


C# OCR Image to Text Tutorial: Convert Images to Text Without Tesseract
Möchten Sie Bilder in C# ohne den Aufwand komplexer Tesseract-Konfigurationen in Text umwandeln? Dieses umfassende IronOCR C#-Tutorial zeigt Ihnen, wie Sie in Ihren .NET-Anwendungen mit nur wenigen Codezeilen leistungsstarke optische Zeichenerkennung implementieren können.
Schnellstart: Text aus einem Bild in einer Zeile extrahieren
Dieses Beispiel zeigt, wie einfach es ist, IronOCR zu erfassen – nur eine Zeile C# verwandelt Ihr Bild in Text. Es demonstriert die Initialisierung der OCR-Engine und das sofortige Lesen und Abrufen von Text ohne komplexe Einrichtung.
-
Installieren Sie IronOCR mit NuGet Package Manager
PM > Install-Package IronOcr -
Kopieren Sie diesen Codeausschnitt und führen Sie ihn aus.
string text = new IronTesseract().Read("image.png").Text; -
Bereitstellen zum Testen in Ihrer Live-Umgebung
Beginnen Sie noch heute, IronOCR in Ihrem Projekt zu verwenden, mit einer kostenlosen Testversion

Minimaler Arbeitsablauf (5 Schritte)
- Laden Sie IronOCR herunter – die C#-OCR-Bibliothek zur Bild-zu-Text-Konvertierung.
- Verwenden Sie
IronTesseractKlasse, um Text sofort aus Bildern zu lesen. - Bildfilter anwenden, um die OCR-Genauigkeit bei Scans mit geringer Qualität zu verbessern.
- Mehrere Sprachen mit herunterladbaren Sprachpaketen verarbeiten
- Ergebnisse als durchsuchbare PDFs exportieren oder Textzeichenfolgen extrahieren
Wie lese ich Text von Bildern in .NET-Anwendungen?
Um C# OCR Bild-zu-Text-Funktionalität in Ihren .NET-Anwendungen zu erreichen, benötigen Sie eine zuverlässige OCR-Bibliothek. IronOCR bietet eine verwaltete Lösung unter Verwendung der IronOcr.IronTesseract-Klasse, die sowohl Genauigkeit als auch Geschwindigkeit maximiert, ohne dass externe Abhängigkeiten erforderlich sind.
Installieren Sie zuerst IronOCR in Ihrem Visual Studio-Projekt. Sie können die IronOCR DLL direkt herunterladen oder den NuGet Package Manager verwenden.
Install-Package IronOcr
Warum IronOCR für C# OCR ohne Tesseract wählen?
Wenn Sie Bilder in C# in Text umwandeln müssen, bietet IronOCR erhebliche Vorteile gegenüber traditionellen Tesseract-Implementierungen:
- Funktioniert sofort in reinen .NET-Umgebungen
- Keine Tesseract-Installation oder -Konfiguration erforderlich
- Führt die neuesten Engines aus: Tesseract 5 (plus Tesseract 4 & 3)
- Kompatibel mit .NET Framework 4.6.2+, .NET Standard 2+ und .NET Core 2, 3, 5, 6, 7, 8, 9 und 10
- Verbessert Genauigkeit und Geschwindigkeit im Vergleich zu herkömmlichem Tesseract
- Unterstützt Xamarin, Mono, Azure und Docker-Deployments
- Verwalten komplexer Tesseract-Wörterbücher über NuGet-Pakete
- Unterstützt PDFs, Multi-Frame-TIFFs und alle wichtigen Bildformate automatisch
- Korrigiert niedrige Qualität und verzerrte Scans für optimale Ergebnisse
Wie man das IronOCR C# Tutorial für grundlegendes OCR verwendet?
Dieses Iron Tesseract C#-Beispiel zeigt den einfachsten Weg, Text aus einem Bild mit IronOCR zu lesen. Die Klasse IronOcr.IronTesseract extrahiert Text und gibt ihn als Zeichenfolge zurück.
// Basic C# OCR image to text conversion using IronOCR
// This example shows how to extract text from images without complex setup
using IronOcr;
using System;
try
{
// Initialize IronTesseract for OCR operations
var ocrEngine = new IronTesseract();
// Path to your image file - supports PNG, JPG, TIFF, BMP, and more
var imagePath = @"img\Screenshot.png";
// Create input and perform OCR to convert image to text
using (var input = new OcrInput(imagePath))
{
// Read text from image and get results
OcrResult result = ocrEngine.Read(input);
// Display extracted text
Console.WriteLine(result.Text);
}
}
catch (OcrException ex)
{
// Handle OCR-specific errors
Console.WriteLine($"OCR Error: {ex.Message}");
}
catch (Exception ex)
{
// Handle general errors
Console.WriteLine($"Error: {ex.Message}");
}// Basic C# OCR image to text conversion using IronOCR
// This example shows how to extract text from images without complex setup
using IronOcr;
using System;
try
{
// Initialize IronTesseract for OCR operations
var ocrEngine = new IronTesseract();
// Path to your image file - supports PNG, JPG, TIFF, BMP, and more
var imagePath = @"img\Screenshot.png";
// Create input and perform OCR to convert image to text
using (var input = new OcrInput(imagePath))
{
// Read text from image and get results
OcrResult result = ocrEngine.Read(input);
// Display extracted text
Console.WriteLine(result.Text);
}
}
catch (OcrException ex)
{
// Handle OCR-specific errors
Console.WriteLine($"OCR Error: {ex.Message}");
}
catch (Exception ex)
{
// Handle general errors
Console.WriteLine($"Error: {ex.Message}");
}' Basic C# OCR image to text conversion using IronOCR
' This example shows how to extract text from images without complex setup
Imports IronOcr
Imports System
Try
' Initialize IronTesseract for OCR operations
Dim ocrEngine = New IronTesseract()
' Path to your image file - supports PNG, JPG, TIFF, BMP, and more
Dim imagePath = "img\Screenshot.png"
' Create input and perform OCR to convert image to text
Using input = New OcrInput(imagePath)
' Read text from image and get results
Dim result As OcrResult = ocrEngine.Read(input)
' Display extracted text
Console.WriteLine(result.Text)
End Using
Catch ex As OcrException
' Handle OCR-specific errors
Console.WriteLine($"OCR Error: {ex.Message}")
Catch ex As Exception
' Handle general errors
Console.WriteLine($"Error: {ex.Message}")
End TryDieser Code erreicht 100% Genauigkeit bei klaren Bildern und extrahiert Text genau so, wie er erscheint:
IronOCR Simple Example
In this simple example we test the accuracy of our C# OCR library to read text from a PNG Image. This is a very basic test, but things will get more complicated as the tutorial continues.
