


C# OCR Image to Text Tutorial: Convert Images to Text Without Tesseract
想在 C# 中将图像转换为文本,而无需进行复杂的 Tesseract 配置? 本综合 IronOCR for .NET C# 教程向您展示如何在您的 .NET 应用程序中实现强大的光学字符识别功能,只需几行代码。
快速入门:一行代码从图片中提取文本
这个例子说明了掌握 IronOCR 是多么容易--只需一行 C# 就能将您的图像转化为文本。 它演示了如何初始化 OCR 引擎并立即读取和检索文本,而无需进行复杂的设置。
最小工作流程(5 个步骤)
- 下载 IronOCR——用于图像转文本转换的 C# OCR 库
- 使用
IronTesseract类可以立即从图像中读取文本。 - 应用图像过滤器以提高低质量扫描的 OCR 准确性
- 使用可下载的语言包处理多种语言
- 将结果导出为可搜索的 PDF 或提取文本字符串
如何在 .NET 应用程序中从图像中读取文本?
要在您的 .NET 应用程序中实现 C# OCR 图像转文本功能,您需要一个可靠的 OCR 库。 IronOCR 提供了一种基于 IronOcr.IronTesseract 类的托管解决方案,该方案无需依赖外部组件,即可同时实现最高精度和最快速度。
首先,将 IronOCR 安装到 Visual Studio 项目中。 您可以直接下载 IronOCR DLL 或使用 NuGet 包管理器。
Install-Package IronOcr
为何选择不依赖Tesseract的IronOCR用于C# OCR?
当您需要用 C# 将图像转换为文本时,IronOCR 与传统的 Tesseract 实现相比具有显著优势:
- 可在纯 .NET 环境中立即使用
- 无需安装或配置 Tesseract
- 运行最新的引擎:Tesseract 5(加上 Tesseract 4 和 3)
- 兼容 .NET Framework 4.6.2 及以上版本、.NET Standard 2 及以上版本,以及 .NET Core 2、3、5、6、7、8、9 和 10
- 与原版 Tesseract 相比,提高了准确性和速度
- 支持 Xamarin、Mono、Azure 和 Docker 部署
- 通过 NuGet 包管理复杂的 Tesseract 词典
- 自动处理 PDF、多帧 TIFF 和所有主要图像格式
- 纠正低质量和倾斜的扫描,以获得最佳效果
如何使用IronOCR C#教程进行基本OCR?
这个 Iron Tesseract C# 示例演示了使用 IronOCR 从图像读取文本的最简单方法。 IronOcr.IronTesseract 类用于提取文本并将其作为字符串返回。
// Basic C# OCR image to text conversion using IronOCR
// This example shows how to extract text from images without complex setup
using IronOcr;
using System;
try
{
// Initialize IronTesseract for OCR operations
var ocrEngine = new IronTesseract();
// Path to your image file - supports PNG, JPG, TIFF, BMP, and more
var imagePath = @"img\Screenshot.png";
// Create input and perform OCR to convert image to text
using (var input = new OcrInput(imagePath))
{
// Read text from image and get results
OcrResult result = ocrEngine.Read(input);
// Display extracted text
Console.WriteLine(result.Text);
}
}
catch (OcrException ex)
{
// Handle OCR-specific errors
Console.WriteLine($"OCR Error: {ex.Message}");
}
catch (Exception ex)
{
// Handle general errors
Console.WriteLine($"Error: {ex.Message}");
}// Basic C# OCR image to text conversion using IronOCR
// This example shows how to extract text from images without complex setup
using IronOcr;
using System;
try
{
// Initialize IronTesseract for OCR operations
var ocrEngine = new IronTesseract();
// Path to your image file - supports PNG, JPG, TIFF, BMP, and more
var imagePath = @"img\Screenshot.png";
// Create input and perform OCR to convert image to text
using (var input = new OcrInput(imagePath))
{
// Read text from image and get results
OcrResult result = ocrEngine.Read(input);
// Display extracted text
Console.WriteLine(result.Text);
}
}
catch (OcrException ex)
{
// Handle OCR-specific errors
Console.WriteLine($"OCR Error: {ex.Message}");
}
catch (Exception ex)
{
// Handle general errors
Console.WriteLine($"Error: {ex.Message}");
}' Basic C# OCR image to text conversion using IronOCR
' This example shows how to extract text from images without complex setup
Imports IronOcr
Imports System
Try
' Initialize IronTesseract for OCR operations
Dim ocrEngine = New IronTesseract()
' Path to your image file - supports PNG, JPG, TIFF, BMP, and more
Dim imagePath = "img\Screenshot.png"
' Create input and perform OCR to convert image to text
Using input = New OcrInput(imagePath)
' Read text from image and get results
Dim result As OcrResult = ocrEngine.Read(input)
' Display extracted text
Console.WriteLine(result.Text)
End Using
Catch ex As OcrException
' Handle OCR-specific errors
Console.WriteLine($"OCR Error: {ex.Message}")
Catch ex As Exception
' Handle general errors
Console.WriteLine($"Error: {ex.Message}")
End Try该代码在清晰的图像上实现了 100% 的准确率,提取的文本与图像完全一致:
IronOCR Simple Example
In this simple example we test the accuracy of our C# OCR library to read text from a PNG Image. This is a very basic test, but things will get more complicated as the tutorial continues.
