


C# OCR Image to Text Tutorial: Convert Images to Text Without Tesseract
複雑な Tesseract 構成の手間をかけずに、C# で画像をテキストに変換したいとお考えですか? この包括的な IronOCR C# チュートリアルでは、わずか数行のコードで .NET アプリケーションに強力な光学式文字認識を実装する方法を説明します。
クイックスタート:1行で画像からテキストを抽出する
この例では、IronOCR を理解するのがいかに簡単かを示しています。たった 1 行の C# で画像がテキストに変換されます。 OCR エンジンを初期化し、複雑な設定なしですぐにテキストを読み取って取得する方法を示します。
最小限のワークフロー(5ステップ)
- IronOCRをダウンロード - 画像からテキストへの変換用C#OCRライブラリ
IronTesseractクラスを使用して画像からテキストを即座に読み取ります- 画像フィルターを適用して、低品質のスキャンの OCR 精度を高めます
- ダウンロード可能な言語パックを使用して複数の言語を処理
- 結果を検索可能なPDFとしてエクスポートするか、テキスト文字列を抽出します
.NET アプリケーションで画像からテキストを読み取るにはどうすればよいでしょうか?
.NET アプリケーションで C# OCR 画像からテキストへの機能を実現するには、信頼性の高い OCR ライブラリが必要です。 IronOCRはIronOcr.IronTesseractクラスを使用して、外部依存なしで最大限の精度と速度を実現する管理されたソリューションを提供します。
まず、Visual Studio プロジェクトに IronOCR をインストールします。 IronOCR DLL を直接ダウンロードするか、 NuGet パッケージ マネージャーを使用することができます。
Install-Package IronOcr
なぜC# OCRにTesseractを使わずにIronOCRを選ぶべきか?
C# で画像をテキストに変換する必要がある場合、IronOCR は従来の Tesseract 実装に比べて大きな利点を提供します。
- 純粋な.NET環境ですぐに動作します
- Tesseractのインストールや設定は不要
- 最新のエンジンを実行: Tesseract 5 (および Tesseract 4 と 3)
- .NET Framework 4.6.2 以降、.NET Standard 2 以降、および .NET Core 2、3、5、6、7、8、9、10 に対応
- バニラのTesseractと比較して精度と速度が向上します
- Xamarin、Mono、Azure、Docker のデプロイメントをサポート
- NuGet パッケージを通じて複雑な Tesseract 辞書を管理します
- PDF、マルチフレームTIFF、およびすべての主要な画像形式を自動的に処理します
- 低品質や歪んだスキャンを補正して最適な結果を実現します
基本的なOCRのためのIronOCR C#チュートリアルを使用する方法?
この Iron Tesseract C# の例では、IronOCR を使用して画像からテキストを読み取る最も簡単な方法を示します。 IronOcr.IronTesseract クラスはテキストを抽出し、文字列として返します。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-3.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageindices);
input.Deskew(); // removes rotation and perspective
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
Private pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.LowQuality.tiff", pageindices)
input.Deskew() ' removes rotation and perspective
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)このコードは鮮明な画像に対して 100% の精度を実現し、表示されているとおりにテキストを抽出します。
IronOCR Simple Example
In this simple example we test the accuracy of our C# OCR library to read text from a PNG Image. This is a very basic test, but things will get more complicated as the tutorial continues.
