

Pobieranie danych ze strony internetowej z filmami przy użyciu języka C# i biblioteki IronWebscraper
IronWebscraper pobiera dane o filmach ze stron internetowych poprzez analizowanie elementów HTML, tworzenie obiektów typowanych do przechowywania danych strukturalnych oraz nawigację między stronami przy użyciu metadanych w celu budowania kompleksowych zbiorów danych o filmach. Ta biblioteka C# do scrapowania stron internetowych ułatwia przekształcanie nieuporządkowanych treści internetowych w uporządkowane, podatne na analizę dane.
Szybki start: Pobieranie filmów w języku C#
- Zainstaluj IronWebscraper za pomocą menedżera pakietów NuGet
- Utwórz klasę, która dziedziczy z
WebScraper - Nadpisz
Init(), aby ustawić licencję i zażądać docelowego URL - Nadpisz
Parse(), aby wyodrębnić dane filmów za pomocą selektorów CSS - Użyj metody
Scrape(), aby zapisać dane w formacie JSON
-
Install IronWebScraper with NuGet Package Manager
PM > Install-Package IronWebScraper -
Skopiuj i uruchom ten fragment kodu.
using IronWebScraper; using System; public class QuickstartMovieScraper : WebScraper { public override void Init() { // Set your license key License.LicenseKey = "YOUR-LICENSE-KEY"; // Configure scraper settings this.LoggingLevel = LogLevel.All; this.WorkingDirectory = @"C:\MovieData\Output\"; // Start scraping from the homepage this.Request("https://example-movie-site.com", Parse); } public override void Parse(Response response) { // Extract movie titles using CSS selectors foreach (var movieDiv in response.Css(".movie-item")) { var title = movieDiv.Css("h2")[0].TextContentClean; var url = movieDiv.Css("a")[0].Attributes["href"]; // Save the scraped data Scrape(new { Title = title, Url = url }, "movies.json"); } } } // Run the scraper var scraper = new QuickstartMovieScraper(); scraper.Start(); -
Wdrożenie do testowania w środowisku produkcyjnym
Rozpocznij używanie IronWebScraper w swoim projekcie już dziś z darmową wersją próbną

Jak skonfigurować klasę Movie Scraper?
Zacznij od przykładu rzeczywistej strony internetowej. Przeszukamy stronę internetową poświęconą filmom, korzystając z technik opisanych w naszym samouczku Webscraping w C#.
Dodaj nową klasę i nazwij ją MovieScraper:

Utworzenie dedykowanej klasy scraper pomaga uporządkować kod i sprawia, że można go ponownie wykorzystać. Takie podejście jest zgodne z zasadami programowania obiektowego i pozwala na łatwe rozszerzenie funkcjonalności w przyszłości.
Jak wygląda struktura docelowej strony internetowej?
Sprawdź strukturę strony pod kątem scrapingu. Zrozumienie struktury strony internetowej ma kluczowe znaczenie dla skutecznego scrapingu. Podobnie jak w naszym przewodniku dotyczącym pobierania danych ze strony internetowej z filmami, najpierw przeanalizuj strukturę HTML:
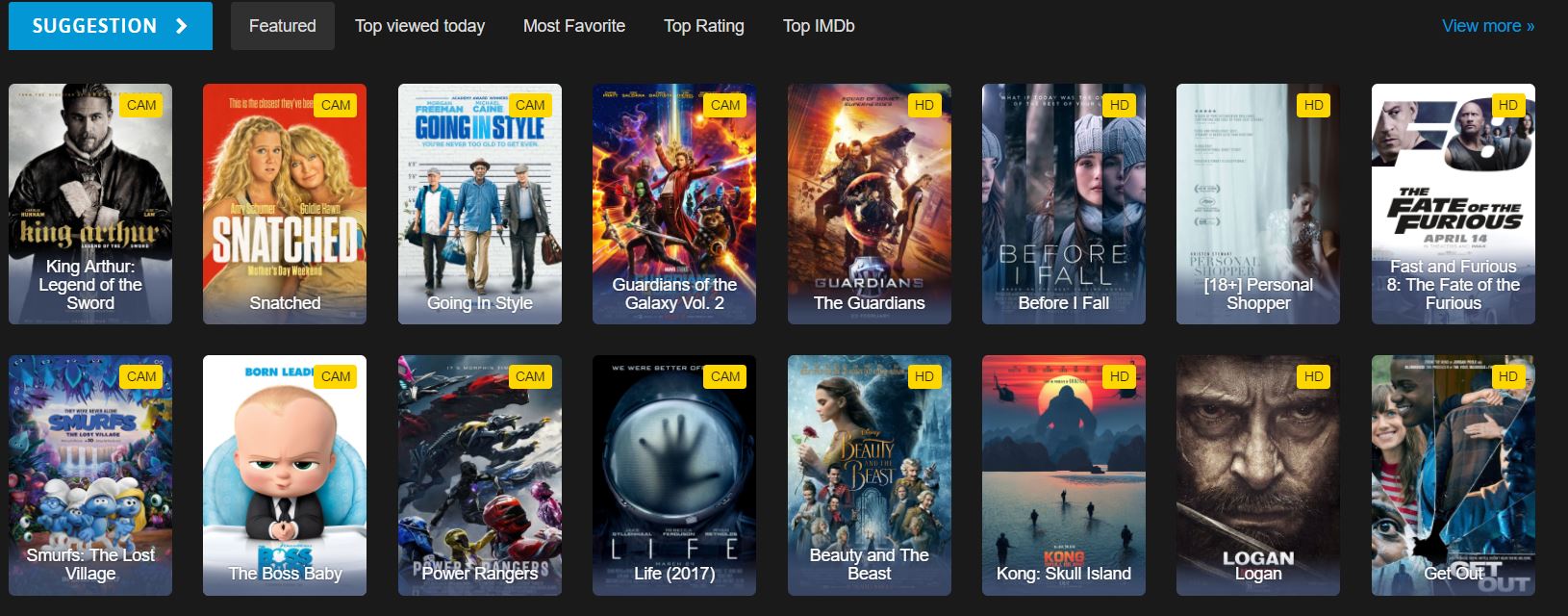
Które elementy HTML zawierają dane filmowe?
Jest to fragment kodu HTML strony głównej, który widzimy na stronie internetowej. Analiza struktury HTML pomaga zidentyfikować właściwe selektory CSS, których należy użyć:
<div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div><div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div>Mamy identyfikator filmu, tytuł i link do strony z szczegółowymi informacjami. Każdy film jest zawarty w elemencie div z klasą ml-item i zawiera unikalny atrybut data-movie-id do identyfikacji.
Jak zaimplementować podstawowe scrapowanie filmów?
Rozpocznij pobieranie tego zestawu danych. Przed uruchomieniem jakiegokolwiek scrapera upewnij się, że prawidłowo skonfigurowałeś klucz licencyjny, jak pokazano poniżej:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("www.website.com", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"))
Dim link = div.Css("a")(0)
Dim movieTitle = link.TextContentClean
' Scrape and store movie data as key-value pairs
Scrape(New ScrapedData() From {
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
},
"Movie.Jsonl")
End If
Next div
End Sub
End ClassDo czego służy właściwość katalogu roboczego?
Co nowego w tym kodzie?
Właściwość Working Directory określa główny katalog roboczy dla wszystkich zebranych danych i powiązanych plików. Dzięki temu wszystkie pliki wyjściowe są uporządkowane w jednym miejscu, co ułatwia zarządzanie projektami scrapingowymi na dużą skalę. Katalog zostanie utworzony automatycznie, jeśli nie istnieje.
Kiedy należy używać selektorów CSS, a kiedy atrybutów?
Dodatkowe uwagi:
Selektory CSS są idealne do wybierania elementów na podstawie ich pozycji strukturalnej lub nazw klas, natomiast bezpośredni dostęp do atrybutów jest lepszy do wyodrębniania konkretnych wartości, takich jak identyfikatory lub niestandardowe atrybuty danych. W naszym przykładzie używamy selektorów CSS (#movie-featured > div) do poruszania się po strukturze DOM i atrybutów (data-movie-id), aby wyodrębniać określone wartości.
Jak utworzyć obiekty typu dla zebranych danych?
Tworzenie obiektów typowanych w celu przechowywania zebranych danych w sformatowanych obiektach. Korzystanie z obiektów silnie typowanych zapewnia lepszą organizację kodu, obsługę IntelliSense oraz sprawdzanie typów w czasie kompilacji.
Zaimplementuj klasę Movie, która będzie przechowywać sformatowane dane:
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
End ClassW jaki sposób użycie obiektów typowanych poprawia organizację danych?
Zaktualizuj kod, aby używać klasę typowaną Movie zamiast ogólnego słownika ScrapedData:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://website.com/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Scrape and store movie object
Scrape(movie, "Movie.Jsonl")
End If
Next div
End Sub
End ClassJakiego formatu używa metoda Scrape dla obiektów typu?
Co nowego?
- Zaimplementowaliśmy klasę
Movie, aby przechowywać wyodrębnione dane, zapewniając bezpieczeństwo typów i lepszą organizację kodu. - Przekazujemy obiekty filmów do metody
Scrape, która rozumie nasz format i zapisuje to w określony sposób, jak poniżej:

Wynik jest automatycznie serializowany do formatu JSON, co ułatwia importowanie do baz danych lub innych aplikacji.
Jak zebrać dane ze szczegółowych stron filmowych?
Rozpocznij zeskrobywanie bardziej szczegółowych stron. Pobieranie danych z wielu stron jest częstym wymaganiem, a IronWebscraper ułatwia to dzięki mechanizmowi łańcuchowania żądań.
Jakie dodatkowe dane mogę wyodrębnić ze stron szczegółowych?
Strona filmu wygląda tak i zawiera bogate metadane o każdym filmie:

<div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div><div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>Jak rozszerzyć klasę Movie o dodatkowe właściwości?
Rozszerz klasę Movie o nowe właściwości (Description, Genre, Actor, Director, Country, Duration, IMDb Score), ale użyj tylko Description, Genre i Actor dla tego przykładu. Użycie List<string> dla gatunków i aktorów pozwala na eleganckie zarządzanie wieloma wartościami:
using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}Imports System.Collections.Generic
Public Class Movie
Public Property Id() As Integer
Public Property Title() As String
Public Property URL() As String
Public Property Description() As String
Public Property Genre() As List(Of String)
Public Property Actor() As List(Of String)
End ClassJak poruszać się między stronami podczas scrapowania?
Nawiguj do szczegółowej strony, aby ją wyodrębnić. IronWebScraper automatycznie dba o bezpieczeństwo wątków, co pozwala na równoczesne przetwarzanie wielu stron.
Dlaczego warto używać wielu funkcji analizy dla różnych typów stron?
IronWebScraper umożliwia dodanie wielu funkcji skrybowania, aby obsłużyć różne formaty stron. To rozdzielenie odpowiedzialności sprawia, że twój kod jest bardziej zarządzalny i pozwala na odpowiednie obsługiwanie różnych struktur stron. Każda funkcja analizy może skupić się na wyodrębnianiu danych z określonego typu strony.
W jaki sposób MetaData pomaga przekazywać obiekty między funkcjami analizy?
Funkcja MetaData jest kluczowa dla utrzymania stanu między żądaniami. Więcej zaawansowanych funkcji skrobania można znaleźć w naszym szczegółowym przewodniku:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://domain/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Request detailed page
Me.Request(movie.URL, AddressOf ParseDetails, New MetaData() From {
{ "movie", movie }
})
End If
Next div
End Sub
Public Sub ParseDetails(ByVal response As Response)
' Retrieve movie object from metadata
Dim movie = response.MetaData.Get(Of Movie)("movie")
Dim div = response.Css("div.mvic-desc")(0)
' Extract description
movie.Description = div.Css("div.desc")(0).TextContentClean
' Extract genres
movie.Genre = New List(Of String)() ' Initialize genre list
For Each genre In div.Css("div > p > a")
movie.Genre.Add(genre.TextContentClean)
Next genre
' Extract actors
movie.Actor = New List(Of String)() ' Initialize actor list
For Each actor In div.Css("div > p:nth-child(2) > a")
movie.Actor.Add(actor.TextContentClean)
Next actor
' Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl")
End Sub
End ClassJakie są kluczowe cechy podejścia do wiele-stronicowego skrobania?
Co nowego?
- Dodaj funkcje skrobania (np.
ParseDetails), aby skrobać szczegółowe strony, podobnie jak techniki używane przy skrobaniu z witryny sklepu. - Przenieś funkcję
Scrape, która generuje pliki, do nowej funkcji, zapewniając, że dane są zapisywane tylko po zebraniu wszystkich szczegółów. - Użyj funkcji IronWebScraper (
MetaData), aby przekazywać obiekty filmów do nowych funkcji skrobania, utrzymując stan obiektu w poprzek żądań. - Skrobać strony i zapisywać dane obiektów filmów do plików z pełnymi informacjami.