The quick brown fox jumps over the lazy dogDie Klasse IronTesseract verarbeitet komplexe OCR-Vorgänge intern. Sie scannt automatisch die Ausrichtung, optimiert die Auflösung und verwendet KI, um Text aus Bildern mit menschlicher Genauigkeit zu lesen.
Trotz der ausgeklügelten Verarbeitung im Hintergrund - einschließlich Bildanalyse, Engine-Optimierung und intelligenter Texterkennung - entspricht der OCR-Prozess der menschlichen Lesegeschwindigkeit und erhält außergewöhnliche Genauigkeitsniveaus.
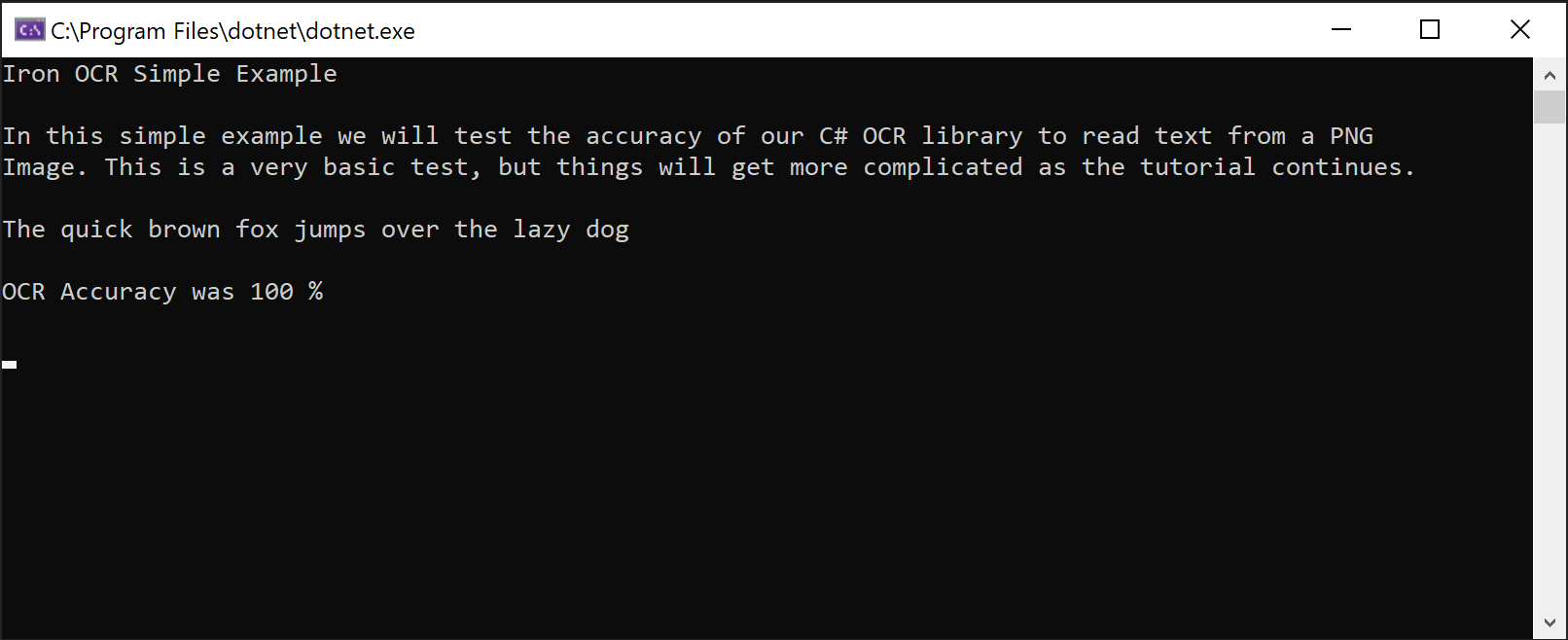 Screenshot, der die Fähigkeit von IronOCR demonstriert, Text aus einem PNG-Bild mit perfekter Genauigkeit zu extrahieren
Screenshot, der die Fähigkeit von IronOCR demonstriert, Text aus einem PNG-Bild mit perfekter Genauigkeit zu extrahieren
Wie man fortgeschrittenes C# OCR ohne Tesseract-Konfiguration implementiert?
Für Produktionsanwendungen, die optimale Leistung erfordern, wenn Sie Bilder in C# in Text umwandeln, verwenden Sie die Klassen OcrInput und IronTesseract gemeinsam. Dieser Ansatz bietet fein abgestimmte Kontrolle über den OCR-Prozess.
