

Web Scraping in C# — Daten von Websites extrahieren
IronWebscraper ist eine .NET-Bibliothek für Web Scraping, Webdatenerfassung und Webinhaltsparsing. Es ist eine benutzerfreundliche Bibliothek, die zu Microsoft Visual Studio-Projekten für die Verwendung in der Entwicklung und Produktion hinzugefügt werden kann.
IronWebscraper bietet viele einzigartige Funktionen und Fähigkeiten wie die Kontrolle über erlaubte und verbotene Seiten, Objekte, Medien usw. Es ermöglicht auch das Management mehrerer Identitäten, Webcache und viele andere Funktionen, die wir in diesem Tutorial behandeln werden.
Legen Sie los mit IronWebscraper
Nutzen Sie IronWebScraper heute kostenlos in Ihrem Projekt.
Zielgruppe
Dieses Tutorial richtet sich an Softwareentwickler mit grundlegenden oder fortgeschrittenen Programmierkenntnissen, die Lösungen für erweiterte Scraping-Fähigkeiten (Webseiten-Scraping, Website-Datenerfassung und -extraktion, Webseiten-Inhaltsparsing, Web-Harvesting) entwickeln und implementieren möchten.

Erforderliche Fähigkeiten
- Grundlegende Programmierkenntnisse mit Kenntnissen in einer der Microsoft-Programmiersprachen wie C# oder VB.NET
- Grundlegendes Verständnis von Webtechnologien (HTML, JavaScript, JQuery, CSS usw.) und deren Funktionsweise
- Grundkenntnisse von DOM, XPath, HTML und CSS-Selektoren
Tools
- Microsoft Visual Studio 2010 oder höher
- Webentwickler-Erweiterungen für Browser wie Webinspektor für Chrome oder Firebug für Firefox
Warum Web Scraping? (Gründe und Konzepte)
Wenn Sie ein Produkt oder eine Lösung entwickeln möchten, die die Fähigkeit hat:
- Website-Daten extrahieren
- Vergleich von Inhalten, Preisen, Funktionen usw. von mehreren Websites
