

Jak zbudować usługę OCR w Azure przy użyciu IronOCR
Firma Iron Software stworzyła bibliotekę OCR (Optical Character Recognition), która eliminuje problemy z interoperacyjnością związane z integracją Azure OCR. Praca z bibliotekami OCR na platformie Azure zawsze była dla programistów nieco uciążliwa. Rozwiązaniem tego i wielu innych problemów związanych z OCR jest IronOCR.
Funkcje IronOCR dla platformy Microsoft Azure
IronOCR zawiera następujące funkcje do tworzenia usługi OCR na platformie Microsoft Azure:
- Przekształca pliki PDF w dokumenty z możliwością wyszukiwania, co ułatwia wyodrębnianie tekstu
- Przekształca obrazy w dokumenty z możliwością wyszukiwania poprzez wyodrębnianie tekstu z obrazów
- Odczytuje zarówno kody kreskowe, jak i kody QR
- Wyjątkowa dokładność
- Działa lokalnie i nie wymaga SaaS (Software as a Service), czyli modelu dystrybucji oprogramowania, w którym dostawca usług w chmurze, taki jak Microsoft Azure, hostuje różne aplikacje i udostępnia je użytkownikom końcowym.
- Błyskawiczna szybkość
Przyjrzyjmy się, w jaki sposób najlepszy silnik OCR, IronOCR firmy Iron Software, ułatwia programistom wyodrębnianie tekstu z dowolnego dokumentu wejściowego.
Zacznijmy od usługi Azure OCR
Aby rozpocząć pracę z przykładem, musimy najpierw zainstalować IronOCR.
- Utwórz nową aplikację konsolową w języku C#.
- Zainstaluj IronOCR za pośrednictwem NuGet, wpisując:
Install-Package IronOcrlub wybierając Zarządzaj pakietami NuGet i szukając IronOCR. Przykład znajduje się poniżej. -
Edytuj swój plik
Program.cs, aby wyglądał jak poniżej:- Importujemy przestrzeń nazw IronOcr, aby wykorzystać jej możliwości OCR do odczytania i wyodrębnienia zawartości pliku PDF.
- Tworzymy nowy obiekt IronTesseract, aby móc wyodrębnić tekst z obrazu.
using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string[] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); // Read PNG image File
Console.WriteLine(result.Text); // Output extracted text to console
Console.ReadLine();
}
}
}
}using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string[] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); // Read PNG image File
Console.WriteLine(result.Text); // Output extracted text to console
Console.ReadLine();
}
}
}
}Imports IronOcr
Imports System
Namespace IronOCR_Ex
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim ocr = New IronTesseract()
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim result = ocr.Read(Input) ' Read PNG image File
Console.WriteLine(result.Text) ' Output extracted text to console
Console.ReadLine()
End Using
End Sub
End Class
End Namespace- Następnie otwieramy obraz o nazwie Purgatory.PNG. Ten obrazek pochodzi z "Boskiej komedii" Dantego – jednej z moich ulubionych książek. Zdjęcie wygląda tak, jak na poniższym obrazku.

Rysunek 2 – Tekst, który ma zostać wyodrębniony za pomocą funkcji optycznego rozpoznawania znaków IronOCR
- Wynik po wyodrębnieniu powyższego tekstu z tekstu na powyższym obrazku wejściowym.
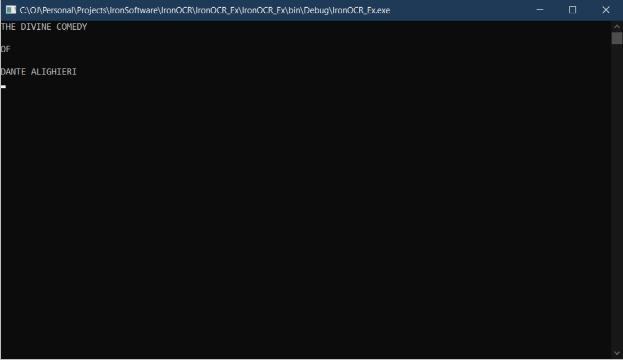
Rysunek 3 – Wyodrębniony tekst
- Zróbmy to samo z dokumentem PDF. Dokument PDF zawiera ten sam tekst do wyodrębnienia, co rysunek 2.