OcrInput Klassenfunktionen
- Verarbeitet mehrere Bildformate: JPEG, TIFF, GIF, BMP, PNG
- Importiert vollständige PDFs oder spezifische Seiten
- Verbessert automatisch Kontrast, Auflösung und Bildqualität
- Korrigiert Drehung, Rauschunterdrückung, Verzerrung und negative Bilder
IronTesseract Klassenfunktionen
- Zugriff auf über 127 vorkonfigurierte Sprachen
- Enthält Tesseract 5, 4 und 3 Engines
- Dokumenttyp-Spezifikation (Screenshot, Ausschnitt oder vollständiges Dokument)
- Integrierte Barcode-Lesefähigkeiten
- Mehrere Ausgabeformate: durchsuchbare PDFs, HOCR HTML, DOM-Objekte und Zeichenfolgen
Wie fängt man mit OcrInput und IronTesseract an?
Hier ist eine empfohlene Konfiguration für dieses IronOCR C#-Tutorial, die gut mit den meisten Dokumenttypen funktioniert:
using IronOcr;
// Initialize IronTesseract for advanced OCR operations
IronTesseract ocr = new IronTesseract();
// Create input container for processing multiple images
using (OcrInput input = new OcrInput())
{
// Process specific pages from multi-page TIFF files
int[] pageIndices = new int[] { 1, 2 };
// Load TIFF frames - perfect for scanned documents
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
// Execute OCR to read text from image using IronOCR
OcrResult result = ocr.Read(input);
// Output the extracted text
Console.WriteLine(result.Text);
}using IronOcr;
// Initialize IronTesseract for advanced OCR operations
IronTesseract ocr = new IronTesseract();
// Create input container for processing multiple images
using (OcrInput input = new OcrInput())
{
// Process specific pages from multi-page TIFF files
int[] pageIndices = new int[] { 1, 2 };
// Load TIFF frames - perfect for scanned documents
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
// Execute OCR to read text from image using IronOCR
OcrResult result = ocr.Read(input);
// Output the extracted text
Console.WriteLine(result.Text);
}Imports IronOcr
' Initialize IronTesseract for advanced OCR operations
Private ocr As New IronTesseract()
' Create input container for processing multiple images
Using input As New OcrInput()
' Process specific pages from multi-page TIFF files
Dim pageIndices() As Integer = { 1, 2 }
' Load TIFF frames - perfect for scanned documents
input.LoadImageFrames("img\Potter.tiff", pageIndices)
' Execute OCR to read text from image using IronOCR
Dim result As OcrResult = ocr.Read(input)
' Output the extracted text
Console.WriteLine(result.Text)
End UsingDiese Konfiguration erreicht konstant nahezu perfekte Genauigkeit bei Scans mittlerer Qualität. Die LoadImageFrames-Methode verarbeitet mehrseitige Dokumente effizient und eignet sich daher ideal für Szenarien der Stapelverarbeitung.

Beispiel-TIFF-Dokument, das die Fähigkeiten von IronOCR zur Extraktion mehrseitiger Texte demonstriert.
Die Fähigkeit, Text aus Bildern und Barcodes in gescannten Dokumenten wie TIFFs zu lesen, zeigt, wie IronOCR komplexe OCR-Aufgaben vereinfacht. Die Bibliothek überzeugt bei realen Dokumenten und verarbeitet problemlos mehrseitige TIFFs und PDF-Textextraktion.
Wie verarbeitet IronOCR niedrigqualitative Scans?

Niedrig aufgelöste, verrauschte Dokumente, die IronOCR mithilfe von Bildfiltern präzise verarbeiten kann.
Beim Arbeiten mit unvollkommenen Scans mit Verzerrung und digitalem Rauschen übertrifft IronOCR andere C# OCR-Bibliotheken. Es ist speziell für reale Szenarien konzipiert und nicht für makellose Testbilder.
// Advanced Iron Tesseract C# example for low-quality images
using IronOcr;
using System;
var ocr = new IronTesseract();
try
{
using (var input = new OcrInput())
{
// Load specific pages from poor-quality TIFF
var pageIndices = new int[] { 0, 1 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageIndices);
// Apply deskew filter to correct rotation and perspective
input.Deskew(); // Critical for improving accuracy on skewed scans
// Perform OCR with enhanced preprocessing
OcrResult result = ocr.Read(input);
// Display results
Console.WriteLine("Recognized Text:");
Console.WriteLine(result.Text);
}
}
catch (Exception ex)
{
Console.WriteLine($"Error during OCR: {ex.Message}");
}// Advanced Iron Tesseract C# example for low-quality images
using IronOcr;
using System;
var ocr = new IronTesseract();
try
{
using (var input = new OcrInput())
{
// Load specific pages from poor-quality TIFF
var pageIndices = new int[] { 0, 1 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageIndices);
// Apply deskew filter to correct rotation and perspective
input.Deskew(); // Critical for improving accuracy on skewed scans
// Perform OCR with enhanced preprocessing
OcrResult result = ocr.Read(input);
// Display results
Console.WriteLine("Recognized Text:");
Console.WriteLine(result.Text);
}
}
catch (Exception ex)
{
Console.WriteLine($"Error during OCR: {ex.Message}");
}' Advanced Iron Tesseract C# example for low-quality images
Imports IronOcr
Imports System
Private ocr = New IronTesseract()
Try
Using input = New OcrInput()
' Load specific pages from poor-quality TIFF
Dim pageIndices = New Integer() { 0, 1 }
input.LoadImageFrames("img\Potter.LowQuality.tiff", pageIndices)
' Apply deskew filter to correct rotation and perspective
input.Deskew() ' Critical for improving accuracy on skewed scans
' Perform OCR with enhanced preprocessing
Dim result As OcrResult = ocr.Read(input)
' Display results
Console.WriteLine("Recognized Text:")
Console.WriteLine(result.Text)
End Using
Catch ex As Exception
Console.WriteLine($"Error during OCR: {ex.Message}")
End TryDurch die Verwendung von Input.Deskew() verbessert sich die Genauigkeit bei Scans geringer Qualität auf 99,8 % und entspricht damit fast den Ergebnissen bei hoher Qualität. Dies zeigt, warum IronOCR die bevorzugte Wahl für C# OCR ohne Tesseract-Komplikationen ist.
