

Cómo crear un servicio Azure OCR con IronOCR
Iron Software ha creado una biblioteca de OCR (reconocimiento óptico de caracteres) que elimina los problemas de interoperabilidad de la integración de OCR en Azure. Trabajar con bibliotecas OCR en Azure siempre ha sido un poco pesado para los desarrolladores. La solución para éste y muchos otros quebraderos de cabeza del OCR es IronOCR.
Funciones de IronOCR para Microsoft Azure
IronOCR incluye las siguientes características para crear un servicio OCR en Microsoft Azure:
- Convierte los PDF en documentos en los que se pueden realizar búsquedas para extraer texto fácilmente
- Convierte imágenes en documentos que permiten búsquedas extrayendo texto de las imágenes
- Lee códigos de barras y códigos QR
- Precisión excepcional
- Se ejecuta localmente y no requiere SaaS (Software como Servicio), que es un modelo de distribución de software en el que un proveedor de nube, como Microsoft Azure, aloja varias aplicaciones y las pone a disposición de los usuarios finales.
Velocidad de vértigo
Veamos cómo el mejor motor de OCR, IronOCR de Iron Software, facilita a los desarrolladores la extracción de texto de cualquier documento de entrada.
Empecemos con nuestro servicio Azure OCR
Para empezar con el ejemplo, primero tenemos que instalar IronOCR.
Crear una nueva aplicación de consola con C#
Instale IronOCR a través de NuGet, ya sea introduciendo: Install-Package IronOcr o seleccionando Manage NuGet packages y buscando IronOCR. Se muestra a continuación
- Edite su archivo Program.cs para que tenga el siguiente aspecto:
- Importamos el espacio de nombres IronOcr para hacer uso de sus capacidades ocr para leer y extraer el contenido del archivo PDF.
- Creamos un nuevo objeto IronTesseract, para poder extraer texto de una imagen.
using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string [] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); //Read PNG image File
Console.WriteLine(result.Text); //Write Output to PDF document
Console.ReadLine();
}
}
}
}using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string [] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); //Read PNG image File
Console.WriteLine(result.Text); //Write Output to PDF document
Console.ReadLine();
}
}
}
}Imports IronOcr
Imports System
Namespace IronOCR_Ex
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim ocr = New IronTesseract()
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim result = ocr.Read(Input) 'Read PNG image File
Console.WriteLine(result.Text) 'Write Output to PDF document
Console.ReadLine()
End Using
End Sub
End Class
End NamespaceA continuación, abrimos una imagen llamada Purgatorio.PNG. Esta imagen forma parte de la Comedia divina de Dante, uno de mis libros favoritos. La imagen se parece a la siguiente.

Figura 2 - El texto que se va a extraer con las capacidades de lectura óptica de caracteres de IronOCR
La salida después de que el texto anterior se ha extraído del texto de la imagen de entrada anterior.
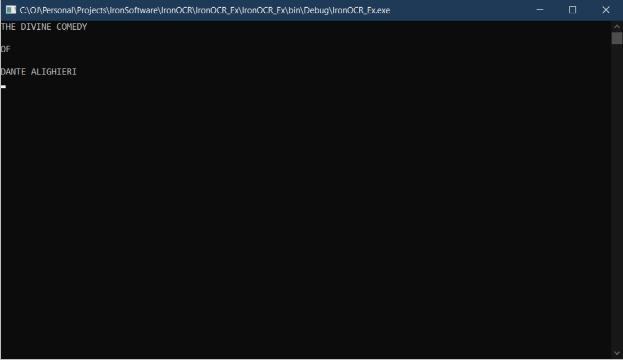
Figura 3 - Texto extraído
Hagamos lo mismo con un documento PDF. El documento PDF contiene el mismo texto a extraer que la Figura.