Jedyna różnica polega na tym, że zamiast obrazu użyjemy dokumentu PDF. Wprowadź następujący kod:
var OCR = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; // Give title to input document
// Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var result = OCR.Read(input); // Read the input file
result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
}var OCR = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; // Give title to input document
// Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var result = OCR.Read(input); // Read the input file
result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
}Dim OCR = New IronTesseract()
Using input = New OcrInput()
input.Title = "Divine Comedy - Purgatory" ' Give title to input document
' Supply optional password and name of document
input.AddPdf("..\Documents\Purgatorio.pdf", "dante")
Dim result = OCR.Read(input) ' Read the input file
result.SaveAsSearchablePdf("SearchablePDFDocument.pdf")
End UsingTen kod jest prawie taki sam jak poprzedni, który wyodrębnia tekst z obrazu.
Tutaj korzystamy z metody OcrInput, aby odczytać bieżący dokument PDF, w tym przypadku: Purgatorio.pdf. Jeśli w pliku PDF znajdują się metadane, takie jak tytuł lub hasło, możemy je również uwzględnić.
Wynik jest zapisywany jako dokument PDF z funkcją wyszukiwania, w którym można wyszukiwać tekst.
Uwaga: jeśli plik PDF jest zbyt duży, może zostać zgłoszony wyjątek.
- Wystarczy już o aplikacjach dla systemu Windows; Przyjrzyjmy się, jak możemy wykorzystać OCR w Microsoft Azure.
Zaletą IronOCR jest to, że bardzo dobrze współpracuje z platformą Microsoft Azure jako funkcja Azure w architekturze mikrousług. Oto bardzo krótki przykład tego, jak mogłaby wyglądać funkcja Microsoft Azure Function współpracująca z IronOCR. Ta funkcja Microsoft Azure wyodrębnia tekst z obrazów.
public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} Public Module OCRFunction
Public hcClient As New HttpClient()
<FunctionName("IronOCRFunction_EX")>
Public Async Function Run(<HttpTrigger> ByVal hrRequest As HttpRequest, ByVal ecContext As ExecutionContext) As Task(Of IActionResult)
Dim URI = hrRequest.Query("image")
Dim saStream = Await hcClient.GetStreamAsync(URI)
Dim ocr = New IronTesseract()
Using inputOCR = New OcrInput(saStream)
Dim outputOCR = ocr.Read(inputOCR)
Return New OkObjectResult(outputOCR.Text)
End Using
End Function
End ModulePrzekazuje to obraz otrzymany przez funkcję bezpośrednio do silnika OCR w celu wygenerowania wyodrębnionego tekstu.
Krótkie podsumowanie dotyczące platformy Microsoft Azure według Microsoftu:
Mikrousługi Microsoft Azure to podejście architektoniczne do tworzenia aplikacji, w którym każda podstawowa funkcja lub usługa jest tworzona i wdrażana niezależnie. Architektura mikrousług jest rozproszona i luźno powiązana, więc awaria jednego komponentu nie spowoduje awarii całej aplikacji. Niezależne komponenty współpracują ze sobą i komunikują się za pomocą dobrze zdefiniowanych umów API. Twórz aplikacje oparte na mikrousługach, aby sprostać szybko zmieniającym się potrzebom biznesowym i szybciej wprowadzać nowe funkcje na rynek.
Kilka dodatkowych funkcji IronOCR z .NET lub Microsoft Azure obejmuje:
- Możliwość przeprowadzenia OCR na niemal każdym pliku, obrazie lub pliku PDF.
- Błyskawiczna prędkość przetwarzania danych OCR
- Wyjątkowa dokładność
- Odczytuje kody kreskowe i kody QR
- Działa lokalnie, bez konieczności korzystania z SaaS
- Możliwość przekształcania plików PDF i obrazów w dokumenty z możliwością wyszukiwania
- Doskonała alternatywa dla usługi Azure OCR z pakietu Microsoft Cognitive Services
Filtry obrazów poprawiające wydajność OCR
OcrInput.Rotate- Obraca obrazy o kilka stopni zgodnie z ruchem wskazówek zegara. Aby obrócić w przeciwnym kierunku, użyj liczb ujemnych.OcrInput.Binarize()- Ten filtr obrazu zamienia każdy piksel na czarny lub biały bez pośrednich odcieni. Poprawia to wydajność OCR.OcrInput.ToGrayScale()- Ten filtr obrazu zamienia każdy piksel na odcień szarości. Zwiększa to szybkość OCR.OcrInput.Contrast()- Automatycznie zwiększa kontrast. Ten filtr poprawia szybkość i dokładność OCR w przypadku skanów o niskim kontraście.OcrInput.DeNoise()- Usuwa szumy cyfrowe. Tego filtru należy używać tylko tam, gdzie spodziewane są szumy w dokumentach wejściowych.OcrInput.Invert()- Odwraca każdy kolor.OcrInput.Dilate()- Dylatacja dodaje piksele do krawędzi dowolnego obiektu na obrazie.OcrInput.Erode()- Erozja usuwa piksele z krawędzi obiektów.OcrInput.Deskew()- Obraca obraz tak, aby był właściwie ustawiony i prostopadły. Jest to bardzo przydatne w przypadku OCR, ponieważ tolerancja Tesseracta na przekrzywione skany może wynosić zaledwie 5 stopni.OcrInput.DeepCleanBackgroundNoise()- Usuwanie ciężkich szumów tła.OcrInput.EnhanceResolution- Poprawia rozdzielczość niskiej jakości obrazu.