Bildfilter können die Bearbeitungszeit leicht erhöhen, verkürzen aber erheblich die Gesamt-OCR-Dauer. Das richtige Gleichgewicht hängt von Ihrer Dokumentqualität ab.
In den meisten Fällen bieten Input.Deskew() und Input.DeNoise() zuverlässige Verbesserungen der OCR-Leistung. Erfahren Sie mehr über Bildvorverarbeitungstechniken.
Wie optimiere ich die OCR-Leistung und -Geschwindigkeit?
Der wichtigste Faktor, der die OCR-Geschwindigkeit beeinflusst, wenn Sie Bilder in C# in Text umwandeln, ist die Eingabequalität. Eine höhere DPI (~200 dpi) mit minimalem Rauschen liefert die schnellsten und genauesten Ergebnisse.
Während IronOCR hervorragend darin ist, unvollkommene Dokumente zu korrigieren, erfordert diese Verbesserung zusätzliche Rechenzeit.
Wählen Sie Bildformate mit minimalen Kompressionsartefakten. TIFF und PNG führen in der Regel zu schnelleren Ergebnissen als JPEG aufgrund geringeren digitalen Rauschens.
Welche Bildfilter verbessern die OCR-Geschwindigkeit?
Die folgenden Filter können die Leistung in Ihrem C# OCR Bild-zu-Text-Arbeitsablauf erheblich verbessern:
OcrInput.Rotate(double degrees): Dreht Bilder im Uhrzeigersinn (negativ für gegen den Uhrzeigersinn)OcrInput.Binarize(): Konvertiert in Schwarz/Weiß und verbessert so die Leistung in Situationen mit geringem KontrastOcrInput.ToGrayScale(): Konvertiert in Graustufen für mögliche GeschwindigkeitsverbesserungenOcrInput.Contrast(): Passt den Kontrast automatisch an, um eine höhere Genauigkeit zu erzielenOcrInput.DeNoise(): Entfernt digitale Artefakte, wenn Rauschen zu erwarten istOcrInput.Invert(): Kehrt die Farben für weiß-auf-schwarzem Text umOcrInput.Dilate(): Erweitert TextgrenzenOcrInput.Erode(): Reduziert TextgrenzenOcrInput.Deskew(): Korrigiert die Ausrichtung – unerlässlich bei schrägen DokumentenOcrInput.DeepCleanBackgroundNoise(): Aggressive RauschunterdrückungOcrInput.EnhanceResolution: Verbessert die Bildqualität bei niedriger AuflösungOcrInput.DetectPageOrientation(): Erkennt und korrigiert Seitenrotation. Übergeben Sie einOrientationDetectionMode, um den Kompromiss zwischen Genauigkeit und Geschwindigkeit zu steuern:Fast,Balanced,DetailedoderExtremeDetailed(hinzugefügt in v2025.8.6)
Scale() und EnhanceResolution() sind aufgrund eines bekannten Problems in v2025.12.3 nicht mit SaveAsSearchablePdf() kompatibel. Alle anderen Filter funktionieren korrekt mit der durchsuchbaren PDF-Ausgabe.
Wie konfigurieren Sie IronOCR für maximale Geschwindigkeit?
Verwenden Sie diese Einstellungen zur Geschwindigkeitsoptimierung bei hochwertigen Scans:
using IronOcr;
// Configure for speed - ideal for clean documents
IronTesseract ocr = new IronTesseract();
// Exclude problematic characters to speed up recognition
ocr.Configuration.BlackListCharacters = "~`$#^*_{[]}|\\";
// Use automatic page segmentation
ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
// Select fast English language pack
ocr.Language = OcrLanguage.EnglishFast;
using (OcrInput input = new OcrInput())
{
// Load specific pages from document
int[] pageIndices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
// Read with optimized settings
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
}using IronOcr;
// Configure for speed - ideal for clean documents
IronTesseract ocr = new IronTesseract();
// Exclude problematic characters to speed up recognition
ocr.Configuration.BlackListCharacters = "~`$#^*_{[]}|\\";
// Use automatic page segmentation
ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
// Select fast English language pack
ocr.Language = OcrLanguage.EnglishFast;
using (OcrInput input = new OcrInput())
{
// Load specific pages from document
int[] pageIndices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
// Read with optimized settings
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
}Imports IronOcr
' Configure for speed - ideal for clean documents
Private ocr As New IronTesseract()
' Exclude problematic characters to speed up recognition
ocr.Configuration.BlackListCharacters = "~`$#^*_{[]}|\"
' Use automatic page segmentation
ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
' Select fast English language pack
ocr.Language = OcrLanguage.EnglishFast
Using input As New OcrInput()
' Load specific pages from document
Dim pageIndices() As Integer = { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageIndices)
' Read with optimized settings
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End UsingDiese optimierte Konfiguration hält 99,8% Genauigkeit bei gleichzeitiger Verbesserung der Geschwindigkeit um 35% gegenüber den Standardeinstellungen.
Wie Sie bestimmte Bildbereiche mit C# OCR lesen können?
Das folgende Iron Tesseract C#-Beispiel zeigt, wie man mit System.Drawing.Rectangle bestimmte Regionen anspricht. Diese Technik ist von unschätzbarem Wert für die Verarbeitung standardisierter Formulare, bei denen Text an vorhersehbaren Stellen erscheint.
Kann IronOCR zugeschnittene Bereiche für schnellere Ergebnisse verarbeiten?