La única diferencia es que seremos un documento PDF en lugar de una imagen. Introduce el siguiente código:
var Ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; //Give title to input document
//Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var Result = Ocr.Read(input); //Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
} var Ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; //Give title to input document
//Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var Result = Ocr.Read(input); //Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
}Dim Ocr = New IronTesseract()
Using input = New OcrInput()
input.Title = "Divine Comedy - Purgatory" 'Give title to input document
'Supply optional password and name of document
input.AddPdf("..\Documents\Purgatorio.pdf", "dante")
Dim Result = Ocr.Read(input) 'Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf")
End UsingCasi igual que el código anterior que extrae texto de una imagen.
Aquí hacemos uso del método OcrInput para leer el documento PDF actual, en este caso: Purgatorio.pdf. Si hay metadatos en el archivo PDF, como un título o una contraseña, también podemos introducirlos.
El resultado se guarda como un documento PDF en el que podemos buscar texto.
Tenga en cuenta que si el archivo PDF es demasiado grande, puede producirse una excepción.
Suficiente en aplicaciones Windows; veamos cómo podemos utilizar ocr con Microsoft Azure.
Lo bueno de IronOCR es que funciona muy bien con Microsoft Azure como Azure Function en una arquitectura de microservicios. He aquí un ejemplo muy rápido de lo que sería una función de Microsoft Azure que trabaja con IronOCR. Esta función de Microsoft Azure extrae texto de imágenes.
public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query ["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query ["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} Public Module OCRFunction
Public hcClient As New HttpClient()
<FunctionName("IronOCRFunction_EX")>
Public Async Function Run(<HttpTrigger> ByVal hrRequest As HttpRequest, ByVal ecContext As ExecutionContext) As Task(Of IActionResult)
Dim URI = hrRequest.Query ("image")
Dim saStream = Await hcClient.GetStreamAsync(URI)
Dim ocr = New IronTesseract()
Using inputOCR = New OcrInput(saStream)
Dim outputOCR = ocr.Read(inputOCR)
Return New OkObjectResult(outputOCR.Text)
End Using
End Function
End ModuleDe este modo, la imagen recibida por la función se envía directamente al motor ocr para que la emita como texto extraído.
Un breve resumen sobre Microsoft Azure.
Según Microsoft: Microsoft Azure Microservices es un enfoque arquitectónico para construir aplicaciones donde cada función central, o servicio, se construye y despliega de forma independiente. La arquitectura de microservicios está distribuida y poco acoplada, por lo que el fallo de un componente no romperá toda la aplicación. Los componentes independientes trabajan juntos y se comunican con contratos de API bien definidos. Cree aplicaciones de microservicios para satisfacer las necesidades empresariales en rápida evolución y comercializar nuevas funcionalidades con mayor rapidez.
Algunas características más de IronOCR con .NET o Microsoft Azure son las siguientes:
La capacidad de realizar ocr en casi cualquier archivo, imagen o PDF.
- Procesamiento ultrarrápido de entradas ocr
- Precisión excepcional
- Lee códigos de barras y códigos QR
- Se ejecuta localmente, sin necesidad de SaaS
- Puede convertir PDF e imágenes en documentos con capacidad de búsqueda
- Excelente alternativa a Azure OCR de Microsoft Cognitive Services
Filtros de imagen para mejorar el rendimiento del OCR
- OcrInput.Rotate - Rota imágenes varios grados en el sentido de las agujas del reloj. Para rotar en sentido antihorario, utilice números negativos.
- OcrInput.Binarize() - Este filtro de imagen convierte cada píxel en negro o blanco sin términos medios. Esto mejora el rendimiento del OCR.
- OcrInput.ToGrayScale() - Este filtro de imagen convierte cada píxel en un tono de escala de grises. Esto mejora la velocidad de OCR
- OcrInput.Contrast() - Aumenta el contraste automáticamente. Este filtro mejora la velocidad de ocr y la precisión en exploraciones de bajo contraste.
- OcrInput.DeNoise() - Elimina el ruido digital. Este filtro solo debe usarse cuando se espera ruido en los documentos de entrada.
- OcrInput.Invert() - Invierte todos los colores.
- OcrInput.Dilate() - La dilatación añade píxeles a los límites de cualquier objeto en una imagen.
- OcrInput.Erode() - La erosión elimina píxeles en los bordes de los objetos.