The quick brown fox jumps over the lazy dogIronTesseract クラスは複雑なOCR操作を内部で処理します。 自動的に位置合わせをスキャンし、解像度を最適化し、AI を使用して IronOCR で人間レベルの精度で画像からテキストを読み取ります。
画像分析、エンジン最適化、インテリジェントなテキスト認識などの高度な処理がバックグラウンドで行われているにもかかわらず、OCR プロセスは人間の読み取り速度に匹敵し、並外れた精度レベルを維持しています。
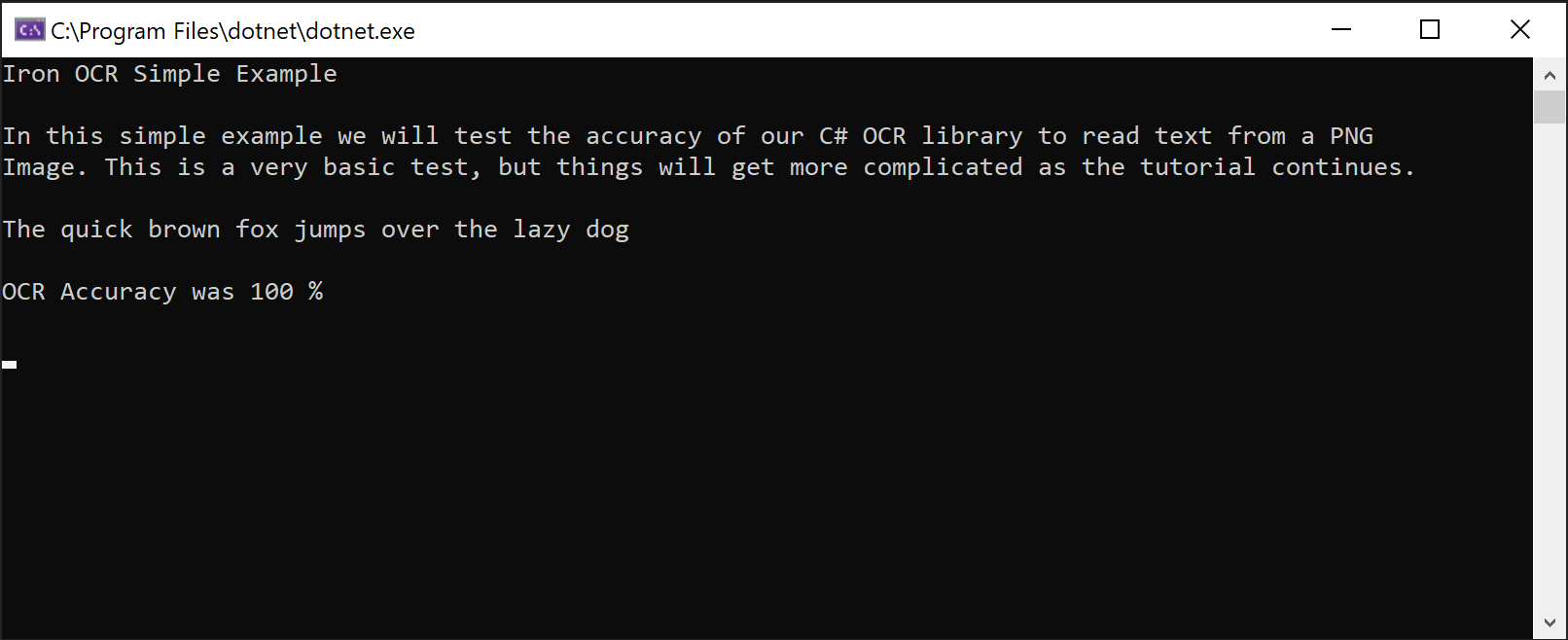 IronOCR が PNG 画像から完璧な精度でテキストを抽出できることを示すスクリーンショット
IronOCR が PNG 画像から完璧な精度でテキストを抽出できることを示すスクリーンショット
Tesseractの設定なしで高度なC# OCRを実装する方法?
C#で画像をテキストに変換する際に最適なパフォーマンスを求める製品アプリケーションに対しては、IronTesseractクラスを一緒に使用してください。 このアプローチにより、OCR プロセスをきめ細かく制御できます。
OcrInput クラスの特長
- 複数の画像形式を処理: JPEG、TIFF、GIF、BMP、PNG
- PDF全体または特定のページをインポートします
- コントラスト、解像度、画質を自動的に向上します
- 回転、スキャンノイズ、傾き、ネガティブイメージを修正します
IronTesseract クラスの特長
- 127以上のプリパッケージされた言語へのアクセス
- Tesseract 5、4、3エンジン搭載
- ドキュメントタイプの指定(スクリーンショット、スニペット、または完全なドキュメント)
- 統合バーコード読み取り機能
- 複数の出力形式: 検索可能なPDF、HOCR HTML、DOMオブジェクト、文字列
IronTesseractで始めましょうか?
