



Test in a live environment
Test in production without watermarks.
Works wherever you need it to.

using IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR supports 125 international languages. Other than English, which is installed by default, additional language packs can be added to your .NET project via NuGet or downloaded from our Languages Page. Most languages are available in IronOCR Language Support
Fast, Standard (recommended), and Best quality. The Best quality option may offer more accurate results, but will also be slower in processing time.
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR returns an advanced result object for each page it scans using Tesseract 5. This contains location data, images, text, statistical confidence, alternative symbol choices, font-names, font-sizes, decoration, font weights, and position for each:
PageParagraphWordBarcode
Whether it's product, integration or licensing queries, the Iron product development team is on hand to support all of your questions. Get in touch and start a dialog with Iron to make the most of our library in your project.
Ask a Question
Whether it is passport pages, invoices, bank statements, mail, business cards, or receipts; Optical Character Recognition (OCR) is a research field based upon pattern recognition, computer vision, and machine learning. Firms utilize OCR cross-departmentally to extract text in accounting and finance systems, business digitization, enterprise content management, and data reporting systems.
In addition to building other success stories. IronOCR adds value to Google Tesseract and Microsoft 2021 Azure Cognitive Services with IronOCR - a native C# OCR library.
If you are looking to convert real-world pictures with 99 percent accuracy - then read on, to see how IronOCR lets you build an efficient, accurate, scalable, and almost-human Optical Character Recognition application.
Optical Character Recognition (OCR) is considered a solved phenomenon due to the immense confidence different APIs claim towards protection. However, the various products are often rigid and inaccurate that fail in real-world applications. Similarly, Tesseract OCR works with machine-printed, high-resolution, perfect text.
Sounds good?
Only the real world does not always have perfectly printed and handwritten text with high-resolution. Instead, rotated, skewed, low DPI, background noise, and all the banes of digital imperfections are taken care of by IronOCR, including extracting handwritten text from images files. We ensure a 99.8 - 100 percent accurate, searchable document with cross-platform support that includes Windows, Linux, macOS, Microsoft Azure, AWS, and Docker - there is a reason C# developers choose IronOCR over (basic) Tesseract OCR - it is all about adding value.
Equip yourself with the best!
In addition to the above, IronOCR equips you to process image documents promptly. If that's not all, the IronOCR API features also include the following:
Transition from native .dlls or exes installation to a single source of truth - develop using a single, native .NET component library using a simple C# APIs that supports:
The art of IronOCR API does not end there; you can continue to explore our technical edge features further. We reduce the business complexities, one step at a time, by developing reliable solutions to streamline document processing applications and maximizing business revenues by offering industry-leading features have embedded:
Our optical character recognition process begins with automated image pre-processing, to enhance the image file that improves the extraction response rate. IronOCR adds value to your work as it enables the users to extract the example base image file into the optimum version of itself. IronOCR covers all bases:
As IronOCR service works optimally on 300DPI (Dots Per Inch) image files, any image that is significantly outside of 200-300 DPI is resampled to fit inside the targeted range.
This translates down-sampling from 600 DPI images to 300 DPI or up-sampling 100 DPI images to 200 DPI with 99 percent confidence.
As IronOCR cognitive services are designed to function on monochromatic images, any colored or greyscale images are converted to monochromatic, utilizing an adaptive binarization algorithm.
The algorithm compares the pixel densities within an area that determines the threshold to use to convert pixels monochromatic.
IronOCR looks for lines of texts and character patterns to automatically deskew and rotate input image resources to the desired orientation.
With IronOCR, image files are automatically analyzed for the presence and amount of noise. The noise is basically the ‘specks’ found on the scanned images. Our adaptive algorithm then removes the noise based upon the size of noise particles.
As soon as the sample image file is pre-processed, IronOCR then breaks the input image file into different processing zones.
Another pre-preparation stage involves breaking the reference image into different logical zones. IronOCR first locates text and pictures within the image with the help of whitespace, and patterns; the text region is separated from images.
It is then partitioned into zones – paragraphs, columns, and text blocks. The images and remaining non-text pixels are identified to be omitted during text recognition and included in the smart output. IronOCR then flags the text zones as tables with the help of gridlines and text blocks.
Perform multiple, inter-connected steps that convert pixel blobs into single-line text threads that users can search. This includes character segmentation, adaptive classification, dictionary references, and other related processes that contribute towards the optimum extracted text.
With IronOCR API service, we have tested our tool through multiple data files examples in multiple languages that include word levels, symbol accuracy, and layout retention in Microsoft Office formats. Although some parameters are automatically tested; others include visual checks.
IronOCR lets you add OCR cross-platform capabilities with multiple input formats to a plain text string that you can search. To empower your productivity with IronOCR, get started with our free tutorial documentation that guides you through using IronOCR. Download our NuGet package installer today, and explore with a free trial key or connect with 24/7 personal support. Scale your needs with our lifetime licensing, regardless of your team size.
View LicensesFree community development licenses. Commercial licenses from $749.





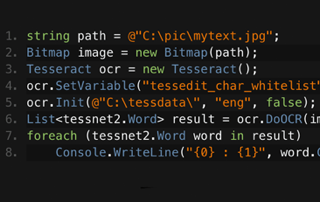
C# Tesseract OCR

Jim has been a leading figure in development of IronOCR. Jim designs and builds image processing algorithms and reading methods for OCR.
See Comparison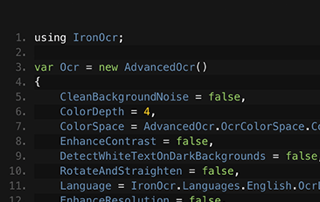
C# OCR ASP.NET

Learn how Gemma's team use IronOCR to read text from images for their archiving software. Gemma shares her own code samples.
Image to Text .NET Tutorial




Iron's team have over 10 years experience in the .NET software component market.








Install-Package IronOcr

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
A live demo of our product and its key features
Get project specific feature recommendations
All your questions are answered to make sure you have all the information you need. (No commitment whatsoever.)





Book a No-obligation Consult

Complete the form below or email sales@ironsoftware.com
Your details will always be kept confidential.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