- Webseiteninhalte zu scannen und zu cachen
Wenn Sie einen oder mehrere der oben genannten Gründe haben, ist IronWebscraper eine großartige Bibliothek, die Ihren Bedürfnissen entspricht.
Wie installiert man IronWebScraper?
Nachdem Sie ein neues Projekt erstellt haben (siehe Anhang A), können Sie die IronWebScraper-Bibliothek zu Ihrem Projekt hinzufügen, indem Sie die Bibliothek automatisch über NuGet einfügen oder die DLL manuell installieren.
Installation über NuGet
Um die IronWebScraper-Bibliothek mit NuGet zu unserem Projekt hinzuzufügen, können wir dies über die visuelle Oberfläche (NuGet-Paketmanager) oder per Befehl über die Paket-Manager-Konsole tun.
Verwendung des NuGet-Paketmanagers
- Mit der Maus -> Rechtsklick auf den Projektnamen -> NuGet-Paket verwalten auswählen
- Auf der Registerkarte Durchsuchen -> IronWebScraper suchen -> Installieren
- Ok klicken
- Und wir sind fertig
Verwendung der NuGet-Paketkonsole
- Von Tools -> NuGet Package Manager -> Package Manager Console
- Wählen Sie das Projekt Klassenbibliothek als Standardprojekt
- Befehl ausführen ->
Install-Package IronWebScraper
Manuelle Installation
- Weiter zu https://ironsoftware.com
- Klicken Sie auf IronWebscraper oder besuchen Sie die Seite direkt unter der URL https://ironsoftware.com/csharp/webscraper/
- Klicken Sie Download DLL.
- Entpacken Sie die heruntergeladene komprimierte Datei
- Klicken Sie in Visual Studio mit der rechten Maustaste auf Projekt -> Hinzufügen -> Referenz -> Durchsuchen
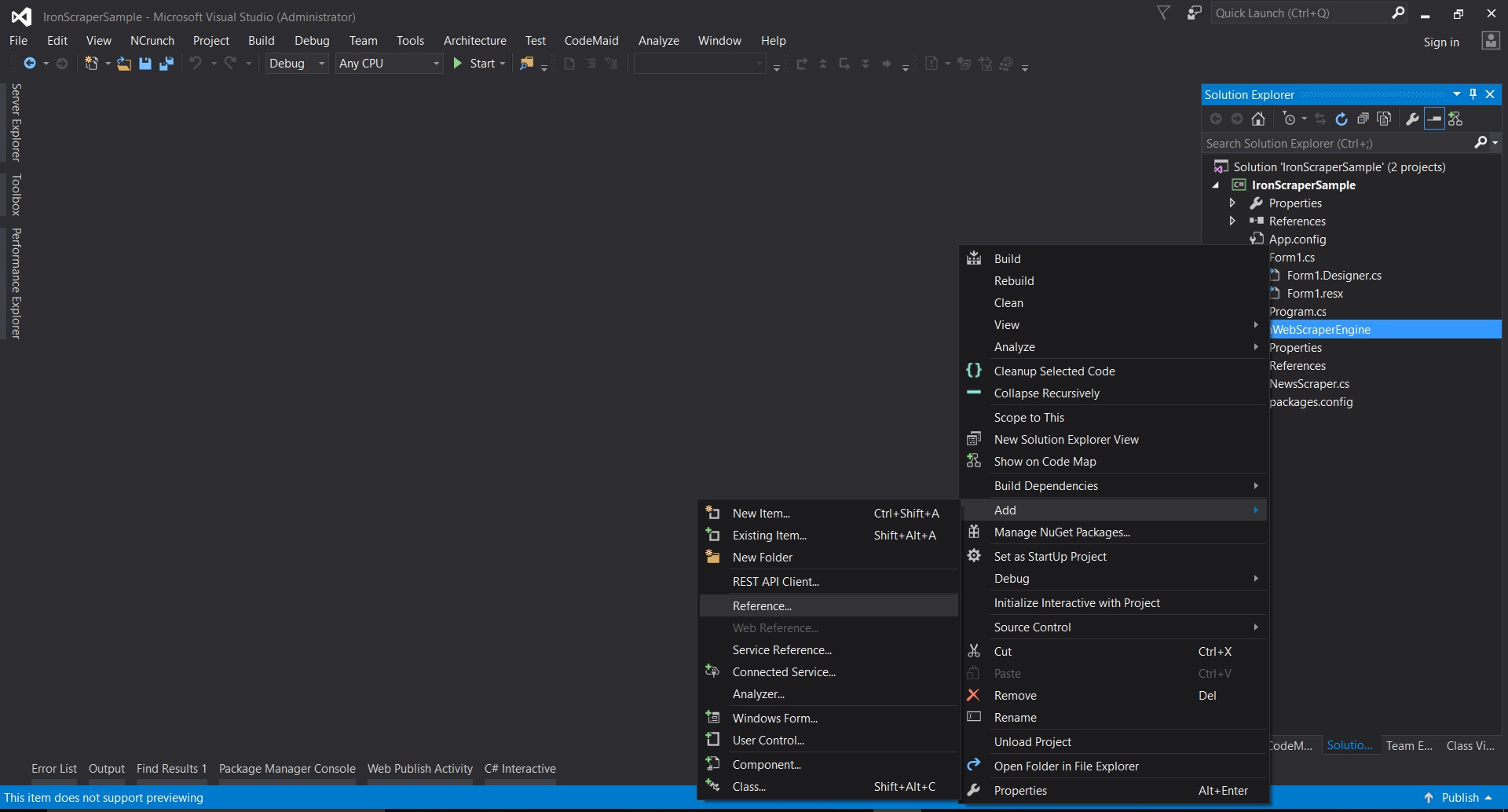
- Gehen Sie zu dem extrahierten Ordner ->
netstandard2.0-> und wählen Sie alle.dllDateien aus
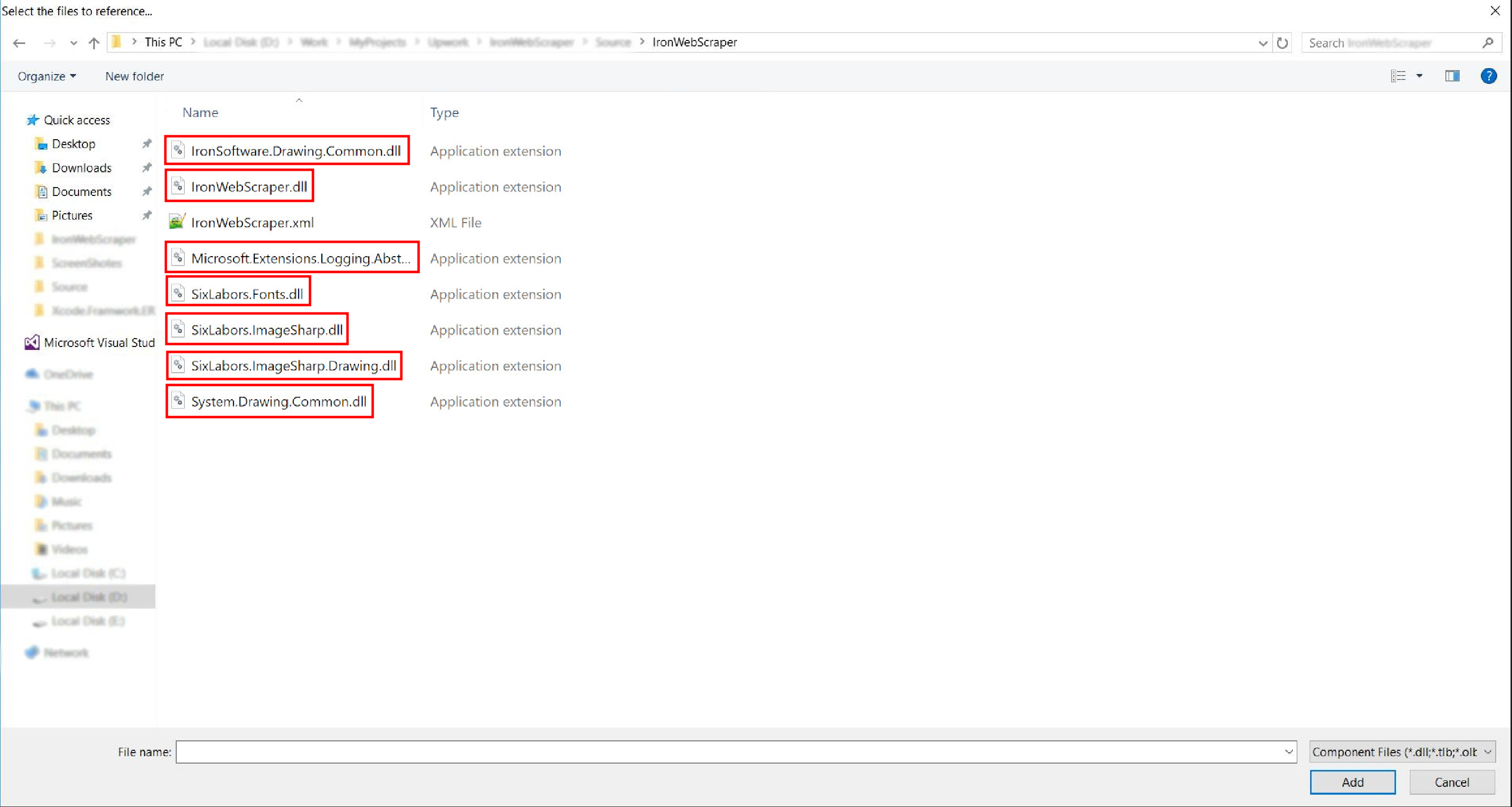
- Und es ist fertig!