ほとんどのドキュメント タイプで適切に機能する、この IronOCR C# チュートリアルの推奨構成は次のとおりです。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-5.csusing IronOcr;
using IronSoftware.Drawing;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
// restrict OCR to a content area for faster processing
Rectangle contentArea = new Rectangle(x: 215, y: 1250, height: 280, width: 1335);
input.LoadImage("img/ComSci.png", contentArea);
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);Imports IronOcr
Imports IronSoftware.Drawing
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' restrict OCR to a content area for faster processing
Dim contentArea As New Rectangle(x:=215, y:=1250, height:=280, width:=1335)
input.LoadImage("img/ComSci.png", contentArea)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End Usingこの構成では、中品質のスキャンでほぼ完璧な精度が一貫して達成されます。 LoadImageFrames メソッドは効率的に複数ページのドキュメントを処理できるため、バッチ処理のシナリオに最適です。

IronOCR の複数ページテキスト抽出機能を示すサンプル TIFF ドキュメント
TIFF などのスキャンされたドキュメント内の画像やバーコードからテキストを読み取る機能は、IronOCR が複雑な OCR タスクをいかに簡素化するかを示しています。 このライブラリは実際のドキュメントに優れており、複数ページの TIFF とPDF テキスト抽出をシームレスに処理します。
IronOCR は低品質のスキャンをどのように処理しますか?

IronOCRが画像フィルターを使用して正確に処理できるノイズのある低解像度の文書
歪みやデジタル ノイズを含む不完全なスキャンを処理する場合、 IronOCR は他の C# OCR ライブラリよりも優れたパフォーマンスを発揮します。 これは、純粋なテスト画像ではなく、現実世界のシナリオ向けに特別に設計されています。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-6.cs// PM> Install IronOcr.Languages.Arabic
using IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using OcrInput input = new OcrInput();
input.LoadImageFrame("img/arabic.gif", 1);
// add image filters if needed
// In this case, even thought input is very low quality
// IronTesseract can read what conventional Tesseract cannot.
OcrResult result = ocr.Read(input);
// Console can't print Arabic on Windows easily.
// Let's save to disk instead.
result.SaveAsTextFile("arabic.txt");' PM> Install IronOcr.Languages.Arabic
Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.Arabic
Using input As New OcrInput()
input.LoadImageFrame("img/arabic.gif", 1)
' add image filters if needed
' In this case, even thought input is very low quality
' IronTesseract can read what conventional Tesseract cannot.
Dim result As OcrResult = ocr.Read(input)
' Console can't print Arabic on Windows easily.
' Let's save to disk instead.
result.SaveAsTextFile("arabic.txt")
End UsingInput.Deskew() を使用することで、低品質なスキャンでも精度は99.8%まで向上し、ほぼ高品質の結果に匹敵します。 これは、Tesseract の複雑さがなく、C# OCR に IronOCR が最適な選択肢である理由を示しています。
画像フィルターにより処理時間がわずかに長くなる可能性がありますが、全体的な OCR の所要時間が大幅に短縮されます。 適切なバランスを見つけるには、ドキュメントの品質が重要になります。
ほとんどのシナリオにおいて、Input.Deskew() と Input.DeNoise() はOCRパフォーマンスの信頼できる向上を提供します。 画像前処理技術について詳しく学びます。
OCR のパフォーマンスと速度を最適化するにはどうすればよいでしょうか?
C# で画像をテキストに変換するときに OCR 速度に影響を与える最も重要な要素は、入力品質です。 ノイズが最小限で DPI がより高い (約 200 dpi) 場合、最も高速かつ正確な結果が得られます。
IronOCR は不完全な文書の修正に優れていますが、この機能強化には追加の処理時間が必要になります。
圧縮アーティファクトが最小限の画像形式を選択します。 TIFF と PNG は通常、デジタル ノイズが少ないため、JPEG よりも結果が速くなります。
どの画像フィルターが OCR 速度を向上させるのでしょうか?