The quick brown fox jumps over the lazy dogIronTesseract 类在内部处理复杂的 OCR 操作。 它能自动扫描对齐、优化分辨率,并使用 IronOCR 从图像中读取文本,准确度达到人类水平。
尽管在幕后进行了复杂的处理,包括图像分析、引擎优化和智能文本识别,但 OCR 流程在保持出色准确性的同时,还能与人类的阅读速度相匹配。
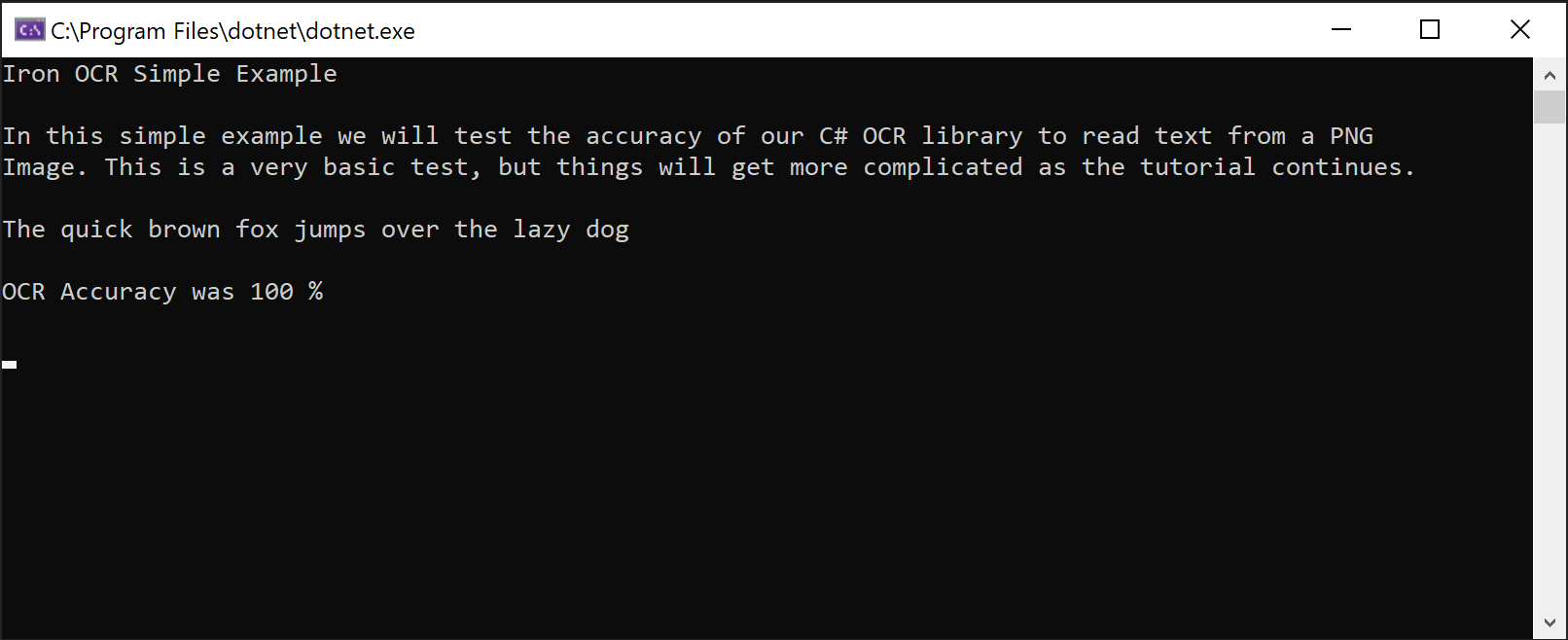 截图展示 IronOCR 从 PNG 图像中精确提取文本的能力
截图展示 IronOCR 从 PNG 图像中精确提取文本的能力
如何在不使用Tesseract配置的情况下实现高级C# OCR?
对于在 C# 中将图像转换为文本时需要最佳性能的生产应用程序,请同时使用 OcrInput 和 IronTesseract 类。 这种方法提供了对 OCR 过程的细粒度控制。
OcrInput 类功能
- 处理多种图像格式:JPEG、TIFF、GIF、BMP、PNG
- 导入完整的 PDF 或特定页面
- 自动增强对比度、分辨率和图像质量
- 纠正旋转、扫描噪声、倾斜和负像
IronTesseract 类功能
- 支持 127 种以上预置语言
- 包括 Tesseract 5、4 和 3 引擎
- 文档类型说明(截图、片段或完整文档)
- 集成条形码读取功能
- 多种输出格式:可搜索的 PDF、HOCR HTML、DOM 对象和字符串
如何开始使用 OcrInput 和 IronTesseract?