HelloScraper - Unser erstes IronWebscraper-Beispiel
Wie üblich beginnen wir mit der Implementierung der Hello Scraper App, um unseren ersten Schritt mit IronWebscraper zu machen.
- Wir haben eine neue Konsolenanwendung mit dem Namen "IronWebScraperSample" erstellt
Schritte zur Erstellung des IronWebScraper-Beispiels
- Erstellen Sie einen Ordner und nennen Sie ihn "HelloScraperSample"
-
Fügen Sie dann eine neue Klasse hinzu und nennen Sie sie "HelloScraper"
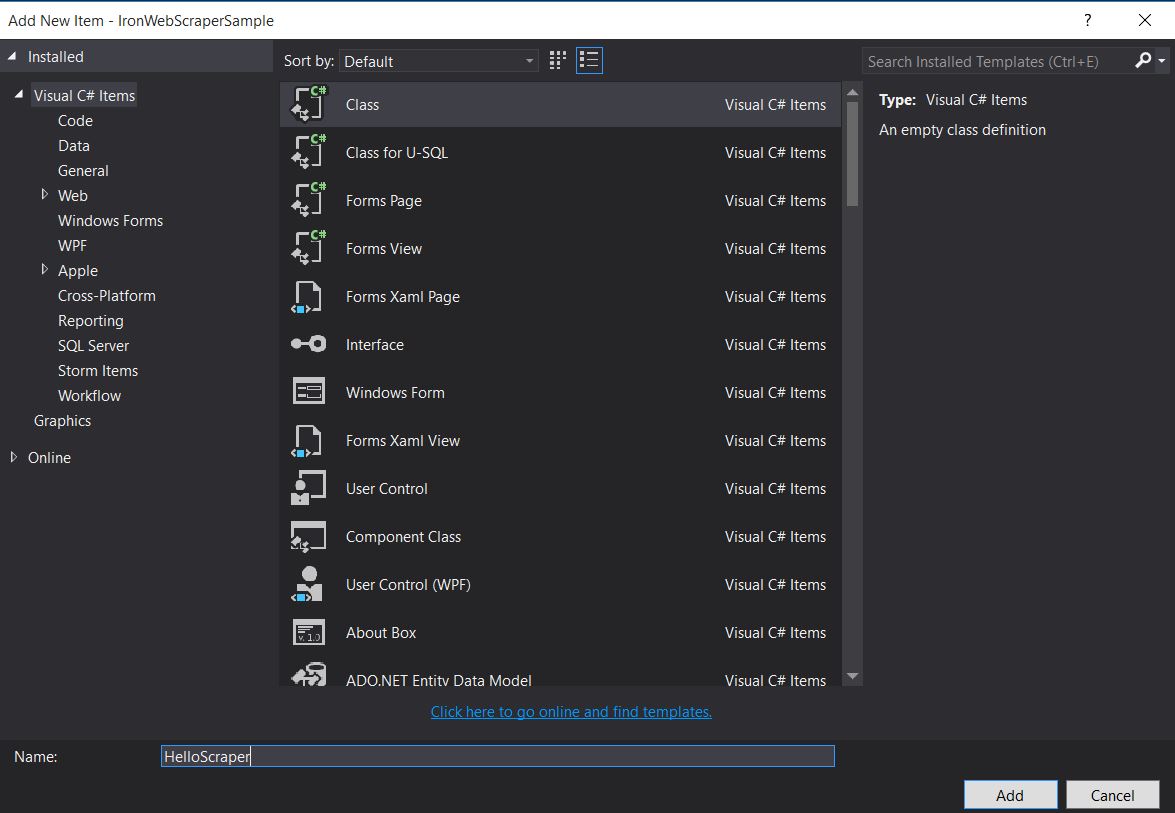
-
Fügen Sie diesen Codeausschnitt zu HelloScraper hinzu
public class HelloScraper : WebScraper { /// <summary> /// Override this method to initialize your web scraper. /// Important tasks will be to request at least one start URL and set allowed/banned domain or URL patterns. /// </summary> public override void Init() { License.LicenseKey = "LicenseKey"; // Write License Key this.LoggingLevel = WebScraper.LogLevel.All; // Log all events this.Request("https://blog.scrapinghub.com", Parse); // Initialize a web request to the given URL } /// <summary> /// Override this method to create the default Response handler for your web scraper. /// If you have multiple page types, you can add additional similar methods. /// </summary> /// <param name="response">The HTTP Response object to parse</param> public override void Parse(Response response) { // Set working directory for the project this.WorkingDirectory = AppSetting.GetAppRoot() + @"\HelloScraperSample\Output\"; // Loop on all links foreach (var titleLink in response.Css("h2.entry-title a")) { // Read link text string title = titleLink.TextContentClean; // Save result to file Scrape(new ScrapedData() { { "Title", title } }, "HelloScraper.json"); } // Loop on all links for pagination if (response.CssExists("div.prev-post > a[href]")) { // Get next page URL var nextPage = response.Css("div.prev-post > a[href]")[0].Attributes["href"]; // Scrape next URL this.Request(nextPage, Parse); } } }public class HelloScraper : WebScraper { /// <summary> /// Override this method to initialize your web scraper. /// Important tasks will be to request at least one start URL and set allowed/banned domain or URL patterns. /// </summary> public override void Init() { License.LicenseKey = "LicenseKey"; // Write License Key this.LoggingLevel = WebScraper.LogLevel.All; // Log all events this.Request("https://blog.scrapinghub.com", Parse); // Initialize a web request to the given URL } /// <summary> /// Override this method to create the default Response handler for your web scraper. /// If you have multiple page types, you can add additional similar methods. /// </summary> /// <param name="response">The HTTP Response object to parse</param> public override void Parse(Response response) { // Set working directory for the project this.WorkingDirectory = AppSetting.GetAppRoot() + @"\HelloScraperSample\Output\"; // Loop on all links foreach (var titleLink in response.Css("h2.entry-title a")) { // Read link text string title = titleLink.TextContentClean; // Save result to file Scrape(new