- OcrInput.Deskew() - Rota una imagen para que esté en la dirección correcta y sea ortogonal. Esto resulta muy útil para el OCR, ya que la tolerancia de Tesseract para los escaneados sesgados puede ser de tan sólo 5 grados.
- OcrInput.DeepCleanBackgroundNoise() - Eliminación intensa de ruido de fondo.
- OcrInput.EnhanceResolution - Mejora la resolución de una imagen de baja calidad.
Velocidad
A continuación, un ejemplo:
var Ocr = new IronTesseract();
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][
\\";
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
Ocr.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
} var Ocr = new IronTesseract();
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][
\\";
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
Ocr.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}Dim Ocr = New IronTesseract()
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][ \\"
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly
Ocr.Language = OcrLanguage.EnglishFast
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim Result = Ocr.Read(Input)
Console.WriteLine(Result.Text)
End UsingPrecios y licencias
Existen esencialmente tres niveles de licencias de pago que funcionan con un principio de compra única, licencia de por vida.
Y sí, son gratuitos para fines de desarrollo.
Para más información
- Recursos adicionales se pueden encontrar en el siguiente enlace: Recursos
- Las referencias de la API se pueden encontrar aquí: Referencias de la API
- El soporte para los productos de IronOCR se puede encontrar aquí: Soporte
- Contactar con Iron Software: Información de contacto
Funciones de IronOCR para aplicaciones .NET que ejecutan OCR en Azure y otros sistemas
IronOCR admite 127 idiomas internacionales. Cada idioma está disponible en calidad Rápida, Estándar y Óptima. Algunos de los paquetes de idiomas disponibles son:
Búlgaro
Armenio
Croata
Afrikaans
Danés
Checa
Filipino
En finés
Francés
- Alemán
- Hay muchos más paquetes de idiomas disponibles, para echarles un vistazo, siga el siguiente enlace. Paquetes de idioma de IronOCR
Funciona directamente en .NET
Compatibilidad con Xamarin
Soporte para Mono
Compatibilidad con Microsoft Azure
Soporte para Docker en Microsoft Azure
Admite documentos PDF
- Admite archivos Tiff Multiframe
- Compatible con los principales formatos de imagen
Se admiten los siguientes marcos .NET:
.NET Framework 4.5 y superior
.NET Estándar 2
.NET Core 2
- .NET Core 3
- .NET Core 5
No necesita tener Tesseract (un motor OCR de código abierto que admite Unicode y más de 100 idiomas) instalado para que IronOCR funcione.
- Ha mejorado la precisión con respecto a Tesseract
- Ha mejorado la velocidad con respecto a Tesseract
- Corrige los escaneados de baja calidad de documentos o archivos
- Corrige los escaneados sesgados de baja calidad de documentos o archivos
¿Qué es el reconocimiento óptico de caracteres (OCR)?
Según Wikipedia: El reconocimiento óptico de caracteres es la conversión electrónica o mecánica de imágenes de texto mecanografiado e impreso en texto codificado por máquina, ya sea a partir de un documento escaneado, de una foto de un documento, de una foto de escena o de un texto de subtítulos superpuesto a una imagen. Ocr son las siglas en inglés de Reconocimiento Óptico de Caracteres. Existen esencialmente cuatro tipos de reconocimiento óptico de caracteres, que son:
- OCR - Reconocimiento Óptico de Caracteres, que se dirige a texto mecanografiado de un documento de entrada, un carácter o glifo (símbolo elemental dentro de un conjunto acordado de símbolos, por ejemplo, 'a' en diferentes fuentes) a la vez.
- OWR - Optical Word Recognition (Reconocimiento óptico de palabras), que se centra en el texto mecanografiado a partir de un documento de entrada, palabra por palabra.
- ICR - Reconocimiento Inteligente de Caracteres, que se dirige al texto impreso, como el texto en letra de molde (caracteres sin unión a otras letras) y el texto en cursiva, un carácter o glifo a la vez
- IWR - Reconocimiento Inteligente de Palabras, que se centra en el texto cursivo.