下面是本 IronOCR C# 教程的推荐配置,可以很好地适用于大多数文档类型:
using IronOcr;
// Initialize IronTesseract for advanced OCR operations
IronTesseract ocr = new IronTesseract();
// Create input container for processing multiple images
using (OcrInput input = new OcrInput())
{
// Process specific pages from multi-page TIFF files
int[] pageIndices = new int[] { 1, 2 };
// Load TIFF frames - perfect for scanned documents
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
// Execute OCR to read text from image using IronOCR
OcrResult result = ocr.Read(input);
// Output the extracted text
Console.WriteLine(result.Text);
}using IronOcr;
// Initialize IronTesseract for advanced OCR operations
IronTesseract ocr = new IronTesseract();
// Create input container for processing multiple images
using (OcrInput input = new OcrInput())
{
// Process specific pages from multi-page TIFF files
int[] pageIndices = new int[] { 1, 2 };
// Load TIFF frames - perfect for scanned documents
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
// Execute OCR to read text from image using IronOCR
OcrResult result = ocr.Read(input);
// Output the extracted text
Console.WriteLine(result.Text);
}Imports IronOcr
' Initialize IronTesseract for advanced OCR operations
Private ocr As New IronTesseract()
' Create input container for processing multiple images
Using input As New OcrInput()
' Process specific pages from multi-page TIFF files
Dim pageIndices() As Integer = { 1, 2 }
' Load TIFF frames - perfect for scanned documents
input.LoadImageFrames("img\Potter.tiff", pageIndices)
' Execute OCR to read text from image using IronOCR
Dim result As OcrResult = ocr.Read(input)
' Output the extracted text
Console.WriteLine(result.Text)
End Using该配置在中等质量的扫描件上始终保持近乎完美的准确性。 LoadImageFrames方法可高效处理多页文档,非常适合批量处理场景。

展示 IronOCR 多页文本提取功能的 TIFF 文档示例
IronOCR 能够从 TIFF 等扫描文档中的图像和条形码读取文本,这充分展现了它如何简化复杂的 OCR 任务。 该库在处理真实文档方面表现出色,能够无缝处理多页 TIFF 文件和PDF 文本提取。
IronOCR 如何处理低质量扫描?

IronOCR 可以使用图像滤波器准确处理的带有噪点的低分辨率文档
在处理包含失真和数字噪声的不完美扫描时, IronOCR 的性能优于其他 C# OCR 库。 它专为真实场景而设计,而非为完美的测试图像而设计。
// Advanced Iron Tesseract C# example for low-quality images
using IronOcr;
using System;
var ocr = new IronTesseract();
try
{
using (var input = new OcrInput())
{
// Load specific pages from poor-quality TIFF
var pageIndices = new int[] { 0, 1 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageIndices);
// Apply deskew filter to correct rotation and perspective
input.Deskew(); // Critical for improving accuracy on skewed scans
// Perform OCR with enhanced preprocessing
OcrResult result = ocr.Read(input);
// Display results
Console.WriteLine("Recognized Text:");
Console.WriteLine(result.Text);
}
}
catch (Exception ex)
{
Console.WriteLine($"Error during OCR: {ex.Message}");
}// Advanced Iron Tesseract C# example for low-quality images
using IronOcr;
using System;
var ocr = new IronTesseract();
try
{
using (var input = new OcrInput())
{
// Load specific pages from poor-quality TIFF
var pageIndices = new int[] { 0, 1 };
input.LoadImageFrames(@"img\Potter.LowQuality.tiff", pageIndices);
// Apply deskew filter to correct rotation and perspective
input.Deskew(); // Critical for improving accuracy on skewed scans
// Perform OCR with enhanced preprocessing
OcrResult result = ocr.Read(input);
// Display results
Console.WriteLine("Recognized Text:");
Console.WriteLine(result.Text);
}
}
catch (Exception ex)
{
Console.WriteLine($"Error during OCR: {ex.Message}");
}' Advanced Iron Tesseract C# example for low-quality images
Imports IronOcr
Imports System
Private ocr = New IronTesseract()
Try
Using input = New OcrInput()
' Load specific pages from poor-quality TIFF
Dim pageIndices = New Integer() { 0, 1 }
input.LoadImageFrames("img\Potter.LowQuality.tiff", pageIndices)
' Apply deskew filter to correct rotation and perspective
input.Deskew() ' Critical for improving accuracy on skewed scans
' Perform OCR with enhanced preprocessing
Dim result As OcrResult = ocr.Read(input)
' Display results
Console.WriteLine("Recognized Text:")
Console.WriteLine(result.Text)
End Using
Catch ex As Exception
Console.WriteLine($"Error during OCR: {ex.Message}")
End Try使用 Input.Deskew() 后,低质量扫描件的准确率提升至 99.8%,几乎与高质量扫描结果持平。 这就说明了为什么 IronOCR 是 C# OCR 的首选,而不会带来 Tesseract 的复杂性。
图像过滤器可能会略微增加处理时间,但会大大缩短整个 OCR 的持续时间。 找到正确的平衡点取决于您的文档质量。
在大多数情况下,Input.Deskew() 和 Input.DeNoise() 能显著提升 OCR 性能。 了解图像预处理技术的更多信息。
如何优化 OCR 性能和速度?
在 C# 中将图像转换为文本时,影响 OCR 速度的最主要因素是输入质量。 较高的 DPI(约 200 dpi)和最小的噪点可以产生最快、最准确的结果。
虽然 IronOCR 擅长纠正不完善的文档,但这种增强功能需要额外的处理时间。
选择压缩痕迹最小的图像格式。 由于数字噪声较低,TIFF 和 PNG 通常比 JPEG 能产生更快的效果。
哪些图像过滤器可提高 OCR 速度?