ScrapedData() { { "Title", title } }, "HelloScraper.json"); } // Loop on all links for pagination if (response.CssExists("div.prev-post > a[href]")) { // Get next page URL var nextPage = response.Css("div.prev-post > a[href]")[0].Attributes["href"]; // Scrape next URL this.Request(nextPage, Parse); } } }Public Class HelloScraper Inherits WebScraper ''' <summary> ''' Override this method to initialize your web scraper. ''' Important tasks will be to request at least one start URL and set allowed/banned domain or URL patterns. ''' </summary> Public Overrides Sub Init() License.LicenseKey = "LicenseKey" ' Write License Key Me.LoggingLevel = WebScraper.LogLevel.All ' Log all events Me.Request("https://blog.scrapinghub.com", AddressOf Parse) ' Initialize a web request to the given URL End Sub ''' <summary> ''' Override this method to create the default Response handler for your web scraper. ''' If you have multiple page types, you can add additional similar methods. ''' </summary> ''' <param name="response">The HTTP Response object to parse</param> Public Overrides Sub Parse(ByVal response As Response) ' Set working directory for the project Me.WorkingDirectory = AppSetting.GetAppRoot() & "\HelloScraperSample\Output\" ' Loop on all links For Each titleLink In response.Css("h2.entry-title a") ' Read link text Dim title As String = titleLink.TextContentClean ' Save result to file Scrape(New ScrapedData() From { { "Title", title } }, "HelloScraper.json") Next titleLink ' Loop on all links for pagination If response.CssExists("div.prev-post > a[href]") Then ' Get next page URL Dim nextPage = response.Css("div.prev-post > a[href]")(0).Attributes("href") ' Scrape next URL Me.Request(nextPage, AddressOf Parse) End If End Sub End Class$vbLabelText $csharpLabel -
Um Scrape zu starten, fügen Sie diesen Code zu Main hinzu.
static void Main(string[] args) { // Create Object From Hello Scrape class HelloScraperSample.HelloScraper scrape = new HelloScraperSample.HelloScraper(); // Start Scraping scrape.Start(); }static void Main(string[] args) { // Create Object From Hello Scrape class HelloScraperSample.HelloScraper scrape = new HelloScraperSample.HelloScraper(); // Start Scraping scrape.Start(); }Shared Sub Main(ByVal args() As String) ' Create Object From Hello Scrape class Dim scrape As New HelloScraperSample.HelloScraper() ' Start Scraping scrape.Start() End Sub$vbLabelText $csharpLabel - Das Ergebnis wird in einer Datei mit dem Format
WebScraper.WorkingDirectory/classname.Jsongespeichert
Codeübersicht
Scrape.Start() löst die Scraping-Logik wie folgt aus:
- Ruft die
Init()-Methode auf, um Variablen, Scraper-Eigenschaften und Verhaltensattribute zu initiieren. - Setzt die Startseitierungsanfrage in
Init()mitRequest("https://blog.scrapinghub.com", Parse). - Bearbeitet mehrere HTTP-Anfragen und Threads parallel, wodurch der Code synchron und leichter zu debuggen bleibt.
- Die
Parse()-Methode wird nachInit()ausgelöst, um die Antwort zu bearbeiten, Daten mit CSS-Selektoren zu extrahieren und im JSON-Format zu speichern.