Mit pixelbasierten Koordinaten können Sie die OCR auf bestimmte Bereiche begrenzen, die Geschwindigkeit erheblich verbessern und unerwünschte Textextraktion verhindern:
using IronOcr;
using IronSoftware.Drawing;
// Initialize OCR engine for targeted region processing
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Define exact region for OCR - coordinates in pixels
var contentArea = new System.Drawing.Rectangle(
x: 215,
y: 1250,
width: 1335,
height: 280
);
// Load image with specific area - perfect for forms and invoices
input.LoadImage("img/ComSci.png", contentArea);
// Process only the defined region
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
}using IronOcr;
using IronSoftware.Drawing;
// Initialize OCR engine for targeted region processing
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Define exact region for OCR - coordinates in pixels
var contentArea = new System.Drawing.Rectangle(
x: 215,
y: 1250,
width: 1335,
height: 280
);
// Load image with specific area - perfect for forms and invoices
input.LoadImage("img/ComSci.png", contentArea);
// Process only the defined region
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
}Imports IronOcr
Imports IronSoftware.Drawing
' Initialize OCR engine for targeted region processing
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Define exact region for OCR - coordinates in pixels
Dim contentArea As New System.Drawing.Rectangle(215, 1250, 1335, 280)
' Load image with specific area - perfect for forms and invoices
input.LoadImage("img/ComSci.png", contentArea)
' Process only the defined region
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End UsingDieser gezielte Ansatz bringt eine 41% Geschwindigkeitsverbesserung, während nur relevanter Text extrahiert wird. Es eignet sich ideal für strukturierte Dokumente wie Rechnungen, Schecks und Formulare. Die gleiche Zuschneidemethode funktioniert nahtlos mit PDF-OCR-Operationen.
 Dokument, das präzise regionsbasierte Textextraktion mithilfe der Rechteckauswahl von IronOCR demonstriert
Dokument, das präzise regionsbasierte Textextraktion mithilfe der Rechteckauswahl von IronOCR demonstriert
Wie viele Sprachen unterstützt IronOCR?
IronOCR bietet 127 internationale Sprachen über praktische Sprachpakete an. Laden Sie sie als DLLs von unserer Website oder über den NuGet Package Manager herunter.
Installieren Sie die Sprachpakete über die NuGet-Oberfläche ('IronOcr.Languages' suchen) oder besuchen Sie die vollständige Liste der Sprachpakete.
Unterstützte Sprachen sind darunter Arabisch, Chinesisch (Vereinfacht/Traditionell), Japanisch, Koreanisch, Hindi, Russisch, Deutsch, Französisch, Spanisch und 115+ andere, die jeweils für eine genaue Texterkennung optimiert sind.
Wie implementiert man OCR in mehreren Sprachen?
Dieses IronOCR C#-Tutorial-Beispiel zeigt die Erkennung von arabischem Text:
Install-Package IronOcr.Languages.Arabic

IronOCR extrahiert präzise arabischen Text aus einem GIF-Bild
// Install-Package IronOcr.Languages.Arabic
using IronOcr;
// Configure for Arabic language OCR
var ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using (var input = new OcrInput())
{
// Load Arabic text image
input.LoadImage("img/arabic.gif");
// IronOCR handles low-quality Arabic text that standard Tesseract cannot
var result = ocr.Read(input);
// Save to file (console may not display Arabic correctly)
result.SaveAsTextFile("arabic.txt");
}// Install-Package IronOcr.Languages.Arabic
using IronOcr;
// Configure for Arabic language OCR
var ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using (var input = new OcrInput())
{
// Load Arabic text image
input.LoadImage("img/arabic.gif");
// IronOCR handles low-quality Arabic text that standard Tesseract cannot
var result = ocr.Read(input);
// Save to file (console may not display Arabic correctly)
result.SaveAsTextFile("arabic.txt");
}Imports IronOcr
' Configure for Arabic language OCR
Dim ocr As New IronTesseract()
ocr.Language = OcrLanguage.Arabic
Using input As New OcrInput()
' Load Arabic text image
input.LoadImage("img/arabic.gif")
' IronOCR handles low-quality Arabic text that standard Tesseract cannot
Dim result = ocr.Read(input)
' Save to file (console may not display Arabic correctly)
result.SaveAsTextFile("arabic.txt")
End UsingKann IronOCR Dokumente mit mehreren Sprachen verarbeiten?
Wenn Dokumente gemischte Sprachen enthalten, konfigurieren Sie IronOCR für die Unterstützung mehrerer Sprachen:
Install-Package IronOcr.Languages.ChineseSimplified
// Multi-language OCR configuration
using IronOcr;
var ocr = new IronTesseract();
// Set primary language
ocr.Language = OcrLanguage.ChineseSimplified;
// Add secondary languages as needed
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Custom .traineddata files can be added for specialized recognition
// ocr.AddSecondaryLanguage("path/to/custom.traineddata");
using (var input = new OcrInput())
{
// Process multi-language document
input.LoadImage("img/MultiLanguage.jpeg");
var result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");
}// Multi-language OCR configuration
using IronOcr;
var ocr = new IronTesseract();
// Set primary language
ocr.Language = OcrLanguage.ChineseSimplified;
// Add secondary languages as needed
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Custom .traineddata files can be added for specialized recognition
// ocr.AddSecondaryLanguage("path/to/custom.traineddata");
using (var input = new OcrInput())
{
// Process multi-language document
input.LoadImage("img/MultiLanguage.jpeg");
var result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");
}Imports IronOcr
' Multi-language OCR configuration
Dim ocr As New IronTesseract()
' Set primary language
ocr.Language = OcrLanguage.ChineseSimplified
' Add secondary languages as needed
ocr.AddSecondaryLanguage(OcrLanguage.English)
' Custom .traineddata files can be added for specialized recognition
' ocr.AddSecondaryLanguage("path/to/custom.traineddata")
Using input As New OcrInput()
' Process multi-language document
input.LoadImage("img/MultiLanguage.jpeg")
Dim result = ocr.Read(input)
result.SaveAsTextFile("MultiLanguage.txt")
End UsingWie man mehrseitige Dokumente mit C# OCR verarbeitet?