以下过滤器可显著提高 C# OCR 图像到文本工作流程的性能:
OcrInput.Rotate(double degrees):将图像顺时针旋转(负值表示逆时针旋转)OcrInput.Binarize():转换为黑白模式,在低对比度场景下提升性能OcrInput.ToGrayScale():转换为灰度以提升潜在运行速度OcrInput.Contrast():自动调整对比度以提高准确性OcrInput.DeNoise():在预期存在噪声时去除数字伪影OcrInput.Invert():将文字颜色反转为黑底白字OcrInput.Dilate(): 扩展文本边界OcrInput.Erode(): 缩减文本边界OcrInput.Deskew():修正对齐问题——对于排版歪斜的文档至关重要OcrInput.DeepCleanBackgroundNoise():强力降噪OcrInput.EnhanceResolution:提升低分辨率图像质量OcrInput.DetectPageOrientation():检测并纠正页面旋转。 传递OrientationDetectionMode参数以控制准确性与速度的权衡:Detailed或ExtremeDetailed(新增于 v2025.8.6)
Scale() 和 EnhanceResolution() 因 v2025.12.3 版本中的已知问题,与 SaveAsSearchablePdf() 不兼容。所有其他过滤器均可正常生成可搜索的 PDF 输出。
如何配置 IronOCR 以获得最高速度?
在处理高质量扫描时,使用这些设置可优化速度:
using IronOcr;
// Configure for speed - ideal for clean documents
IronTesseract ocr = new IronTesseract();
// Exclude problematic characters to speed up recognition
ocr.Configuration.BlackListCharacters = "~`$#^*_{[]}|\\";
// Use automatic page segmentation
ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
// Select fast English language pack
ocr.Language = OcrLanguage.EnglishFast;
using (OcrInput input = new OcrInput())
{
// Load specific pages from document
int[] pageIndices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
// Read with optimized settings
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
}using IronOcr;
// Configure for speed - ideal for clean documents
IronTesseract ocr = new IronTesseract();
// Exclude problematic characters to speed up recognition
ocr.Configuration.BlackListCharacters = "~`$#^*_{[]}|\\";
// Use automatic page segmentation
ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
// Select fast English language pack
ocr.Language = OcrLanguage.EnglishFast;
using (OcrInput input = new OcrInput())
{
// Load specific pages from document
int[] pageIndices = new int[] { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
// Read with optimized settings
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
}Imports IronOcr
' Configure for speed - ideal for clean documents
Private ocr As New IronTesseract()
' Exclude problematic characters to speed up recognition
ocr.Configuration.BlackListCharacters = "~`$#^*_{[]}|\"
' Use automatic page segmentation
ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
' Select fast English language pack
ocr.Language = OcrLanguage.EnglishFast
Using input As New OcrInput()
' Load specific pages from document
Dim pageIndices() As Integer = { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageIndices)
' Read with optimized settings
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End Using与默认设置相比,该优化设置在保持99.8%准确性的同时,实现了35%的速度提升。
如何使用C# OCR读取图像的特定区域?
下面的 Iron Tesseract C# 示例展示了如何使用 System.Drawing.Rectangle 针对特定区域进行定位。 这种技术对于处理文本出现在可预测位置的标准化表单非常有用。
IronOCR 能否处理裁剪区域以获得更快的结果?
使用基于像素的坐标,您可以将 OCR 限制在特定区域,从而大幅提高速度并防止提取不必要的文本:
using IronOcr;
using IronSoftware.Drawing;
// Initialize OCR engine for targeted region processing
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Define exact region for OCR - coordinates in pixels
var contentArea = new System.Drawing.Rectangle(
x: 215,
y: 1250,
width: 1335,
height: 280
);
// Load image with specific area - perfect for forms and invoices
input.LoadImage("img/ComSci.png", contentArea);
// Process only the defined region
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
}using IronOcr;
using IronSoftware.Drawing;
// Initialize OCR engine for targeted region processing
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Define exact region for OCR - coordinates in pixels
var contentArea = new System.Drawing.Rectangle(
x: 215,
y: 1250,
width: 1335,
height: 280
);
// Load image with specific area - perfect for forms and invoices
input.LoadImage("img/ComSci.png", contentArea);
// Process only the defined region
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
}Imports IronOcr
Imports IronSoftware.Drawing
' Initialize OCR engine for targeted region processing
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Define exact region for OCR - coordinates in pixels
Dim contentArea As New System.Drawing.Rectangle(215, 1250, 1335, 280)
' Load image with specific area - perfect for forms and invoices
input.LoadImage("img/ComSci.png", contentArea)
' Process only the defined region
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
End Using这种有针对性的方法在只提取相关文本的同时将速度提高了 41%。 它非常适合结构化文档,如发票、支票和表单。 同样的裁剪技术可与PDF OCR 操作无缝配合。
 演示使用 IronOCR 的矩形选择功能进行基于区域的精确文本提取的文档
演示使用 IronOCR 的矩形选择功能进行基于区域的精确文本提取的文档
IronOCR 支持多少种语言?
