectadas que convertem aglomerados de pixels em linhas de texto que os usuários podem pesquisar. Isso inclui segmentação de caracteres, classificação adaptativa, consultas a dicionários e outros processos relacionados que contribuem para a extração do texto ideal.
Com o serviço de API IronOCR, testamos nossa ferramenta por meio de diversos exemplos de arquivos de dados em vários idiomas, incluindo níveis de palavras, precisão de símbolos e preservação de layout em formatos do Microsoft Office. Embora alguns parâmetros sejam testados automaticamente, outros incluem verificações visuais.
O IronOCR permite adicionar recursos de OCR multiplataforma com vários formatos de entrada a uma string de texto simples que você pode pesquisar. Para aumentar sua produtividade com o IronOCR, comece com nossa documentação tutorial gratuita que o guiará pelo uso do IronOCR. Baixe nosso instalador de pacote NuGet hoje mesmo e explore com uma chave de avaliação gratuita ou entre em contato com nosso suporte personalizado 24 horas por dia, 7 dias por semana. Expanda suas necessidades com nosso licenciamento vitalício, independentemente do tamanho da sua equipe.
Ver licençasLicenças gratuitas para desenvolvimento comunitário. Licenças comerciais a partir de US$ 749.





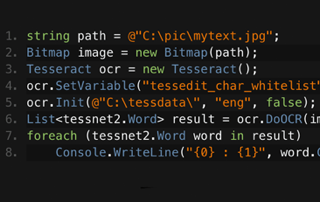
C# Tesseract OCR

Jim tem sido uma figura fundamental no desenvolvimento do IronOCR. Ele projeta e constrói algoritmos de processamento de imagem e métodos de leitura para OCR.
Veja a comparação.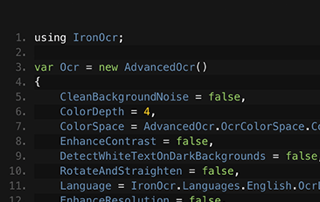
C# OCR ASP.NET

Aprenda como a equipe de Gemma usa o IronOCR para ler texto de imagens para seu software de arquivamento. Gemma compartilha seus próprios exemplos de código.
Tutorial .NET de conversão de imagem em texto




A equipe da Iron possui mais de 10 anos de experiência no mercado de componentes de software .NET.








Install-Package IronOcr

Não é necessário cartão de crédito.
Sua chave de avaliação deve estar no e-mail.![]() O formulário de inscrição para o teste foi enviado.
O formulário de inscrição para o teste foi enviado.
Com sucesso .
Caso contrário, entre em contato.
support@ironsoftware.com
Não é necessário cartão de crédito.
Teste em produção sem marcas d'água.
Funciona onde você precisar.
Receba 30 dias de produto totalmente funcional.
Deixe-o pronto para usar em minutos.
Acesso total à nossa equipe de suporte técnico durante o período de teste do produto.
Uma demonstração ao vivo do nosso produto e suas principais funcionalidades.
Receba recomendações de funcionalidades específicas para o seu projeto.
Todas as suas dúvidas serão respondidas para garantir que você tenha todas as informações necessárias. (Sem qualquer compromisso.)





Agende uma consulta sem compromisso.

Preencha o formulário abaixo ou envie um e-mail para sales@ironsoftware.com
Os seus dados serão sempre mantidos em sigilo.

Agende uma demonstração personalizada de 30 minutos.
Sem contrato, sem necessidade de dados de cartão, sem compromissos.


