



Test in a live environment
Test in production without watermarks.
Works wherever you need it to.

using IronOcr;
string imageText = new IronTesseract().Read(@"images\image.png").Text;Imports IronOcr
Private imageText As String = (New IronTesseract()).Read("images\image.png").TextInstall-Package IronOcr
IronOCR is unique in its ability to automatically detect and read text from imperfectly scanned images and PDF documents. The IronTesseract class provides the simplest API.
Try other code samples to gain fine-grained control of your C# OCR operations.
IronOCR provides the most advanced build of Tesseract known anywhere, on any platform, with increased speed, accuracy, and a native DLL and API.
Supports Tesseract 3, Tesseract 4, and Tesseract 5 for .NET Framework, Standard, Core, Xamarin, and Mono.
IronTesseract to use intuitive APIsRead method to perform OCR in VB.NETText propertyusing IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR supports 125 international languages. Other than English, which is installed by default, additional language packs can be added to your .NET project via NuGet or downloaded from our Languages Page. Most languages are available in IronOCR Language Support
Fast, Standard (recommended), and Best quality. The Best quality option may offer more accurate results, but will also be slower in processing time.
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR returns an advanced result object for each page it scans using Tesseract 5. This contains location data, images, text, statistical confidence, alternative symbol choices, font-names, font-sizes, decoration, font weights, and position for each:
PageParagraphWordBarcode
For product or licensing queries, the Iron team are ready to support you. Send us your questions and we'll ensure the right person at Iron answers it for you.
Get in Touch
One or multi pages can be sent to IronOCR. You'll receive all text, barcode, & QR content as a result. Add OCR functionality to .NET Console, Web, or Desktop Apps. Images can be submitted as PDF, JPG, PNG, GIF, BMP and TIFF.
See a Tutorials
The Optical Character Recognition software views content in multiple font styles for accurate text OCR. Use rectangle read regions to improve speed and accuracy. Multi-core multi threading improves OCR reading speeds.
API Reference Documenation
What really makes IronOCR special is its ability to read badly scanned documents. Its unique pre-processing library reduces background noise, rotation, distortion and skewed alignment as well as simplifying colours and enhancing resolution & contrast. Iron’s AutoOCR and Advanced OCR settings provide developers with the tools to achieve the best possible results, every time.
Learn More
Language packs available for: Arabic, Simplified Chinese, Traditional Chinese, Danish, English, Finnish, French, German, Hebrew, Italian, Japanese, Korean, Portuguese, Russian, Spanish, and Swedish. Other languages can be supported by request.
Learn More
IronOCR outputs content as plain text and barcode data. An alternative structured data object model allows developers to receive all content in the format of structured Headings, Paragraphs, Lines, Words and Characters for input directly into .NET applications.
Learn MoreFree community development licenses. Commercial licenses from $749.





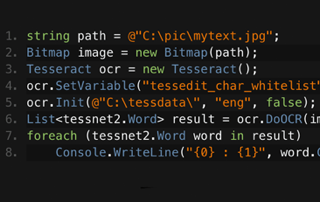
C# Tesseract OCR

Jim has been a leading figure in development of IronOCR. Jim designs and builds image processing algorithms and reading methods for OCR.
See Jim's Tesseract Comparison
C# OCR ASP.NET

Learn how Gemma's team use IronOCR to read text from images for their archiving software. Gemma shares her own code samples.
View Gemma's Image to Text Tutorial




Iron's team have over 10 years experience in the .NET software component market.








Install-Package IronOcr

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
A live demo of our product and its key features
Get project specific feature recommendations
All your questions are answered to make sure you have all the information you need. (No commitment whatsoever.)





Book a No-obligation Consult

Complete the form below or email sales@ironsoftware.com
Your details will always be kept confidential.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