IronOCR 通过便捷的语言包支持 127 种国际语言。 从我们的网站或通过 NuGet 软件包管理器以 DLL 形式下载。
通过 NuGet 界面(搜索 "IronOcr.Languages")安装语言包,或访问 完整语言包列表。
支持的语言包括阿拉伯语、中文(简体/繁体)、日语、韩语、印地语、俄语、德语、法语、西班牙语和其他 115 多种语言,每种语言都经过优化,可实现准确的文本识别。
如何在多种语言中实现 OCR?
此 IronOCR C# 教程示例演示了阿拉伯语文本识别:
Install-Package IronOcr.Languages.Arabic

IronOCR 从 GIF 图像中准确提取阿拉伯语文本
// Install-Package IronOcr.Languages.Arabic
using IronOcr;
// Configure for Arabic language OCR
var ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using (var input = new OcrInput())
{
// Load Arabic text image
input.LoadImage("img/arabic.gif");
// IronOCR handles low-quality Arabic text that standard Tesseract cannot
var result = ocr.Read(input);
// Save to file (console may not display Arabic correctly)
result.SaveAsTextFile("arabic.txt");
}// Install-Package IronOcr.Languages.Arabic
using IronOcr;
// Configure for Arabic language OCR
var ocr = new IronTesseract();
ocr.Language = OcrLanguage.Arabic;
using (var input = new OcrInput())
{
// Load Arabic text image
input.LoadImage("img/arabic.gif");
// IronOCR handles low-quality Arabic text that standard Tesseract cannot
var result = ocr.Read(input);
// Save to file (console may not display Arabic correctly)
result.SaveAsTextFile("arabic.txt");
}Imports IronOcr
' Configure for Arabic language OCR
Dim ocr As New IronTesseract()
ocr.Language = OcrLanguage.Arabic
Using input As New OcrInput()
' Load Arabic text image
input.LoadImage("img/arabic.gif")
' IronOCR handles low-quality Arabic text that standard Tesseract cannot
Dim result = ocr.Read(input)
' Save to file (console may not display Arabic correctly)
result.SaveAsTextFile("arabic.txt")
End UsingIronOCR 可以处理多种语言的文档吗?
当文档包含混合语言时,配置 IronOCR 以支持多语言:
Install-Package IronOcr.Languages.ChineseSimplified
// Multi-language OCR configuration
using IronOcr;
var ocr = new IronTesseract();
// Set primary language
ocr.Language = OcrLanguage.ChineseSimplified;
// Add secondary languages as needed
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Custom .traineddata files can be added for specialized recognition
// ocr.AddSecondaryLanguage("path/to/custom.traineddata");
using (var input = new OcrInput())
{
// Process multi-language document
input.LoadImage("img/MultiLanguage.jpeg");
var result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");
}// Multi-language OCR configuration
using IronOcr;
var ocr = new IronTesseract();
// Set primary language
ocr.Language = OcrLanguage.ChineseSimplified;
// Add secondary languages as needed
ocr.AddSecondaryLanguage(OcrLanguage.English);
// Custom .traineddata files can be added for specialized recognition
// ocr.AddSecondaryLanguage("path/to/custom.traineddata");
using (var input = new OcrInput())
{
// Process multi-language document
input.LoadImage("img/MultiLanguage.jpeg");
var result = ocr.Read(input);
result.SaveAsTextFile("MultiLanguage.txt");
}Imports IronOcr
' Multi-language OCR configuration
Dim ocr As New IronTesseract()
' Set primary language
ocr.Language = OcrLanguage.ChineseSimplified
' Add secondary languages as needed
ocr.AddSecondaryLanguage(OcrLanguage.English)
' Custom .traineddata files can be added for specialized recognition
' ocr.AddSecondaryLanguage("path/to/custom.traineddata")
Using input As New OcrInput()
' Process multi-language document
input.LoadImage("img/MultiLanguage.jpeg")
Dim result = ocr.Read(input)
result.SaveAsTextFile("MultiLanguage.txt")
End Using如何使用C# OCR处理多页文档?
IronOCR 可将多页文档或图片无缝合并为单个 OcrResult。 该功能可实现强大的功能,如创建可搜索的 PDF 和从整个文档集中提取文本。
在单个 OCR 操作中混合和匹配各种来源(图像、TIFF 框架和 PDF 页面):
// Multi-source document processing
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Add various image formats
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
// Process specific frames from multi-frame images
int[] frameNumbers = { 1, 2 };
input.LoadImageFrames("image3.gif", frameNumbers);
// Process all sources together
OcrResult result = ocr.Read(input);
// Verify page count
Console.WriteLine($"{result.Pages.Count} Pages processed.");
}// Multi-source document processing
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Add various image formats
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
// Process specific frames from multi-frame images
int[] frameNumbers = { 1, 2 };
input.LoadImageFrames("image3.gif", frameNumbers);
// Process all sources together
OcrResult result = ocr.Read(input);
// Verify page count
Console.WriteLine($"{result.Pages.Count} Pages processed.");
}Imports IronOcr
' Multi-source document processing
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Add various image formats
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
' Process specific frames from multi-frame images
Dim frameNumbers As Integer() = {1, 2}
input.LoadImageFrames("image3.gif", frameNumbers)
' Process all sources together
Dim result As OcrResult = ocr.Read(input)
' Verify page count
Console.WriteLine($"{result.Pages.Count} Pages processed.")