IronOCR fügt mehrere Seiten oder Bilder nahtlos zu einem einzigen OcrResult zusammen. Diese Funktion ermöglicht leistungsstarke Fähigkeiten, wie das Erstellen von durchsuchbaren PDFs und das Extrahieren von Text aus ganzen Dokumentensätzen.
Kombinieren Sie verschiedene Quellen - Bilder, TIFF-Rahmen und PDF-Seiten - in einem einzigen OCR-Vorgang:
// Multi-source document processing
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Add various image formats
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
// Process specific frames from multi-frame images
int[] frameNumbers = { 1, 2 };
input.LoadImageFrames("image3.gif", frameNumbers);
// Process all sources together
OcrResult result = ocr.Read(input);
// Verify page count
Console.WriteLine($"{result.Pages.Count} Pages processed.");
}// Multi-source document processing
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Add various image formats
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
// Process specific frames from multi-frame images
int[] frameNumbers = { 1, 2 };
input.LoadImageFrames("image3.gif", frameNumbers);
// Process all sources together
OcrResult result = ocr.Read(input);
// Verify page count
Console.WriteLine($"{result.Pages.Count} Pages processed.");
}Imports IronOcr
' Multi-source document processing
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Add various image formats
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
' Process specific frames from multi-frame images
Dim frameNumbers As Integer() = {1, 2}
input.LoadImageFrames("image3.gif", frameNumbers)
' Process all sources together
Dim result As OcrResult = ocr.Read(input)
' Verify page count
Console.WriteLine($"{result.Pages.Count} Pages processed.")
End UsingVerarbeiten Sie alle Seiten einer TIFF-Datei effizient:
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Define pages to process (0-based indexing)
int[] pageIndices = new int[] { 0, 1 };
// Load specific TIFF frames
input.LoadImageFrames("MultiFrame.Tiff", pageIndices);
// Extract text from all frames
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Count} Pages processed");
}using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Define pages to process (0-based indexing)
int[] pageIndices = new int[] { 0, 1 };
// Load specific TIFF frames
input.LoadImageFrames("MultiFrame.Tiff", pageIndices);
// Extract text from all frames
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Count} Pages processed");
}Imports IronOcr
Private ocr As New IronTesseract()
Using input As New OcrInput()
' Define pages to process (0-based indexing)
Dim pageIndices() As Integer = { 0, 1 }
' Load specific TIFF frames
input.LoadImageFrames("MultiFrame.Tiff", pageIndices)
' Extract text from all frames
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
Console.WriteLine($"{result.Pages.Count} Pages processed")
End UsingKonvertieren Sie TIFFs oder PDFs in durchsuchbare Formate:
using System;
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Set document metadata
input.Title = "Quarterly Report";
// Combine multiple sources
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
// Add specific frames from animated images
int[] gifFrames = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", gifFrames);
// Create searchable PDF
OcrResult result = ocr.Read(input);
// Pass true to apply any active OcrInput filters to the searchable PDF output (added v2025.5.11)
result.SaveAsSearchablePdf("searchable.pdf", true);
}using System;
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Set document metadata
input.Title = "Quarterly Report";
// Combine multiple sources
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
// Add specific frames from animated images
int[] gifFrames = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", gifFrames);
// Create searchable PDF
OcrResult result = ocr.Read(input);
// Pass true to apply any active OcrInput filters to the searchable PDF output (added v2025.5.11)
result.SaveAsSearchablePdf("searchable.pdf", true);
}Imports System
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Set document metadata
input.Title = "Quarterly Report"
' Combine multiple sources
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
' Add specific frames from animated images
Dim gifFrames As Integer() = {1, 2}
input.LoadImageFrames("image3.gif", gifFrames)
' Create searchable PDF
Dim result As OcrResult = ocr.Read(input)
' Pass true to apply any active OcrInput filters to the searchable PDF output (added v2025.5.11)
result.SaveAsSearchablePdf("searchable.pdf", True)
End UsingKonvertieren Sie vorhandene PDFs in durchsuchbare Versionen:
using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set PDF metadata
input.Title = "Annual Report 2024";
// Process existing PDF
input.LoadPdf("example.pdf", "password");
// Generate searchable version
var result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set PDF metadata
input.Title = "Annual Report 2024";
// Process existing PDF
input.LoadPdf("example.pdf", "password");
// Generate searchable version
var result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}Imports IronOcr
Private ocr = New IronTesseract()
Using input = New OcrInput()
' Set PDF metadata
input.Title = "Annual Report 2024"
' Process existing PDF
input.LoadPdf("example.pdf", "password")
' Generate searchable version
Dim result = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")
End UsingWenden Sie die gleiche Technik auf TIFF-Konvertierungen an:
using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Configure document properties
input.Title = "Scanned Archive Document";
// Select pages to process
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Create searchable PDF from TIFF
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Configure document properties
input.Title = "Scanned Archive Document";
// Select pages to process
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Create searchable PDF from TIFF
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}Imports IronOcr
Private ocr = New IronTesseract()
Using input = New OcrInput()
' Configure document properties
input.Title = "Scanned Archive Document"
' Select pages to process
Dim pageIndices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageIndices)
' Create searchable PDF from TIFF
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")
End UsingWie exportiere ich OCR-Ergebnisse als HOCR HTML?
IronOCR unterstützt den HOCR HTML-Export und ermöglicht strukturierte PDF zu HTML- und TIFF zu HTML-Konvertierungen bei gleichzeitiger Beibehaltung der Layoutinformationen:
using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set HTML title
input.Title = "Document Archive";
// Process multiple document types
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf", "password");
// Add TIFF pages
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Export as HOCR with position data
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");
}using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set HTML title
input.Title = "Document Archive";
// Process multiple document types
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf", "password");
// Add TIFF pages
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Export as HOCR with position data
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");
}Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Set HTML title
input.Title = "Document Archive"
' Process multiple document types
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf", "password")
' Add TIFF pages
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Export as HOCR with position data
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")
End UsingKann IronOCR Barcodes zusammen mit Text lesen?