次のフィルターを使用すると、C# OCR 画像からテキストへのワークフローのパフォーマンスを大幅に向上できます。
OcrInput.Rotate(double degrees): イメージを時計回りに回転(反時計回りには負の数)しますOcrInput.Binarize(): 白黒に変換し、低コントラストシナリオでの性能を向上OcrInput.ToGrayScale(): グレースケールに変換し、速度向上の可能性を探るOcrInput.Contrast(): コントラストを自動調整し、精度を向上させますOcrInput.DeNoise(): ノイズが予想される場合、デジタルアーティファクトを除去しますOcrInput.Invert(): 白地に黒文字のテキストを色反転しますOcrInput.Dilate(): テキストの境界を拡大しますOcrInput.Erode(): テキストの境界を縮小しますOcrInput.Deskew(): 整列を修正 - 傾いたドキュメントに不可欠OcrInput.DeepCleanBackgroundNoise(): 積極的なノイズ除去OcrInput.EnhanceResolution: 解像度の低い画像の品質を向上させますOcrInput.DetectPageOrientation(): ページの回転を検出し、修正します。OrientationDetectionModeを渡して精度/速度のトレードオフを制御します:ExtremeDetailed(v2025.8.6追加)
Scale() と EnhanceResolution() は SaveAsSearchablePdf() と互換性がなく、v2025.12.3での既知の問題によるものです。その他のフィルターは検索可能なPDF出力と共に正しく動作します。
IronOCR を最高速度で設定するにはどうすればいいですか?
高品質のスキャンを処理する際の速度を最適化するには、次の設定を使用します。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-7.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Language = OcrLanguage.ChineseSimplified;
// We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Optionally add custom tesseract .traineddata files by specifying a file path
using OcrInput input = new OcrInput();
input.LoadImage("img/MultiLanguage.jpeg");
OcrResult result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");Imports IronOcr
Private ocr As New IronTesseract()
ocr.Language = OcrLanguage.ChineseSimplified
' We can add any number of languages.
ocr.AddSecondaryLanguage(OcrLanguage.English)
' Optionally add custom tesseract .traineddata files by specifying a file path
Using input As New OcrInput()
input.LoadImage("img/MultiLanguage.jpeg")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsTextFile("MultiLanguage.txt")
End Usingこの最適化された設定により、デフォルト設定と比較して35% の速度向上を実現しながら、 99.8% の精度が維持されます。
C# OCRを使用して画像の特定の領域を読み取る方法は?
以下のC#例は、System.Drawing.Rectangleを使用して特定の領域をターゲットにする方法を示します。 この手法は、テキストが予測可能な場所に表示される標準化されたフォームを処理する場合に非常に役立ちます。
IronOCR は切り取られた領域を処理してより速く結果を得ることができますか?
ピクセルベースの座標を使用すると、OCR を特定の領域に制限できるため、速度が大幅に向上し、不要なテキストの抽出を防ぐことができます。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-8.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", pageindices);
OcrResult result = ocr.Read(input);
Console.WriteLine($"{result.Pages.Length} Pages"); // 3 PagesImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("image3.gif", pageindices)
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine($"{result.Pages.Length} Pages") ' 3 Pagesこのターゲットを絞ったアプローチにより、関連するテキストのみを抽出しながら、速度が 41% 向上します。 請求書、小切手、フォームなどの構造化された文書に最適です。 同じ切り取り手法は、PDF OCR 操作でもシームレスに機能します。
 IronOCRの長方形選択を使用した正確な領域ベースのテキスト抽出を示すドキュメント
IronOCRの長方形選択を使用した正確な領域ベースのテキスト抽出を示すドキュメント
IronOCR はいくつの言語をサポートしていますか?
IronOCRは、便利な言語パックを通じて127の国際言語に対応しています。 当社の Web サイトまたはNuGet パッケージ マネージャーから DLL としてダウンロードします。
NuGet インターフェイス ( "IronOcr.Languages"を検索) を通じて言語パックをインストールするか、完全な言語パックのリストにアクセスしてください。
サポートされている言語には、アラビア語、中国語(簡体字/繁体字)、日本語、韓国語、ヒンディー語、ロシア語、ドイツ語、フランス語、スペイン語など 115 以上の言語があり、それぞれ正確なテキスト認識が最適化されています。
複数の言語で OCR を実装するにはどうすればよいでしょうか?
この IronOCR C# チュートリアルの例では、アラビア語のテキスト認識を示します。
Install-Package IronOcr.Languages.Arabic

IronOCRはGIF画像からアラビア語のテキストを正確に抽出します
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-10.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.LoadPdf("example.pdf", Password: "password");
// We can also select specific PDF page numbers to OCR
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Length} Pages");
// 1 page for every page of the PDFImports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.LoadPdf("example.pdf", Password:= "password")
' We can also select specific PDF page numbers to OCR
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
Console.WriteLine($"{result.Pages.Length} Pages")
' 1 page for every page of the PDFIronOCR は複数言語の文書を処理できますか?