Więcej informacji na temat dostępnych metod i właściwości znajdziesz w dokumentacji API. IronWebScraper dostarcza solidny framework do wyodrębniania danych strukturalnych z witryn internetowych, dzięki czemu jest niezbędnym narzędziem do projektów związanych z gromadzeniem i analizą danych.
Często Zadawane Pytania
Jak wydobyć tytuły filmów z HTML za pomocą C#?
IronWebScraper udostępnia metody selekcji CSS, aby wydobyć tytuły filmów z HTML. Użyj metody response.Css() z odpowiednimi selektorami, takimi jak '.movie-item h2', aby zgromadzić elementy tytułów, a następnie uzyskaj wartość czystego tekstu z właściwości TextContentClean.
Jaki jest najlepszy sposób nawigacji pomiędzy wieloma stronami filmów?
IronWebScraper obsługuje nawigację po stronach za pomocą metody Request(). Możesz wydobyć linki paginacji za pomocą selektorów CSS, a następnie wywołać Request() dla każdego URL, aby zbierać dane z wielu stron, automatycznie tworząc zorganizowane zbiory danych filmowych.
Jak mogę zapisać zebrane dane filmowe w zorganizowanym formacie?
Użyj metody Scrape() IronWebScraper, aby zapisać dane w formacie JSON. Utwórz obiekty anonimowe lub klasy z właściwościami filmu, jak tytuł, URL i ocena, a następnie przekaż je do Scrape() razem z nazwą pliku, aby automatycznie serializować i zapisać dane.
Jakie selektory CSS powinienem użyć do wydobycia informacji o filmach?
IronWebScraper obsługuje standardowe selektory CSS. Na stronach filmowych użyj selektorów takich jak '.movie-item' dla kontenerów, 'h2' dla tytułów, 'a[href]' dla linków i specyficznych nazw klas dla ocen lub gatunków filmów. Metoda Css() zwraca kolekcje, które można przeglądać.
Jak mogę obsłużyć wskaźniki jakości filmu jak 'CAM' w zebranych danych?
IronWebScraper pozwala wydobywać i przetwarzać wskaźniki jakości, kierując się na ich specyficzne elementy HTML. Użyj selektorów CSS, aby zlokalizować odznaki jakości lub tekst, a następnie uwzględnij je jako właściwości w obiektach zebranych danych dla kompleksowej informacji o filmie.
Czy mogę skonfigurować logowanie dla moich operacji zbierania danych filmowych?
Tak, IronWebScraper zawiera wbudowaną funkcjonalność logowania. Ustaw właściwość LoggingLevel na LogLevel.All w metodzie Init(), aby śledzić wszystkie działania scrapingowe, błędy i postęp, co pomaga w debugowaniu i monitorowaniu wydobywania danych filmowych.
Jak poprawnie skonfigurować katalogi robocze dla zebranych danych?
IronWebScraper pozwala ustawić właściwość WorkingDirectory w metodzie Init(). Określ ścieżkę jak 'C:\MovieData\Output\', gdzie zostaną zapisane pliki zebranych danych filmowych. To centralizuje zarządzanie wyjściowym oraz utrzymuje porządek w danych.
Jak poprawnie dziedziczyć po klasie WebScraper?
Utwórz nową klasę dziedziczącą po klasie bazowej IronWebScraper WebScraper. Nadpisz metodę Init() do konfiguracji oraz metodę Parse() do logiki wydobywania danych. To podejście obiektowe czyni twój scraper filmowy możliwym do ponownego użycia i łatwo utrzymywalnym.


Wciąż przewijasz?
Czy chcesz szybko dowodu? PM > Install-Package IronWebScraper
uruchom przykład obserwuj, jak twoja docelowa strona przekształca się w dane strukturalne.