Wydajność
Poniżej znajduje się przykład:
var OCR = new IronTesseract();
OCR.Configuration.BlackListCharacters = "~`$#^*_}{][|\\";
OCR.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
OCR.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
OCR.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
OCR.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = OCR.Read(Input);
Console.WriteLine(Result.Text);
}var OCR = new IronTesseract();
OCR.Configuration.BlackListCharacters = "~`$#^*_}{][|\\";
OCR.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
OCR.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
OCR.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
OCR.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = OCR.Read(Input);
Console.WriteLine(Result.Text);
}Dim OCR = New IronTesseract()
OCR.Configuration.BlackListCharacters = "~`$#^*_}{][|\"
OCR.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
OCR.Configuration.TesseractVersion = TesseractVersion.Tesseract5
OCR.Configuration.EngineMode = TesseractEngineMode.LstmOnly
OCR.Language = OcrLanguage.EnglishFast
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim Result = OCR.Read(Input)
Console.WriteLine(Result.Text)
End UsingCeny i opcje licencyjne
Istnieją zasadniczo trzy poziomy płatnych licencji, z których wszystkie działają na zasadzie jednorazowego zakupu i dożywotniej licencji.
I tak, są one bezpłatne do celów programistycznych.
Dodatkowe informacje
- Dodatkowe zasoby można znaleźć pod poniższym linkiem: Zasoby
- Dokumentację API można znaleźć tutaj: Dokumentacja API
- Pomoc techniczną dotyczącą produktów IronOCR można znaleźć tutaj: Pomoc techniczna
- Kontakt z Iron Software: Dane kontaktowe
Funkcje IronOCR for .NET korzystających z OCR na platformie Azure i innych systemach
- IronOCR obsługuje 125 języków międzynarodowych. Każdy język jest dostępny w jakości Fast, Standard i Best. Niektóre z dostępnych pakietów językowych to:
- Bułgarski
- Ormiański
- Chorwacki
- Afrikaans
- Duński
- Czeski
- filipiński
- Fiński
- Francuski
- Niemiecki
- Dostępnych jest wiele innych pakietów językowych. Aby je obejrzeć, kliknij poniższy link. Pakiety językowe IronOCR
- Działa od razu po uruchomieniu w środowisku .NET
- Obsługa Xamarin
- Obsługa Mono
- Obsługa platformy Microsoft Azure
- Obsługa Docker na platformie Microsoft Azure
- Obsługuje dokumenty PDF
- Obsługuje pliki TIFF z wieloma ramkami
- Obsługa wszystkich głównych formatów obrazów
- Obsługiwane są następujące wersje .NET Framework:
- .NET Framework 4.5 i nowsze wersje
- .NET Standard 2
- .NET Core 2
- .NET Core 3
- .NET Core 5
- Nie musisz mieć zainstalowanego Tesseract (open-source silnika OCR, który obsługuje Unicode i ponad 100 języków), aby IronOCR działał.
- Ma lepszą dokładność niż Tesseract.
- Ma lepszą szybkość niż Tesseract.
- Koryguje niskiej jakości skany dokumentów lub plików.
- Koryguje niskiej jakości przekrzywione skany dokumentów lub plików.
Czym jest optyczne rozpoznawanie znaków (OCR)?
Według Wikipedii: Optyczne rozpoznawanie znaków to elektroniczna lub mechaniczna konwersja obrazów tekstu pisanego lub drukowanego na tekst zakodowany maszynowo, niezależnie od tego, czy pochodzi z zeskanowanego dokumentu, zdjęcia dokumentu, zdjęcia sceny, czy napisu nakładającego się na obraz. OCR oznacza optyczne rozpoznawanie znaków. Zasadniczo istnieją cztery rodzaje optycznego rozpoznawania znaków:
- OCR - Optyczne Rozpoznawanie Znaków, celuje w tekst pisany na maszynie z dokumentu wejściowego, jeden znak lub glif (elementarny symbol w uzgodnionym zestawie symboli, na przykład, 'a' w różnych fontach) na raz.