ドキュメントに混合言語が含まれている場合は、IronOCR を多言語サポート用に設定します。
Install-Package IronOcr.Languages.ChineseSimplified
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-12.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Metadata Name";
input.LoadPdf("example.pdf", Password: "password");
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Metadata Name"
input.LoadPdf("example.pdf", Password:= "password")
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")マルチページドキュメントをC# OCRで処理する方法は?
IronOCRは複数のページまたは画像を単一のOcrResultにシームレスに組み合わせます。 この機能により、検索可能な PDF の作成やドキュメント セット全体からのテキストの抽出などの強力な機能が可能になります。
1 回の OCR 操作で、画像、TIFF フレーム、PDF ページなど、さまざまなソースを組み合わせて使用できます。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-13.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Pdf Title";
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Pdf Title"
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")TIFF ファイルのすべてのページを効率的に処理します。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-14.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
using OcrInput input = new OcrInput();
input.Title = "Html Title";
// Add more content as required...
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf",Password: "password");
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageindices);
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");Imports IronOcr
Private ocr As New IronTesseract()
Private OcrInput As using
input.Title = "Html Title"
' Add more content as required...
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf",Password:= "password")
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")TIFF または PDF を検索可能な形式に変換します。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-15.csusing IronOcr;
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
input.LoadImage("img/Barcode.png");
OcrResult result = ocr.Read(input);
foreach (var barcode in result.Barcodes)
{
Console.WriteLine(barcode.Value);
// type and location properties also exposed
}Imports IronOcr
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
input.LoadImage("img/Barcode.png")
Dim result As OcrResult = ocr.Read(input)
For Each barcode In result.Barcodes
Console.WriteLine(barcode.Value)
' type and location properties also exposed
Next barcode
End Using既存の PDF を検索可能なバージョンに変換します。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-16.csusing IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs
IronTesseract ocr = new IronTesseract();
ocr.Configuration.ReadBarCodes = true;
using OcrInput input = new OcrInput();
var pageindices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageindices);
OcrResult result = ocr.Read(input);
foreach (var page in result.Pages)
{
// Page object
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// null if we don't set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap(input);
System.Drawing.Bitmap pageImageLegacy = page.ToBitmap(input);
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int paragraphNumber = paragraph.ParagraphNumber;
String paragraphText = paragraph.Text;
System.Drawing.Bitmap paragraphImage = paragraph.ToBitmap(input);
int paragraphXLocation = paragraph.X;
int paragraphYLocation = paragraph.Y;
int paragraphWidth = paragraph.Width;
int paragraphHeight = paragraph.Height;
double paragraphOcrAccuracy = paragraph.Confidence;
var paragraphTextDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int lineNumber = line.LineNumber;
String lineText = line.Text;
AnyBitmap lineImage = line.ToBitmap(input);
System.Drawing.Bitmap lineImageLegacy = line.ToBitmap(input);
int lineXLocation = line.X;
int lineYLocation = line.Y;
int lineWidth = line.Width;
int lineHeight = line.Height;
double lineOcrAccuracy = line.Confidence;
double lineSkew = line.BaselineAngle;
double lineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int wordNumber = word.WordNumber;
String wordText = word.Text;
AnyBitmap wordImage = word.ToBitmap(input);
System.Drawing.Image wordImageLegacy = word.ToBitmap(input);
int wordXLocation = word.X;
int wordYLocation = word.Y;
int wordWidth = word.Width;
int wordHeight = word.Height;
double wordOcrAccuracy = word.Confidence;
if (word.Font != null)
{
// Word.Font is only set when using Tesseract Engine Modes rather than LTSM
String fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isFixedWidth = word.Font.IsFixedWidth;
bool isItalic = word.Font.IsItalic;
bool isSerif = word.Font.IsSerif;
bool isUnderlined = word.Font.IsUnderlined;
bool fontIsCaligraphic = word.Font.IsCaligraphic;
}
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int characterNumber = character.CharacterNumber;
String characterText = character.Text;
AnyBitmap characterImage = character.ToBitmap(input);
System.Drawing.Bitmap characterImageLegacy = character.ToBitmap(input);
int characterXLocation = character.X;
int characterYLocation = character.Y;
