



In einer Live-Umgebung testen
Testen Sie ohne Wasserzeichen in der Produktion.
Funktioniert dort, wo Sie es brauchen.

using IronOcr;
string imageText = new IronTesseract().Read(@"images\image.png").Text;Imports IronOcr
Private imageText As String = (New IronTesseract()).Read("images\image.png").TextInstall-Package IronOcr
IronOCR ist einzigartig in der Fähigkeit, Text aus unvollständig gescannten Bildern und PDF-Dokumenten automatisch zu erkennen und zu lesen. Die IronTesseract Klasse bietet die einfachste API.
Probieren Sie andere Codebeispiele aus, um detaillierte Kontrolle über Ihre C# OCR-Operationen zu erlangen.
IronOCR bietet den fortschrittlichsten Aufbau von Tesseract überall auf jeder Plattform mit erhöhter Geschwindigkeit, Genauigkeit und einer nativen DLL und API.
Unterstützt Tesseract 3, Tesseract 4 und Tesseract 5 für .NET Framework, Standard, Core, Xamarin und Mono.
IronTesseract, um intuitive APIs zu nutzenRead zur Durchführung von OCR in VB.NETText-Eigenschaft erhaltenusing IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR unterstützt 125 internationale Sprachen. Neben Englisch, das standardmäßig installiert ist, können zusätzliche Sprachpakete über NuGet zu Ihrem .NET-Projekt hinzugefügt oder von unserer Sprachenseite heruntergeladen werden. Die meisten Sprachen sind in Unterstützung von IronOCR-Sprachen
Fast, Standard (empfohlen) und Best Qualität verfügbar. Die Best Qualitätsoption kann genauere Ergebnisse bieten, ist jedoch in der Bearbeitungszeit langsamer.
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR gibt für jede von ihm gescannte Seite ein fortschrittliches Ergebnisobjekt unter Verwendung von Tesseract 5 zurück. Dies enthält Standortdaten, Bilder, Text, statistisches Vertrauen, alternative Symbolauswahlen, Schriftartennamen, Schriftgrößen, Dekoration, Schriftstärken und Position für jedes:
PageParagraphWordBarcode
Egal, ob es sich um Produkt-, Integrations- oder Lizenzanfragen handelt, das Iron-Produktentwicklungsteam steht zur Verfügung, um all Ihre Fragen zu unterstützen. Nehmen Sie Kontakt auf und beginnen Sie einen Dialog mit Iron, um unsere Bibliothek in Ihrem Projekt optimal zu nutzen.
Frage stellen
Die IronOCR (Optische Zeichenerkennung) Bibliothek ermöglicht Entwicklern schnelle und effiziente Ergebnisse beim Konvertieren von Bildern in Text. IronOCR funktioniert mit .NET, VB.NET und C#. Unsere besten .NET-Anwendungen for .NET-Frameworks, die speziell für Sie — den Entwickler — entwickelt wurden, um Sie bei der Erzielung optimaler Leistung für Ihre Projekte zu unterstützen.
OCR empfängt und erkennt Textdateien, Barcodes, QR-Inhalte und mehr. IronOCR bietet jedoch auch zahlreiche Methoden, die es Ihnen ermöglichen, OCR-Lesen und Text aus Bildern in das Web, Windows-Desktop oder Konsolen-.NET-Projekte einzufügen, mit Unterstützung für praktisch unbegrenzte Bildformate und Dateien wie JPG, PNG, GIF, TIFF, BMP, JPEG oder PDF.
Obwohl die Erkennungsergebnisse von Klartext, Zeichen, Zeilen und Absätzen aus Bildausgaben möglicherweise nicht einfach erscheinen, werden Sie feststellen, dass die Ergebnisse von IronOCR unter der Haube tatsächlich einfacher sind als ursprünglich gedacht. IronOCR scannt das Bild auf Ausrichtung, verwendet seine Störgeräuschentfernung und Filter, um Qualität und Auflösung zu prüfen. Es betrachtet seine Eigenschaften, optimiert den OCR-Motor und verwendet ein trainiertes künstliches Intelligenz-Netzwerk, um Text (von Bildern) ebenso wie einen Menschen zu erkennen.
OCR ist selbst für einen Computer kein einfacher Prozess. IronOCR vereinfacht jedoch den Gesamtprozess der Erstellung durchsuchbarer Dokumente mit 100 % Genauigkeit und minimalem Code.
Lesen Sie das Tutorial
Software ist nicht auf geographische Grenzen beschränkt — Unternehmen agieren über Grenzen hinweg und verlassen sich auf mehrere Sprachen, um ihre Ergebnisse zu erzielen. In ähnlicher Weise ist ein Werkzeug zur optischen Zeichenerkennung (OCR), das nur die Dokumentenerkennung in einer einzigen Sprache durchführt, in jeder Hinsicht ein großes NEIN!
Mit einer mehrsprachigen OCR-Bibliothek, die mehrere OCR-Funktionalitäten bietet, profitieren Sie davon, ein durchsuchbares PDF-Dokument aus einem gescannten PDF oder gescannten Bild in mehreren Sprachen (von Französisch bis Chinesisch!) zu erstellen. Ihre Zeit und Mühe werden mit einem dynamischen, durchsuchbaren PDF-Dokument optimiert, das Sie, Ihre Kunden oder Ihre Organisation ohne Einschränkungen verwenden und wiederverwenden können.
Mit einem starken Fokus auf Sie, Ihr Unternehmen und Ihre OCR-Bedürfnisse, ob eingebaut oder auf Anfrage, bietet die IronOCR-Bibliothek eine breite Palette unterstützter Sprachen. Ihr nächstes .NET-Projekt kann ohne Sprachkompatibilitätsprobleme sein!
Ob Arabisch, Spanisch, Französisch, Deutsch, Hebräisch, Italienisch, Japanisch, Vereinfachtes Chinesisch, Traditionelles Chinesisch (Mandarin), Dänisch, Englisch, Finnisch, Portugiesisch, Russisch, Spanisch oder Schwedisch, Sie benennen einfach die Sprachen, und wir stellen sie Ihnen bereit! Sie können Ihre bevorzugten Sprachpakete herunterladen oder unsere 24/7-Support kontaktieren, um weitere Sprachen zu erhalten.
Der erste Schritt ist die Verwendung unseres NuGet-Paketinstallationsprogramms für Windows Visual Studio.
Sprachpakete herunterladen