- OWR - Optyczne Rozpoznawanie Słów, celuje w tekst pisany na maszynie z dokumentu wejściowego, jedno słowo na raz.
- ICR - Inteligentne Rozpoznawanie Znaków, celuje w tekst drukowany, taki jak pismo drukowane (znaki bez łączenia się z innymi literami) i pismo kursywą, jeden znak lub glif na raz.
- IWR - Inteligentne Rozpoznawanie Słów, celuje w pismo kursywą.
Często Zadawane Pytania
Jak mogę zintegrować funkcje OCR w aplikacji C# na platformie Azure?
Możesz zintegrować funkcje OCR z aplikacją C# na platformie Azure, tworząc nową aplikację konsolową i instalując IronOCR za pośrednictwem NuGet. Użyj polecenia Install-Package IronOcr lub wyszukaj IronOCR w menedżerze pakietów NuGet.
Jakie są zalety korzystania z IronOCR w porównaniu z natywną usługą OCR platformy Azure?
IronOCR oferuje kilka zalet w porównaniu z natywną usługą OCR platformy Azure, w tym większą dokładność, szybsze przetwarzanie oraz możliwość działania lokalnie bez konieczności korzystania z modelu SaaS. Obsługuje również szeroki zakres języków i udostępnia filtry obrazów poprawiające wydajność OCR.
Jak skonfigurować funkcję Microsoft Azure Function do ekstrakcji tekstu za pomocą OCR?
Aby skonfigurować funkcję Microsoft Azure Function do wyodrębniania tekstu za pomocą OCR, można użyć IronOCR do utworzenia funkcji, która wyodrębnia tekst z obrazów. Jest to część architektury mikrousług, umożliwiająca płynną integrację funkcji OCR z aplikacjami Azure.
Czy IronOCR obsługuje wiele języków podczas przetwarzania OCR?
Tak, IronOCR obsługuje 125 języków międzynarodowych, z których każdy jest dostępny w jakości Fast, Standard i Best, co sprawia, że jest wszechstronnym rozwiązaniem do zastosowań globalnych.
Jakie opcje przetwarzania obrazu oferuje IronOCR w celu poprawy dokładności OCR?
IronOCR oferuje szereg opcji przetwarzania obrazów, takich jak Rotate, Binarize, ToGrayScale, Contrast, DeNoise, Invert, Dilate, Erode, Deskew, DeepCleanBackgroundNoise oraz EnhanceResolution, które pozwalają poprawić dokładność i niezawodność wyników OCR.
Czy IronOCR jest kompatybilny z różnymi frameworkami .NET Framework do wdrożenia w Azure?
Tak, IronOCR jest kompatybilny z .NET Framework 4.5 i nowszymi wersjami, .NET Standard 2, .NET Core 2, .NET Core 3 oraz .NET Core 5. Obsługuje również Xamarin i Mono, a także może być wdrażany za pomocą Docker na platformie Microsoft Azure.
Czy potrzebuję dodatkowego oprogramowania, aby uruchomić IronOCR na platformie Azure?
Do uruchomienia IronOCR na platformie Azure nie jest wymagane żadne dodatkowe oprogramowanie. Działa on niezależnie i zapewnia większą dokładność oraz szybkość w porównaniu z Tesseractem, bez konieczności jego instalacji.
Jakie opcje licencyjne są dostępne dla IronOCR?
IronOCR oferuje trzy poziomy płatnych licencji opartych na modelu jednorazowego zakupu i dożywotniej licencji. Licencje te są bezpłatne do celów programistycznych, co zapewnia elastyczność w skalowaniu projektów.
Jak mogę przekonwertować obrazy i pliki PDF na dokumenty z możliwością wyszukiwania za pomocą IronOCR?
IronOCR pozwala konwertować obrazy i pliki PDF na dokumenty z możliwością wyszukiwania, wykorzystując swoje funkcje OCR do wyodrębniania i rozpoznawania tekstu, dzięki czemu można je łatwo przeszukiwać i indeksować.
Jak wygląda proces odczytywania kodów kreskowych i kodów QR za pomocą IronOCR?
IronOCR może odczytywać kody kreskowe i kody QR, wykorzystując wbudowane funkcje do skanowania i wyodrębniania danych z tych kodów, ułatwiając ich integrację z aplikacjami C# w Azure.


Wciąż przewijasz?
Czy chcesz szybko dowodu? PM > Install-Package IronOcr
uruchom próbkę obserwuj, jak twój obraz staje się tekstem z możliwością wyszukiwania.