int characterWidth = character.Width;
int characterHeight = character.Height;
double characterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spell checking
OcrResult.Choice[] characterChoices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs
Private ocr As New IronTesseract()
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
Dim pageindices = New Integer() { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageindices)
Dim result As OcrResult = ocr.Read(input)
For Each page In result.Pages
' Page object
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' null if we don't set Ocr.Configuration.ReadBarCodes = true;
Dim barcodes() As OcrResult.Barcode = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap(input)
Dim pageImageLegacy As System.Drawing.Bitmap = page.ToBitmap(input)
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphImage As System.Drawing.Bitmap = paragraph.ToBitmap(input)
Dim paragraphXLocation As Integer = paragraph.X
Dim paragraphYLocation As Integer = paragraph.Y
Dim paragraphWidth As Integer = paragraph.Width
Dim paragraphHeight As Integer = paragraph.Height
Dim paragraphOcrAccuracy As Double = paragraph.Confidence
Dim paragraphTextDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim lineNumber As Integer = line.LineNumber
Dim lineText As String = line.Text
Dim lineImage As AnyBitmap = line.ToBitmap(input)
Dim lineImageLegacy As System.Drawing.Bitmap = line.ToBitmap(input)
Dim lineXLocation As Integer = line.X
Dim lineYLocation As Integer = line.Y
Dim lineWidth As Integer = line.Width
Dim lineHeight As Integer = line.Height
Dim lineOcrAccuracy As Double = line.Confidence
Dim lineSkew As Double = line.BaselineAngle
Dim lineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim wordNumber As Integer = word.WordNumber
Dim wordText As String = word.Text
Dim wordImage As AnyBitmap = word.ToBitmap(input)
Dim wordImageLegacy As System.Drawing.Image = word.ToBitmap(input)
Dim wordXLocation As Integer = word.X
Dim wordYLocation As Integer = word.Y
Dim wordWidth As Integer = word.Width
Dim wordHeight As Integer = word.Height
Dim wordOcrAccuracy As Double = word.Confidence
If word.Font IsNot Nothing Then
' Word.Font is only set when using Tesseract Engine Modes rather than LTSM
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isFixedWidth As Boolean = word.Font.IsFixedWidth
Dim isItalic As Boolean = word.Font.IsItalic
Dim isSerif As Boolean = word.Font.IsSerif
Dim isUnderlined As Boolean = word.Font.IsUnderlined
Dim fontIsCaligraphic As Boolean = word.Font.IsCaligraphic
End If
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim characterNumber As Integer = character.CharacterNumber
Dim characterText As String = character.Text
Dim characterImage As AnyBitmap = character.ToBitmap(input)
Dim characterImageLegacy As System.Drawing.Bitmap = character.ToBitmap(input)
Dim characterXLocation As Integer = character.X
Dim characterYLocation As Integer = character.Y
Dim characterWidth As Integer = character.Width
Dim characterHeight As Integer = character.Height
Dim characterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spell checking
Dim characterChoices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next page
End Using同じ手法を TIFF 変換に適用します。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-17.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Configure document properties
input.Title = "Scanned Archive Document";
// Select pages to process
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Create searchable PDF from TIFF
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Configure document properties
input.Title = "Scanned Archive Document"
' Select pages to process
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Create searchable PDF from TIFF
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")
End UsingOCR の結果を HOCR HTML としてエクスポートするにはどうすればいいですか?
IronOCR は HOCR HTML エクスポートをサポートしており、レイアウト情報を保持しながら構造化されたPDF から HTMLおよびTIFF から HTML への変換を可能にします。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-18.csusing IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set HTML title
input.Title = "Document Archive";
// Process multiple document types
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf", "password");
// Add TIFF pages
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Export as HOCR with position data
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");
}
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Set HTML title
input.Title = "Document Archive"
' Process multiple document types
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf", "password")
' Add TIFF pages
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Export as HOCR with position data
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")
End UsingIronOCR はテキストと一緒にバーコードも読み取ることができますか?