IronOCR kombiniert einzigartig die Texterkennung mit Barcode-Lesefunktionen und eliminiert die Notwendigkeit für separate Bibliotheken:
// Enable combined text and barcode recognition
using IronOcr;
var ocr = new IronTesseract();
// Enable barcode detection
ocr.Configuration.ReadBarCodes = true;
using (var input = new OcrInput())
{
// Load image containing both text and barcodes
input.LoadImage("img/Barcode.png");
// Process both text and barcodes
var result = ocr.Read(input);
// Extract barcode data
foreach (var barcode in result.Barcodes)
{
Console.WriteLine($"Barcode Value: {barcode.Value}");
Console.WriteLine($"Type: {barcode.Type}, Location: {barcode.Location}");
}
}// Enable combined text and barcode recognition
using IronOcr;
var ocr = new IronTesseract();
// Enable barcode detection
ocr.Configuration.ReadBarCodes = true;
using (var input = new OcrInput())
{
// Load image containing both text and barcodes
input.LoadImage("img/Barcode.png");
// Process both text and barcodes
var result = ocr.Read(input);
// Extract barcode data
foreach (var barcode in result.Barcodes)
{
Console.WriteLine($"Barcode Value: {barcode.Value}");
Console.WriteLine($"Type: {barcode.Type}, Location: {barcode.Location}");
}
}Imports IronOcr
Dim ocr As New IronTesseract()
' Enable barcode detection
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
' Load image containing both text and barcodes
input.LoadImage("img/Barcode.png")
' Process both text and barcodes
Dim result = ocr.Read(input)
' Extract barcode data
For Each barcode In result.Barcodes
Console.WriteLine($"Barcode Value: {barcode.Value}")
Console.WriteLine($"Type: {barcode.Type}, Location: {barcode.Location}")
Next
End UsingWie greife ich auf detaillierte OCR-Ergebnisse und Metadaten zu?
Das IronOCR-Ergebnisobjekt bietet umfassende Daten, die fortgeschrittene Entwickler für anspruchsvolle Anwendungen nutzen können.
Jedes OcrResult enthält hierarchische Sammlungen: Seiten, Absätze, Zeilen, WORDs und Zeichen. Alle Elemente enthalten detaillierte Metadaten wie Standort, Schriftinformationen und Vertrauenswerte.
Einzelelemente (Absätze, Wörter, Barcodes) können als Bilder oder Bitmaps für die weitere Verarbeitung exportiert werden:
using System;
using IronOcr;
using IronSoftware.Drawing;
// Configure with barcode support
IronTesseract ocr = new IronTesseract
{
Configuration = { ReadBarCodes = true }
};
using OcrInput input = new OcrInput();
// Process multi-page document
int[] pageIndices = { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
OcrResult result = ocr.Read(input);
// Navigate the complete results hierarchy
foreach (var page in result.Pages)
{
// Page-level data
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// Extract page elements
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap();
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Paragraph properties
int paragraphNumber = paragraph.ParagraphNumber;
string paragraphText = paragraph.Text;
double paragraphConfidence = paragraph.Confidence;
var textDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Line details including baseline information
string lineText = line.Text;
double lineConfidence = line.Confidence;
double baselineAngle = line.BaselineAngle;
double baselineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Word-level data
string wordText = word.Text;
double wordConfidence = word.Confidence;
// Font information (when available)
if (word.Font != null)
{
string fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isItalic = word.Font.IsItalic;
}
foreach (var character in word.Characters)
{
// Character-level analysis
string charText = character.Text;
double charConfidence = character.Confidence;
// Alternative character choices for spell-checking
OcrResult.Choice[] alternatives = character.Choices;
}
}
}
}
}using System;
using IronOcr;
using IronSoftware.Drawing;
// Configure with barcode support
IronTesseract ocr = new IronTesseract
{
Configuration = { ReadBarCodes = true }
};
using OcrInput input = new OcrInput();
// Process multi-page document
int[] pageIndices = { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
OcrResult result = ocr.Read(input);
// Navigate the complete results hierarchy
foreach (var page in result.Pages)
{
// Page-level data
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// Extract page elements
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap();
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Paragraph properties
int paragraphNumber = paragraph.ParagraphNumber;
string paragraphText = paragraph.Text;
double paragraphConfidence = paragraph.Confidence;
var textDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Line details including baseline information
string lineText = line.Text;
double lineConfidence = line.Confidence;
double baselineAngle = line.BaselineAngle;
double baselineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Word-level data
string wordText = word.Text;
double wordConfidence = word.Confidence;
// Font information (when available)
if (word.Font != null)
{
string fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isItalic = word.Font.IsItalic;
}
foreach (var character in word.Characters)
{
// Character-level analysis
string charText = character.Text;
double charConfidence = character.Confidence;
// Alternative character choices for spell-checking
OcrResult.Choice[] alternatives = character.Choices;
}
}
}
}
}Imports System
Imports IronOcr
Imports IronSoftware.Drawing
' Configure with barcode support
Private ocr As New IronTesseract With {
.Configuration = { ReadBarCodes = True }
}
Private OcrInput As using
' Process multi-page document
Private pageIndices() As Integer = { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageIndices)
Dim result As OcrResult = ocr.Read(input)
' Navigate the complete results hierarchy
For Each page In result.Pages
' Page-level data
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' Extract page elements
Dim barcodes() As OcrResult.Barcode = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap()
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Paragraph properties
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphConfidence As Double = paragraph.Confidence
Dim textDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Line details including baseline information
Dim lineText As String = line.Text
Dim lineConfidence As Double = line.Confidence
Dim baselineAngle As Double = line.BaselineAngle
Dim baselineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Word-level data
Dim wordText As String = word.Text
Dim wordConfidence As Double = word.Confidence
' Font information (when available)
If word.Font IsNot Nothing Then
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isItalic As Boolean = word.Font.IsItalic
End If
For Each character In word.Characters
' Character-level analysis
Dim charText As String = character.Text
Dim charConfidence As Double = character.Confidence
' Alternative character choices for spell-checking
Dim alternatives() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageZusammenfassung
IronOCR bietet C#-Entwicklern die fortschrittlichste Tesseract-API-Implementierung, die nahtlos über Windows, Linux und Mac hinweg läuft. Seine Fähigkeit, Text aus Bildern mit IronOCR genau zu lesen - auch aus unvollkommenen Dokumenten - hebt es von grundlegenden OCR-Lösungen ab.