IronWebscraper Bibliotheksfunktionen und Optionen
Die aktualisierte Dokumentation befindet sich in der Zip-Datei, die mit der manuellen Installationsmethode heruntergeladen wurde (IronWebScraper Documentation.chm File), oder Sie können die Online-Dokumentation für das neueste Update der Bibliothek unter https://ironsoftware.com/csharp/webscraper/object-reference/ überprüfen.
Um IronWebScraper in Ihrem Projekt zu verwenden, müssen Sie von der Klasse IronWebScraper.WebScraper erben, die Ihre Klassenbibliothek erweitert und dieser Scraping-Funktionen hinzufügt. Darüber hinaus müssen Sie die Init()- und Parse(Response response)-Methoden implementieren.
namespace IronWebScraperEngine
{
public class NewsScraper : IronWebScraper.WebScraper
{
public override void Init()
{
throw new NotImplementedException();
}
public override void Parse(Response response)
{
throw new NotImplementedException();
}
}
}namespace IronWebScraperEngine
{
public class NewsScraper : IronWebScraper.WebScraper
{
public override void Init()
{
throw new NotImplementedException();
}
public override void Parse(Response response)
{
throw new NotImplementedException();
}
}
}Namespace IronWebScraperEngine
Public Class NewsScraper
Inherits IronWebScraper.WebScraper
Public Overrides Sub Init()
Throw New NotImplementedException()
End Sub
Public Overrides Sub Parse(ByVal response As Response)
Throw New NotImplementedException()
End Sub
End Class
End Namespace| Eigenschaften \ Funktionen | Typ | Beschreibung |
|---|---|---|
Init () |
Methode | Zum Einrichten des Scrapers verwendet |
Parse (Response response) |
Methode | Wird verwendet, um die Logik zu implementieren, die der Scraper verwenden wird, und wie er diese verarbeiten wird. Kann mehrere Methoden für unterschiedliche Seitenverhaltensweisen oder -strukturen implementieren. |
BannedUrls, AllowedUrls, BannedDomains |
Sammlungen | 6. Zum Verbot/Erlauben von URLs/Domains. Ex: BannedUrls.Add("*.zip", "*.exe", "*.gz", "*.pdf"); Unterstützt Platzhalter und reguläre Ausdrücke. |
ObeyRobotsDotTxt |
Boolesch | Wird verwendet, um das Lesen und Befolgen der Direktiven in robots.txt zu aktivieren oder zu deaktivieren. |
ObeyRobotsDotTxtForHost (string Host) |
Methode | Wird verwendet, um das Lesen und Befolgen der Direktiven in robots.txt für eine bestimmte Domain zu aktivieren oder zu deaktivieren. |
Scrape, ScrapeUnique |
Methode | |
ThrottleMode |
Enumeration | Enum Optionen: ByIpAddress, ByDomainHostName. Ermöglicht intelligentes Anfragendrosseln, respektvoll gegenüber den IP-Adressen oder Domain-Hostnamen des Hosts. |
EnableWebCache, EnableWebCache (TimeSpan cacheDuration) |
Methode | Ermöglicht das Cachen von Web-Anfragen. |
MaxHttpConnectionLimit |
Int | Legt die Gesamtanzahl der erlaubten offenen HTTP-Anfragen (Threads) fest. |
RateLimitPerHost |
TimeSpan | Legt die minimale Höflichkeitsverzögerung (Pause) zwischen Anfragen an eine bestimmte Domain oder IP-Adresse fest. |
OpenConnectionLimitPerHost |
Int | Legt die erlaubte Anzahl gleichzeitiger HTTP-Anfragen (Threads) pro Hostnamen oder IP-Adresse fest. |
WorkingDirectory |
string | Legt einen Arbeitsverzeichnis-Pfad zum Speichern von Daten fest. |
Reale Beispiele und Praxis
Scraping einer Online-Film-Website
Lassen Sie uns ein Beispiel erstellen, bei dem wir eine Film-Website scrapen.