Wie unterscheidet sich IronOCR von seinen Mitbewerbern? Neben der Möglichkeit, OCR-Funktionalitäten einfach hinzuzufügen, Text zu extrahieren und gedrehte Bilder zu scannen, kann es auch OCR von unvollkommenen Scans durchführen! Im Gegensatz dazu sind viele der heute auf dem Markt erhältlichen Produkte oft starr und ungenau, zum Scheitern verurteilt in realen Einzel- und Unternehmensanwendungen, da die meisten nur mit maschinengedrucktem, hochauflösendem und perfekt angepasstem Text arbeiten.
IronOCR erweitert die Fähigkeiten von Google Tesseract mit seiner leistungsstarken IronTesseract DLL — einer nativen C#-OCR-Bibliothek mit höherer Stabilität und Genauigkeit als die freie Tesseract-Bibliothek.
Mit dem besten Werkzeug in Ihren Händen, selbst wenn Sie ein weniger als perfektes gescanntes Bild oder ein gespeichertes Bild im Speicherordner haben — die Bildverarbeitungsbibliothek von IronOCR reinigt Störgeräusche, dreht, reduziert Verzerrungen und schiefe Ausrichtung und verbessert Auflösung und Kontrast. Die erweiterten Einstellungen zur optischen Zeichenerkennung (OCR) geben Ihnen — den Programmierern — die Werkzeuge und den Code, um die bestmöglichen durchsuchbaren Ergebnisse zu erzeugen, immer wieder.
Suchen Sie nach den Wörtern, die Sie benötigen, und seien Sie nie enttäuscht von den 99,8-100% genauen Ergebnissen und der uneingeschränkten Unterstützung für PDF-Dokumente, mehrseitige TIFF-Dateien, JPEG & JPEG2000, GIF, PNG, BMP, WBMP, System.Drawing.Image, System.Drawing.Bitmap, System.IO.Streams von Bildern, binäre Bilddaten (byte[]) und alles darüber hinaus!
Eine Alternative zu Tesseract
Anders als bei anderen .NET-Anwendungen im .NET-Framework werden Sie feststellen, dass die fortschrittliche optische Zeichenerkennung innerhalb der IronOCR-Paketmanager-Konsole und erkannten Textkonsole Ihren Benutzern die Möglichkeit gibt, mehrere Schriftarten (von Times New Roman bis hin zu verschnörkelten oder vermeintlich schwer verständlichen) zu lesen, Gewichte und Stile für genaues Textlesen von einem ganzen Bild oder gescannten Bildern. Unsere Fähigkeit, bestimmte Bereiche eines Bildes auszuwählen, hilft, Geschwindigkeit und Genauigkeit zu verbessern. Multithreading von wenigen Zeilen bis zu wenigen Absätzen beschleunigt den OCR-Motor und ermöglicht das Lesen mehrerer Dokumente auf Mehrkern-Maschinen.
Unsere Ansprüche auf Geschwindigkeit und Genauigkeit sind nicht auf den Prozess der Zeichenerkennung beschränkt. Vielmehr beginnen die Verbesserungen schon bei der Installation, da der .NET OCR-Motor von IronOCR eine einfach zu installierende, vollständige und gut dokumentierte .NET-Softwarebibliothek ist. Es gibt eine einzige NuGet-Paketmanager-Installation für Visual Studio und Multithreading-Kompatibilität mit MVC, WebApp, Desktop-, Konsolen- und Serveranwendungen.
Sie können 99,8-100% OCR-Genauigkeit erreichen, ohne auf externe Webdienste, laufende Gebühren oder das Versenden vertraulicher Dokumente über das Internet angewiesen zu sein. Ohne das umständliche C++-Codieren ist IronOCR die klare Wahl, wenn Sie vollständige PDF-OCR-Unterstützung für mehrere Zeichen, Wörter, Zeilen, Absätze, Texte und Dokumente benötigen.
Wir bieten die besten Optionen für Entwickler, die ihr Codieren perfektionieren möchten, da IronOCR sofort einsatzbereit ist, ohne dass eine Leistungsoptimierung oder starke Modifikationen der Eingabebilder erforderlich sind. Die neueste IronOCR-Version arbeitet erstaunlich schnell — bis zu zehnmal schneller und macht über 250% weniger Fehler als frühere Versionen. Wir verbessern unsere eigenen Builds, um Ihre Ziele zu unterstützen und bieten die perfekte Plattform für OCR!
Vollständige Funktionsliste anzeigen
Sogar bei der Verwendung mobiler Geräte ermöglicht unsere perfekte .NET-OCR-Bibliothek Entwicklern sorgenfreies Codieren, da IronOCR die direkte und komplexe Textexportierung, maschinencodierte Text-, Barcode-Daten- oder strukturierte Objektmodell-Daten unterstützt. Sie können die Inhaltselemente in Absätze, Zeilen, Wörter, Zeichen und Bildstring-Ergebnisse aufteilen, um sie direkt in Ihren .NET-Anwendungen zu verwenden.
Vom Quellcode zum Endergebnis — die resultierenden Daten wären nutzlos, wenn Sie sie nicht in Ihre Anwendung exportieren könnten. IronOCR versteht dies und erlaubt es Ihnen, das OCR-Ergebnis in XHTML zu exportieren, um mit einem nachhaltigen Format über eine breitere Palette von Anwendungen und mit Integration in komplexe Websites zu arbeiten, ganz zu schweigen von schnelleren Ladezeiten!
Die Unterstützung endet jedoch nicht dort. Die Möglichkeit, OCR in durchsuchbare PDF-Dokumente zu exportieren, erleichtert es Ihnen, Ihren Kunden und Organisationen, PDF-Dokumente bei Bedarf zu speichern und abzurufen! Dies ist besonders vorteilhaft, wenn Sie einen 30-seitigen Vertrag in Ihrer Datenbank mit ein paar Schlüsselwörtern durchsuchen können, und es ermöglicht Ihnen auch, Ihr Unternehmen als compliance-freundlich zu präsentieren, da durchsuchbare PDF-Dokumente nachweislich für Sehbehinderte von Vorteil sind.
Zudem können Sie Ihre Ergebnisse ins OCR-Format exportieren, das Ihr OCR-Ausgabemuster, Layoutinformationen und Stilinformationen repräsentiert und die zugehörigen Informationen in standardmäßigem HTML einbettet.
Mehr erfahrenKostenlos Community-Entwicklungslizenzen. Kommerzielle Lizenzen ab $749.