End Using高效处理 TIFF 文件的所有页面:
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Define pages to process (0-based indexing)
int[] pageIndices = new int[] { 0, 1 };
// Load specific TIFF frames
input.LoadImageFrames("MultiFrame.Tiff", pageIndices);
// Extract text from all frames
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Count} Pages processed");
}using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Define pages to process (0-based indexing)
int[] pageIndices = new int[] { 0, 1 };
// Load specific TIFF frames
input.LoadImageFrames("MultiFrame.Tiff", pageIndices);
// Extract text from all frames
OcrResult result = ocr.Read(input);
Console.WriteLine(result.Text);
Console.WriteLine($"{result.Pages.Count} Pages processed");
}Imports IronOcr
Private ocr As New IronTesseract()
Using input As New OcrInput()
' Define pages to process (0-based indexing)
Dim pageIndices() As Integer = { 0, 1 }
' Load specific TIFF frames
input.LoadImageFrames("MultiFrame.Tiff", pageIndices)
' Extract text from all frames
Dim result As OcrResult = ocr.Read(input)
Console.WriteLine(result.Text)
Console.WriteLine($"{result.Pages.Count} Pages processed")
End Using将 TIFF 或 PDF 转换为可搜索格式:
using System;
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Set document metadata
input.Title = "Quarterly Report";
// Combine multiple sources
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
// Add specific frames from animated images
int[] gifFrames = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", gifFrames);
// Create searchable PDF
OcrResult result = ocr.Read(input);
// Pass true to apply any active OcrInput filters to the searchable PDF output (added v2025.5.11)
result.SaveAsSearchablePdf("searchable.pdf", true);
}using System;
using IronOcr;
IronTesseract ocr = new IronTesseract();
using (OcrInput input = new OcrInput())
{
// Set document metadata
input.Title = "Quarterly Report";
// Combine multiple sources
input.LoadImage("image1.jpeg");
input.LoadImage("image2.png");
// Add specific frames from animated images
int[] gifFrames = new int[] { 1, 2 };
input.LoadImageFrames("image3.gif", gifFrames);
// Create searchable PDF
OcrResult result = ocr.Read(input);
// Pass true to apply any active OcrInput filters to the searchable PDF output (added v2025.5.11)
result.SaveAsSearchablePdf("searchable.pdf", true);
}Imports System
Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Set document metadata
input.Title = "Quarterly Report"
' Combine multiple sources
input.LoadImage("image1.jpeg")
input.LoadImage("image2.png")
' Add specific frames from animated images
Dim gifFrames As Integer() = {1, 2}
input.LoadImageFrames("image3.gif", gifFrames)
' Create searchable PDF
Dim result As OcrResult = ocr.Read(input)
' Pass true to apply any active OcrInput filters to the searchable PDF output (added v2025.5.11)
result.SaveAsSearchablePdf("searchable.pdf", True)
End Using将现有 PDF 转换为可搜索版本:
using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set PDF metadata
input.Title = "Annual Report 2024";
// Process existing PDF
input.LoadPdf("example.pdf", "password");
// Generate searchable version
var result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set PDF metadata
input.Title = "Annual Report 2024";
// Process existing PDF
input.LoadPdf("example.pdf", "password");
// Generate searchable version
var result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}Imports IronOcr
Private ocr = New IronTesseract()
Using input = New OcrInput()
' Set PDF metadata
input.Title = "Annual Report 2024"
' Process existing PDF
input.LoadPdf("example.pdf", "password")
' Generate searchable version
Dim result = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")
End Using对 TIFF 转换应用同样的技巧:
using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Configure document properties
input.Title = "Scanned Archive Document";
// Select pages to process
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Create searchable PDF from TIFF
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Configure document properties
input.Title = "Scanned Archive Document";
// Select pages to process
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Create searchable PDF from TIFF
OcrResult result = ocr.Read(input);
result.SaveAsSearchablePdf("searchable.pdf");
}Imports IronOcr
Private ocr = New IronTesseract()
Using input = New OcrInput()
' Configure document properties
input.Title = "Scanned Archive Document"
' Select pages to process
Dim pageIndices = New Integer() { 1, 2 }
input.LoadImageFrames("example.tiff", pageIndices)
' Create searchable PDF from TIFF
Dim result As OcrResult = ocr.Read(input)
result.SaveAsSearchablePdf("searchable.pdf")
End Using如何将 OCR 结果导出为 HOCR HTML?
IronOCR 支持 HOCR HTML 导出,可实现结构化的 PDF 至 HTML 和 TIFF 至 HTML 转换,同时保留布局信息:
using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set HTML title
input.Title = "Document Archive";
// Process multiple document types
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf", "password");
// Add TIFF pages
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Export as HOCR with position data
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");
}using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
// Set HTML title
input.Title = "Document Archive";
// Process multiple document types
input.LoadImage("image2.jpeg");
input.LoadPdf("example.pdf", "password");
// Add TIFF pages
var pageIndices = new int[] { 1, 2 };
input.LoadImageFrames("example.tiff", pageIndices);
// Export as HOCR with position data
OcrResult result = ocr.Read(input);
result.SaveAsHocrFile("hocr.html");
}Imports IronOcr
Dim ocr As New IronTesseract()
Using input As New OcrInput()
' Set HTML title
input.Title = "Document Archive"
' Process multiple document types
input.LoadImage("image2.jpeg")
input.LoadPdf("example.pdf", "password")
' Add TIFF pages
Dim pageIndices As Integer() = {1, 2}
input.LoadImageFrames("example.tiff", pageIndices)
' Export as HOCR with position data
Dim result As OcrResult = ocr.Read(input)
result.SaveAsHocrFile("hocr.html")
End UsingIronOCR 能否在读取文本的同时读取条形码?