Fügen Sie eine neue Klasse hinzu und nennen Sie sie MovieScraper:

HTML-Struktur
Dies ist ein Teil des HTML der Startseite, die wir auf der Website sehen:
<div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/" >
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div><div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/" >
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div>Wie wir sehen können, haben wir eine Film-ID, einen Titel und einen Link zu einer Detailseite. Beginnen wir mit dem Scrapen dieser Daten:
public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movieId = div.GetAttribute("data-movie-id");
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
Scrape(new ScrapedData() { { "MovieId", movieId }, { "MovieTitle", movieTitle } }, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movieId = div.GetAttribute("data-movie-id");
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
Scrape(new ScrapedData() { { "MovieId", movieId }, { "MovieTitle", movieTitle } }, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
Me.Request("www.website.com", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each div In response.Css("#movie-featured > div")
If div.GetAttribute("class") <> "clearfix" Then
Dim movieId = div.GetAttribute("data-movie-id")
Dim link = div.Css("a")(0)
Dim movieTitle = link.TextContentClean
Scrape(New ScrapedData() From {
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
},
"Movie.Jsonl")
End If
Next div
End Sub
End ClassStrukturierte Filmklasse
Um unsere formatierten Daten zu halten, implementieren wir eine Filmklasse:
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
End ClassAktualisieren Sie jetzt unseren Code, um die Movie-Klasse zu verwenden:
public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
Scrape(movie, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
Scrape(movie, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
Me.Request("https://website.com/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each div In response.Css("#movie-featured > div")
If div.GetAttribute("class") <> "clearfix" Then
Dim movie As New Movie With {
.Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
.Title = div.Css("a")(0).TextContentClean,
.URL = div.Css("a")(0).Attributes("href")
}
Scrape(movie, "Movie.Jsonl")
End If
Next div
End Sub
End ClassDetailseite scrapen
Erweitern wir unsere Movie-Klasse um neue Eigenschaften für die detaillierten Informationen:
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
Public Property Description As String
Public Property Genre As List(Of String)
Public Property Actor As List(Of String)
End ClassNavigieren Sie dann zur Detailseite, um sie mit erweiterten Fähigkeiten von IronWebscraper zu scrapen:
public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
movie.Description = div.Css("div.desc")[0].TextContentClean;
movie.Genre = div.Css("div > p > a").Select(element => element.TextContentClean).ToList();
movie.Actor = div.Css("div > p:nth-child(2) > a").Select(element => element.TextContentClean).ToList();
Scrape(movie, "Movie.Jsonl");
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
movie.Description = div.Css("div.desc")[0].TextContentClean;
movie.Genre = div.Css("div > p > a").Select(element => element.TextContentClean).ToList();
movie.Actor = div.Css("div > p:nth-child(2) > a").Select(element => element.TextContentClean).ToList();
Scrape(movie, "Movie.Jsonl");
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
Me.Request("https://domain/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each div In response.Css("#movie-featured > div")
If div.GetAttribute("class") <> "clearfix" Then
Dim movie As New Movie With {
.Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
.Title = div.Css("a")(0).TextContentClean,
.URL = div.Css("a")(0).Attributes("href")
}
Me.Request(movie.URL, AddressOf ParseDetails, New MetaData() From {
{ "movie", movie }
})
End If
Next div
End Sub
Public Sub ParseDetails(ByVal response As Response)
Dim movie = response.MetaData.Get(Of Movie)("movie")
Dim div = response.Css("div.mvic-desc")(0)
movie.Description = div.Css("div.desc")(0).TextContentClean
movie.Genre = div.Css("div > p > a").Select(Function(element) element.TextContentClean).ToList()
movie.Actor = div.Css("div > p:nth-child(2) > a").Select(Function(element) element.TextContentClean).ToList()
Scrape(movie, "Movie.Jsonl")
End Sub
End ClassIronWebscraper Bibliotheksfeatures
HttpIdentity Funktion
Einige Systeme erfordern, dass der Benutzer eingeloggt ist, um Inhalte anzeigen zu können; Verwenden Sie HttpIdentity für Anmeldedaten:
HttpIdentity id = new HttpIdentity
{
NetworkUsername = "username",
NetworkPassword = "pwd"
};
Identities.Add(id);HttpIdentity id = new HttpIdentity
{
NetworkUsername = "username",
NetworkPassword = "pwd"
};
Identities.Add(id);Dim id As New HttpIdentity With {
.NetworkUsername = "username",
.NetworkPassword = "pwd"
}
Identities.Add(id)Webcache aktivieren
Gespeicherte Seiten für die Wiederverwendung während der Entwicklung cachen:
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
EnableWebCache();
this.Request("http://www.WebSite.com", Parse);
}public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
EnableWebCache();
this.Request("http://www.WebSite.com", Parse);
}Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\ShoppingSiteSample\Output\"
EnableWebCache()
Me.Request("http://www.WebSite.com", Parse)
End SubDrosselung
Kontrollieren Sie die Verbindungszahlen und die Geschwindigkeit:
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
this.MaxHttpConnectionLimit = 80;
this.RateLimitPerHost = TimeSpan.FromMilliseconds(50);
this.OpenConnectionLimitPerHost = 25;
this.ObeyRobotsDotTxt = false;
this.ThrottleMode = Throttle.ByDomainHostName;
this.Request("https://www.Website.com", Parse);
}public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
this.MaxHttpConnectionLimit = 80;
this.RateLimitPerHost = TimeSpan.FromMilliseconds(50);
this.OpenConnectionLimitPerHost = 25;
this.ObeyRobotsDotTxt = false;
this.ThrottleMode = Throttle.ByDomainHostName;
this.Request("https://www.Website.com", Parse);
}Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\ShoppingSiteSample\Output\"
Me.MaxHttpConnectionLimit = 80
Me.RateLimitPerHost = TimeSpan.FromMilliseconds(50)
Me.OpenConnectionLimitPerHost = 25
Me.ObeyRobotsDotTxt = False
Me.ThrottleMode = Throttle.ByDomainHostName
Me.Request("https://www.Website.com", Parse)
End SubDrosselungseigenschaften
MaxHttpConnectionLimit
Gesamtzahl der erlaubten offenen HTTP-Anfragen (Threads)RateLimitPerHost
Minimale höfliche Verzögerung (Pause) zwischen Anfragen an eine bestimmte Domain oder IP-AdresseOpenConnectionLimitPerHost
erlaubte Anzahl gleichzeitiger HTTP-Anfragen (Threads) pro Hostname oder IP-AdresseThrottleMode
Macht den WebSraper intelligent, indem er Anfragen nicht nur nach Hostnamen, sondern auch nach IP-Adressen der Hostserver drosselt. Dies ist höflich, falls mehrere gescrapten Domains auf derselben Maschine gehostet werden.