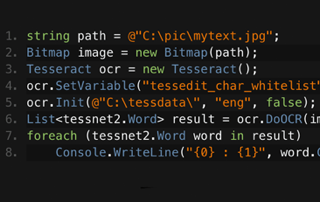
C# Tesseract OCR

Jim war eine führende Figur in der Entwicklung von IronOCR. Jim entwirft und baut Bildverarbeitungsalgorithmen und Leseverfahren für OCR.
21. Vergleich anzeigen
C# OCR ASP.NET

Erfahren Sie, wie Gemmas Team IronOCR verwendet, um Text aus Bildern für ihre Archivierungssoftware zu lesen. Gemma teilt ihre eigenen Codebeispiele.
Bild zu Text .NET Tutorial




Das Iron-Team hat über 10 Jahre Erfahrung im .NET-Softwaremarkt.








Install-Package IronOcr

Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich eingereicht.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich
Testen Sie ohne Wasserzeichen in der Produktion.
Funktioniert dort, wo Sie es brauchen.
Erhalten Sie 30 Tage voll funktionsfähiges Produkt.
In wenigen Minuten einsatzbereit.
Voller Zugriff auf unser Support-Engineering-Team während Ihrer Produktprobe
Eine Live-Demo unseres Produkts und seiner Hauptmerkmale
Erhalten Sie projektspezifische Funktionsempfehlungen
Alle Ihre Fragen werden beantwortet, um sicherzustellen, dass Sie alle Informationen erhalten, die Sie benötigen. (Völlig unverbindlich.)





Buchen Sie eine unverbindliche Beratung

Füllen Sie das Formular unten aus oder senden Sie eine E-Mail an sales@ironsoftware.com
Ihre Daten werden immer vertraulich behandelt.

Windows (10, 11, Server 2012 - 2022)
Keine Verträge, keine Kartenangaben, keine Verpflichtungen.