IronOCR 将文本识别与条形码阅读功能独特地结合在一起,无需单独的库:
// Enable combined text and barcode recognition
using IronOcr;
var ocr = new IronTesseract();
// Enable barcode detection
ocr.Configuration.ReadBarCodes = true;
using (var input = new OcrInput())
{
// Load image containing both text and barcodes
input.LoadImage("img/Barcode.png");
// Process both text and barcodes
var result = ocr.Read(input);
// Extract barcode data
foreach (var barcode in result.Barcodes)
{
Console.WriteLine($"Barcode Value: {barcode.Value}");
Console.WriteLine($"Type: {barcode.Type}, Location: {barcode.Location}");
}
}// Enable combined text and barcode recognition
using IronOcr;
var ocr = new IronTesseract();
// Enable barcode detection
ocr.Configuration.ReadBarCodes = true;
using (var input = new OcrInput())
{
// Load image containing both text and barcodes
input.LoadImage("img/Barcode.png");
// Process both text and barcodes
var result = ocr.Read(input);
// Extract barcode data
foreach (var barcode in result.Barcodes)
{
Console.WriteLine($"Barcode Value: {barcode.Value}");
Console.WriteLine($"Type: {barcode.Type}, Location: {barcode.Location}");
}
}Imports IronOcr
Dim ocr As New IronTesseract()
' Enable barcode detection
ocr.Configuration.ReadBarCodes = True
Using input As New OcrInput()
' Load image containing both text and barcodes
input.LoadImage("img/Barcode.png")
' Process both text and barcodes
Dim result = ocr.Read(input)
' Extract barcode data
For Each barcode In result.Barcodes
Console.WriteLine($"Barcode Value: {barcode.Value}")
Console.WriteLine($"Type: {barcode.Type}, Location: {barcode.Location}")
Next
End Using如何访问详细的 OCR 结果和元数据?
IronOCR 结果对象提供了全面的数据,高级开发人员可以利用这些数据开发复杂的应用程序。
每个 OcrResult 包含分层集合:页面、段落、行、WORD和字符。 所有元素都包括详细的元数据,如位置、字体信息和置信度分数。
单个元素(段落、单词、Barcode)可以导出为图像或位图,以便进一步处理:
using System;
using IronOcr;
using IronSoftware.Drawing;
// Configure with barcode support
IronTesseract ocr = new IronTesseract
{
Configuration = { ReadBarCodes = true }
};
using OcrInput input = new OcrInput();
// Process multi-page document
int[] pageIndices = { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
OcrResult result = ocr.Read(input);
// Navigate the complete results hierarchy
foreach (var page in result.Pages)
{
// Page-level data
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// Extract page elements
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap();
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Paragraph properties
int paragraphNumber = paragraph.ParagraphNumber;
string paragraphText = paragraph.Text;
double paragraphConfidence = paragraph.Confidence;
var textDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Line details including baseline information
string lineText = line.Text;
double lineConfidence = line.Confidence;
double baselineAngle = line.BaselineAngle;
double baselineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Word-level data
string wordText = word.Text;
double wordConfidence = word.Confidence;
// Font information (when available)
if (word.Font != null)
{
string fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isItalic = word.Font.IsItalic;
}
foreach (var character in word.Characters)
{
// Character-level analysis
string charText = character.Text;
double charConfidence = character.Confidence;
// Alternative character choices for spell-checking
OcrResult.Choice[] alternatives = character.Choices;
}
}
}
}
}using System;
using IronOcr;
using IronSoftware.Drawing;
// Configure with barcode support
IronTesseract ocr = new IronTesseract
{
Configuration = { ReadBarCodes = true }
};
using OcrInput input = new OcrInput();
// Process multi-page document
int[] pageIndices = { 1, 2 };
input.LoadImageFrames(@"img\Potter.tiff", pageIndices);
OcrResult result = ocr.Read(input);
// Navigate the complete results hierarchy
foreach (var page in result.Pages)
{
// Page-level data
int pageNumber = page.PageNumber;
string pageText = page.Text;
int pageWordCount = page.WordCount;
// Extract page elements
OcrResult.Barcode[] barcodes = page.Barcodes;
AnyBitmap pageImage = page.ToBitmap();
double pageWidth = page.Width;
double pageHeight = page.Height;
foreach (var paragraph in page.Paragraphs)
{
// Paragraph properties
int paragraphNumber = paragraph.ParagraphNumber;