Anhang
Wie erstellt man eine Windows-Formularanwendung?
Verwenden Sie Visual Studio 2013 oder höher.
- Öffnen Sie Visual Studio.
-
Datei -> Neu -> Projekt

- Wählen Sie Visual C# oder VB -> Windows -> Windows Forms Application.
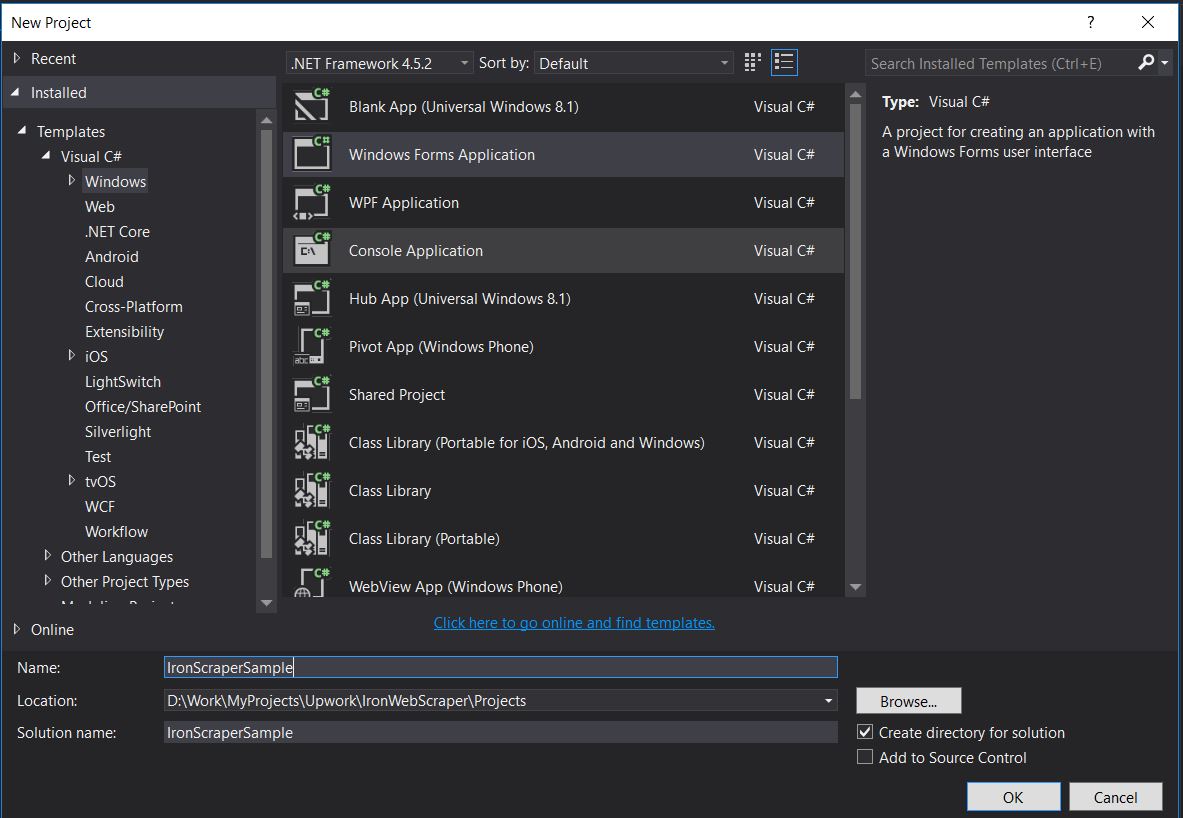
Projektname: IronScraperSample Standort: Wählen Sie einen Standort auf Ihrer Festplatte.
Wie erstellt man eine ASP.NET Webformularanwendung?
-
Öffnen Sie Visual Studio.
-
Datei -> Neu -> Projekt
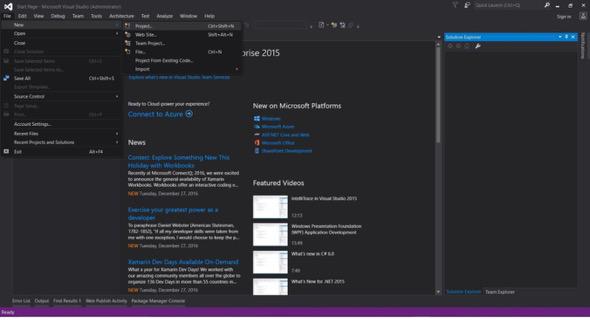
- Wählen Sie Visual C# oder VB -> Web -> ASP.NET Webanwendung (.NET Framework).
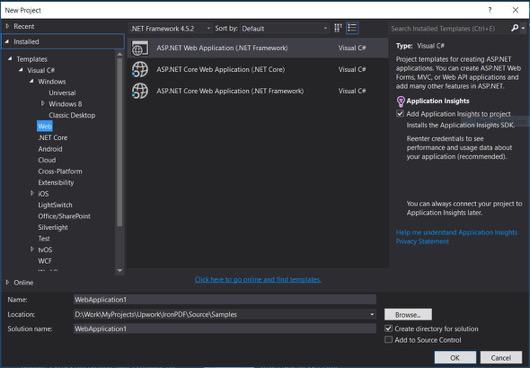
Projektname: IronScraperSample Standort: Wählen Sie einen Standort auf Ihrer Festplatte.