Die einzigartigen Funktionen der Bibliothek umfassen integriertes Barcode-Lesen und die Fähigkeit, Ergebnisse als durchsuchbare PDFs oder HOCR HTML zu exportieren, Funktionen, die in Standard-Tesseract-Implementierungen nicht verfügbar sind.
Weiterführende Schritte
Um IronOCR weiter zu meistern:
- Entdecken Sie unseren umfassenden Einstiegsguide
- Durchsuchen Sie praktische C#-Codebeispiele
- Siehe die detaillierte API-Dokumentation
Quellcodedownload
Bereit, die C# OCR Bild-zu-Text-Konvertierung in Ihren Anwendungen zu implementieren? Laden Sie IronOCR herunter und starten Sie noch heute Ihre kostenlose Testversion.
Häufig gestellte Fragen
Wie kann ich Bilder in C# ohne Verwendung von Tesseract in Text umwandeln?
Sie können IronOCR verwenden, um Bilder in C# ohne Tesseract in Text umzuwandeln. IronOCR vereinfacht den Prozess mit eingebauten Methoden, die die Umwandlung von Bild zu Text direkt abwickeln.
Wie verbessere ich die OCR-Genauigkeit bei schlechten Bildern?
IronOCR bietet Bildfilter wie Input.Deskew() und Input.DeNoise(), die zur Verbesserung von Bildern von schlechter Qualität durch Begradigung und Rauschunterdrückung verwendet werden können, wodurch die OCR-Genauigkeit erheblich verbessert wird.
Welche Schritte sind nötig, um Text aus einem mehrseitigen Dokument mit OCR in C# zu extrahieren?
Um Text aus mehrseitigen Dokumenten zu extrahieren, können Sie mit IronOCR jede Seite mit Methoden wie LoadPdf() für PDFs oder TIFF-Dateien laden und verarbeiten und jede Seite effektiv in Text umwandeln.
Ist es möglich, Barcodes und Text gleichzeitig aus einem Bild zu lesen?
Ja, IronOCR kann sowohl Text als auch Barcodes aus einem einzelnen Bild lesen. Sie können das Barcode-Lesen mit ocr.Configuration.ReadBarCodes = true aktivieren, was die Extraktion sowohl von Text- als auch Barcode-Daten ermöglicht.
Wie kann ich OCR für die Verarbeitung von Dokumenten in mehreren Sprachen einrichten?
IronOCR unterstützt über 125 Sprachen und ermöglicht es Ihnen, eine Primärsprache mit ocr.Language einzustellen und zusätzliche Sprachen mit ocr.AddSecondaryLanguage() für die mehrsprachige Dokumentenverarbeitung hinzuzufügen.
Welche Methoden gibt es, um OCR-Ergebnisse in verschiedenen Formaten zu exportieren?
IronOCR bietet mehrere Methoden zum Exportieren von OCR-Ergebnissen, wie z.B. SaveAsSearchablePdf() für PDFs, SaveAsTextFile() für reinen Text und SaveAsHocrFile() für das HOCR-HTML-Format.
Wie kann ich die OCR-Verarbeitungsgeschwindigkeit für große Bilddateien optimieren?
Um die OCR-Verarbeitungsgeschwindigkeit zu optimieren, verwenden Sie IronOCR's OcrLanguage.EnglishFast für schnellere Spracherkennung und definieren Sie bestimmte Bereiche für OCR mit System.Drawing.Rectangle, um die Verarbeitungszeit zu reduzieren.
Wie gehe ich mit der OCR-Verarbeitung geschützter PDF-Dateien um?
Beim Umgang mit geschützten PDFs verwenden Sie die LoadPdf()-Methode zusammen mit dem richtigen Passwort. IronOCR verarbeitet bildbasierte PDFs, indem es Seiten automatisch in Bilder konvertiert für die OCR-Verarbeitung.
Was sollte ich tun, wenn die OCR-Ergebnisse nicht genau sind?
Wenn OCR-Ergebnisse ungenau sind, ziehen Sie in Betracht, die Bildverbesserungsfunktionen von IronOCR wie Input.Deskew() und Input.DeNoise() zu verwenden, und stellen Sie sicher, dass die richtigen Sprachpakete installiert sind.
Kann ich den OCR-Prozess anpassen, um bestimmte Zeichen auszuschließen?
Ja, IronOCR ermöglicht die Anpassung des OCR-Prozesses durch die Verwendung der BlackListCharacters-Eigenschaft, um bestimmte Zeichen auszuschließen und so die Genauigkeit zu verbessern und die Verarbeitung zu beschleunigen, indem sich nur auf relevanten Text konzentriert wird.



Scrollst du immer noch?
Sie brauchen schnell einen Beweis? PM > Install-Package IronOcr
Führen Sie ein Beispiel aus und beobachten Sie, wie Ihr Bild zu durchsuchbarem Text wird.