IronOCR はテキスト認識とバーコード読み取り機能を独自に組み合わせており、個別のライブラリを必要としません。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-19.cs// Enable combined text and barcode recognition
using IronOcr;
var ocr = new IronTesseract();
// Enable barcode detection
ocr.Configuration.ReadBarCodes = true;
using (var input = new OcrInput())
{
// Load image containing both text and barcodes
input.LoadImage("img/Barcode.png");
// Process both text and barcodes
var result = ocr.Read(input);
// Extract barcode data
foreach (var barcode in result.Barcodes)
{
Console.WriteLine($"Barcode Value: {barcode.Value}");
Console.WriteLine($"Format: {barcode.Format}");
}
}
Imports IronOcr
Dim ocr As New IronTesseract()
' Enable barcode detection
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
' Load image containing both text and barcodes
input.LoadImage("img/Barcode.png")
' Process both text and barcodes
Dim result = ocr.Read(input)
' Extract barcode data
For Each barcode In result.Barcodes
Console.WriteLine($"Barcode Value: {barcode.Value}")
Console.WriteLine($"Format: {barcode.Format}")
Next
End Using詳細な OCR 結果とメタデータにアクセスするにはどうすればよいでしょうか?
IronOCR 結果オブジェクトは、上級開発者が高度なアプリケーションに活用できる包括的なデータを提供します。
各OcrResultには、階層的なコレクション(ページ、段落、行、単語、文字)が含まれています。 すべての要素には、場所、フォント情報、信頼スコアなどの詳細なメタデータが含まれます。
個々の要素 (段落、単語、バーコード) は、画像またはビットマップとしてエクスポートして、さらに処理することができます。
:path=/static-assets/ocr/content-code-examples/tutorials/how-to-read-text-from-an-image-in-csharp-net-20.csusing System;
using IronOcr;
using IronSoftware.Drawing;
// Configure with barcode support
IronTesseract ocr = new IronTesseract
{
Configuration = { ReadBarCodes = true }
};
using OcrInput input = new OcrInput();
// Process multi-page document
int[] pageIndices = { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
OcrResult result = ocr.Read(input);
// Navigate the complete results hierarchy
foreach (var page in result.Pages)
{
// Page-level data
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// Extract page elements
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap();
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Paragraph properties
int paragraphNumber = paragraph.ParagraphNumber;
string paragraphText = paragraph.Text;
double paragraphConfidence = paragraph.Confidence;
var textDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Line details including baseline information
string lineText = line.Text;
double lineConfidence = line.Confidence;
double baselineAngle = line.BaselineAngle;
double baselineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Word-level data
string wordText = word.Text;
double wordConfidence = word.Confidence;
// Font information (when available)
if (word.Font != null)
{
string fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isItalic = word.Font.IsItalic;
}
foreach (var character in word.Characters)
{
// Character-level analysis
string charText = character.Text;
double charConfidence = character.Confidence;
// Alternative character choices for spell-checking
OcrResult.Choice[] alternatives = character.Choices;
}
}
}
}
}
Imports System
Imports IronOcr
Imports IronSoftware.Drawing
' Configure with barcode support
Dim ocr As New IronTesseract With {
.Configuration = New TesseractConfiguration With {
.ReadBarCodes = True
}
}
Using input As New OcrInput()
' Process multi-page document
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("img\Potter.tiff", pageIndices)
Dim result As OcrResult = ocr.Read(input)
' Navigate the complete results hierarchy
For Each page In result.Pages
' Page-level data
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' Extract page elements
Dim barcodes As OcrResult.Barcode() = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap()
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Paragraph properties
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphConfidence As Double = paragraph.Confidence
Dim textDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Line details including baseline information
Dim lineText As String = line.Text
Dim lineConfidence As Double = line.Confidence
Dim baselineAngle As Double = line.BaselineAngle
Dim baselineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Word-level data
Dim wordText As String = word.Text
Dim wordConfidence As Double = word.Confidence
' Font information (when available)
If word.Font IsNot Nothing Then
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isItalic As Boolean = word.Font.IsItalic
End If
For Each character In word.Characters
' Character-level analysis
Dim charText As String = character.Text
Dim charConfidence As Double = character.Confidence
' Alternative character choices for spell-checking
Dim alternatives As OcrResult.Choice() = character.Choices
Next
Next
Next
Next
Next
End Usingまとめ
IronOCR は、Windows、Linux、Mac プラットフォームでシームレスに実行される最も高度なTesseract API 実装を C# 開発者に提供します。 IronOCR を使用して、不完全なドキュメントからでも画像からテキストを正確に読み取ることができる機能は、基本的な OCR ソリューションとは一線を画しています。
ライブラリの独自の機能には、統合バーコード読み取り機能や、結果を検索可能な PDF または HOCR HTML としてエクスポートする機能などがあり、これらの機能は標準の Tesseract 実装では利用できません。
前進
IronOCR の習得を続けるには:
-包括的なスタートガイドをご覧ください -実用的なC#コード例を参照する -詳細なAPIドキュメントを参照してください
ソースコードのダウンロード
アプリケーションに C# OCR 画像からテキストへの変換を実装する準備はできていますか? 今すぐIronOCR をダウンロードして無料トライアルを開始してください。
よくある質問
Tesseract を使用せずに C# で画像をテキストに変換するにはどうすればよいですか?