-
Wählen Sie aus Ihren ASP.NET-Vorlagen eine leere Vorlage und aktivieren Sie Web Formulare.
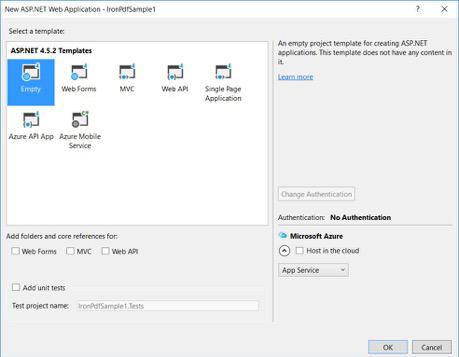
- Ihr grundlegendes ASP.NET-Webformularprojekt wird erstellt.
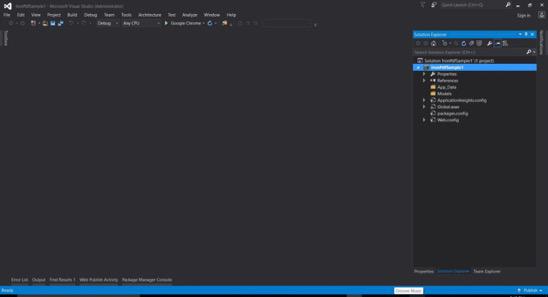
Laden Sie den vollständigen Beispielcode des Tutorials hier herunter.
Häufig gestellte Fragen
Wie kann man Daten von Websites in C# scrapen?
Sie können IronWebScraper verwenden, um Daten von Websites in C# zu scrapern. Beginnen Sie mit der Installation der Bibliothek über NuGet und richten Sie eine einfache Konsolenanwendung ein, um effizient mit der Extraktion von Webdaten zu beginnen.
Was sind die Voraussetzungen für Web-Scraping in C#?
Um Web-Scraping in C# durchzuführen, sollten Sie grundlegende Programmierkenntnisse in C# oder VB.NET haben und Webtechnologien wie HTML, JavaScript und CSS verstehen, sowie mit DOM, XPath und CSS-Selektoren vertraut sein.
Wie kann ich eine Web-Scraping-Bibliothek in einem .NET-Projekt installieren?
Um IronWebScraper in einem .NET-Projekt zu installieren, verwenden Sie die NuGet-Paket-Manager-Konsole mit dem Befehl Install-Package IronWebScraper oder navigieren Sie über die NuGet-Paket-Manager-Oberfläche in Visual Studio.
Wie kann ich die Anforderungsdrosselung in meinem Web-Scraper implementieren?
IronWebScraper ermöglicht Ihnen die Implementierung der Anforderungsdrosselung, um die Häufigkeit der Anfragen an einen Server zu verwalten. Dies kann durch Einstellungen wie MaxHttpConnectionLimit, RateLimitPerHost und OpenConnectionLimitPerHost konfiguriert werden.
Was ist der Zweck der Aktivierung des Web-Caches beim Web-Scraping?
Die Aktivierung des Web-Caches beim Web-Scraping hilft dabei, die Anzahl der an einen Server gesendeten Anfragen zu reduzieren, indem vorherige Antworten gespeichert und wiederverwendet werden. Dies kann in IronWebScraper durch die Verwendung der Methode EnableWebCache eingerichtet werden.
Wie kann die Authentifizierung beim Web-Scraping gehandhabt werden?
Mit IronWebScraper können Sie HttpIdentity verwenden, um die Authentifizierung zu verwalten, wodurch der Zugriff auf Inhalte hinter Login-Formularen oder eingeschränkten Bereichen ermöglicht wird, um das Scraping geschützter Ressourcen zu ermöglichen.
Was ist ein einfaches Beispiel für einen Web-Scraper in C#?
Der 'HelloScraper' ist ein einfaches Beispiel im Tutorial. Er demonstriert das Einrichten eines grundlegenden Web-Scrapers mit IronWebScraper, einschließlich wie man Anfragen initiiert und Antworten parst.
Wie kann ich meinen Web-Scraper erweitern, um komplexe Seitenstrukturen zu handhaben?
Mit IronWebScraper können Sie Ihren Scraper erweitern, um komplexe Seitenstrukturen zu handhaben, indem Sie die Parse-Methoden anpassen, um verschiedene Seitentypen zu verarbeiten, was flexible Datenextraktionsstrategien ermöglicht.
Was sind die Vorteile der Verwendung einer Web-Scraping-Bibliothek?
Die Verwendung einer Web-Scraping-Bibliothek wie IronWebScraper bietet Vorteile wie optimierte Datenextraktion, Domainverwaltung, Anforderungsdrosselung, Caching und Unterstützung für Authentifizierung, was eine effiziente Handhabung von Web-Scraping-Aufgaben ermöglicht.


Scrollst du immer noch?
Sie brauchen schnell einen Beweis? PM > Install-Package IronWebScraper
Führen Sie ein Beispiel aus und beobachten Sie, wie Ihre Zielsite zu strukturierten Daten wird.