IronOCR を使用して C# で画像をテキストに変換できます。IronOCR は、画像からテキストへの変換を直接処理する組み込みメソッドでこのプロセスを簡素化します。
低品質画像での OCR 精度を向上させるにはどうすればよいですか?
IronOCR には、Input.Deskew() および Input.DeNoise() などの画像フィルターが用意されており、傾きを補正し、ノイズを軽減することで低品質の画像を強化し、OCR の精度を大幅に向上させることができます。
C# で OCR を使用して複数ページのドキュメントからテキストを抽出する手順は何ですか?
複数ページのドキュメントからテキストを抽出するには、IronOCR を使用すると、LoadPdf() などのメソッドを使用して各ページをロードおよび処理し、各ページを効果的にテキストに変換できます。
画像からバーコードとテキストを同時に読み取ることは可能ですか?
はい、IronOCR は 1 つの画像からテキストとバーコードの両方を読み取ることができます。ocr.Configuration.ReadBarCodes = true を有効にすることで、テキストとバーコード データの両方を抽出できます。
複数の言語でドキュメントを処理するための OCR をセットアップするにはどうすればよいですか?
IronOCR は 125 を超える言語をサポートしており、ocr.Language コマンドを使用して主要な言語を設定し、ocr.AddSecondaryLanguage() コマンドを使用して追加言語を追加することで、多言語ドキュメントの処理を可能にします。
OCR 結果をさまざまな形式でエクスポートするために利用可能なメソッドは何ですか?
IronOCR は複数のメソッドを提供して OCR 結果をエクスポートできます。たとえば、PDF の場合は SaveAsSearchablePdf()、プレーンテキストの場合は SaveAsTextFile()、HOCR HTML 形式の場合は SaveAsHocrFile() があります。
大型画像ファイルの OCR 処理速度を最適化するにはどうすればよいですか?
OCR処理速度を最適化するには、IronOCR の OcrLanguage.EnglishFast を使用して高速な言語認識を実現し、System.Drawing.Rectangle を使用して 特定の領域を定義し、処理時間を短縮します。
保護されたPDFファイルのOCR処理をどのように扱うべきですか?
保護された PDF を処理する際は、正しいパスワードと共に LoadPdf() メソッドを使用します。IronOCR は、ページを画像に自動的に変換して、画像ベースの PDF を処理します。
OCR 結果が正確でない場合はどうすればよいですか?
OCR 結果が正確でない場合は、IronOCR の Input.Deskew() や Input.DeNoise() などの画像強化機能を使用し、正しい言語パックがインストールされていることを確認してください。
OCR プロセスをカスタマイズして特定の文字を除外することはできますか?
はい、IronOCR を利用して、BlackListCharacters プロパティを使用して特定の文字を除外することにより、精度とプロセス速度を改善し、関連するテキストにのみ焦点を当てるように OCR プロセスをカスタマイズできます。



まだスクロールしていますか?
すぐに証拠が欲しいですか? PM > Install-Package IronOcr
サンプルを実行 あなたの画像が検索可能なテキストになるのをご覧ください。