string paragraphText = paragraph.Text;
double paragraphConfidence = paragraph.Confidence;
var textDirection = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Line details including baseline information
string lineText = line.Text;
double lineConfidence = line.Confidence;
double baselineAngle = line.BaselineAngle;
double baselineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Word-level data
string wordText = word.Text;
double wordConfidence = word.Confidence;
// Font information (when available)
if (word.Font != null)
{
string fontName = word.Font.FontName;
double fontSize = word.Font.FontSize;
bool isBold = word.Font.IsBold;
bool isItalic = word.Font.IsItalic;
}
foreach (var character in word.Characters)
{
// Character-level analysis
string charText = character.Text;
double charConfidence = character.Confidence;
// Alternative character choices for spell-checking
OcrResult.Choice[] alternatives = character.Choices;
}
}
}
}
}Imports System
Imports IronOcr
Imports IronSoftware.Drawing
' Configure with barcode support
Private ocr As New IronTesseract With {
.Configuration = { ReadBarCodes = True }
}
Private OcrInput As using
' Process multi-page document
Private pageIndices() As Integer = { 1, 2 }
input.LoadImageFrames("img\Potter.tiff", pageIndices)
Dim result As OcrResult = ocr.Read(input)
' Navigate the complete results hierarchy
For Each page In result.Pages
' Page-level data
Dim pageNumber As Integer = page.PageNumber
Dim pageText As String = page.Text
Dim pageWordCount As Integer = page.WordCount
' Extract page elements
Dim barcodes() As OcrResult.Barcode = page.Barcodes
Dim pageImage As AnyBitmap = page.ToBitmap()
Dim pageWidth As Double = page.Width
Dim pageHeight As Double = page.Height
For Each paragraph In page.Paragraphs
' Paragraph properties
Dim paragraphNumber As Integer = paragraph.ParagraphNumber
Dim paragraphText As String = paragraph.Text
Dim paragraphConfidence As Double = paragraph.Confidence
Dim textDirection = paragraph.TextDirection
For Each line In paragraph.Lines
' Line details including baseline information
Dim lineText As String = line.Text
Dim lineConfidence As Double = line.Confidence
Dim baselineAngle As Double = line.BaselineAngle
Dim baselineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Word-level data
Dim wordText As String = word.Text
Dim wordConfidence As Double = word.Confidence
' Font information (when available)
If word.Font IsNot Nothing Then
Dim fontName As String = word.Font.FontName
Dim fontSize As Double = word.Font.FontSize
Dim isBold As Boolean = word.Font.IsBold
Dim isItalic As Boolean = word.Font.IsItalic
End If
For Each character In word.Characters
' Character-level analysis
Dim charText As String = character.Text
Dim charConfidence As Double = character.Confidence
' Alternative character choices for spell-checking
Dim alternatives() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next page摘要
IronOCR 为 C# 开发人员提供最先进的 Tesseract API 实现,可在 Windows、Linux 和 Mac 平台上无缝运行。 其使用 IronOCR 从图像中准确读取文本的能力--即使是不完美的文档--使其有别于基本的 OCR 解决方案。
该库的独特功能包括集成条形码读取功能,以及将结果导出为可搜索 PDF 或 HOCR HTML 的功能,这些功能是标准 Tesseract 实现所不具备的。
向前迈进
要继续掌握 IronOCR:
- 了解我们的全面入门指南。
- 浏览实用 C# 代码示例。
- 参考详细的 API 文档。
源代码下载
准备好在您的应用程序中实现 C# OCR 图像到文本的转换了吗? 下载 IronOCR 并立即开始免费试用。
常见问题解答
如何在不使用 Tesseract 的情况下,将图像转换为 C# 中的文本?
您可以使用 IronOCR 在 C# 中将图像转换为文本,而无需 Tesseract。IronOCR 通过内置方法直接处理图像到文本的转换,简化了该过程。
如何提高低质量图像的 OCR 准确性?
IronOCR 提供如 Input.Deskew() 和 Input.DeNoise() 的图像滤镜,可以通过校正偏斜和减少噪声来增强低质量图像,从而显著提高 OCR 准确性。
在 C# 中使用 OCR 从多页文档中提取文本的步骤是什么?
要从多页文档中提取文本,IronOCR 允许您使用 LoadPdf() 方法来加载和处理每一页的 PDF 文件或处理 TIFF 文件,有效地将每一页转换为文本。
是否可以同时从图像中读取条码和文本?
是的,IronOCR 可以从一个图像中同时读取文本和条码。您可以启用条码读取 ocr.Configuration.ReadBarCodes = true,这使得能够提取文本和条码数据。
如何设置 OCR 以处理多语言文档?
IronOCR 支持超过 125 种语言,您可以使用 ocr.Language 设置主要语言,并通过 ocr.AddSecondaryLanguage() 添加其他语言,以实现多语言文档处理。
有哪些方法可以以不同格式导出 OCR 结果?
IronOCR 提供几种导出 OCR 结果的方法,例如用于 PDF 的 SaveAsSearchablePdf(),用于纯文本的 SaveAsTextFile(),以及用于 HOCR HTML 格式的 SaveAsHocrFile()。
如何优化大图像文件的 OCR 处理速度?
要优化 OCR 处理速度,请使用 IronOCR 的 OcrLanguage.EnglishFast 以加快语言识别,并定义特定的 OCR 区域 System.Drawing.Rectangle 以减少处理时间。
如何处理受保护 PDF 文件的 OCR 处理程序?
在处理受保护的 PDF 时,使用正确密码与 LoadPdf() 方法配合使用。IronOCR 通过自动将页面转换为图像来处理基于图像的 PDF,以进行 OCR 处理。
如果 OCR 结果不准确我该怎么办?
如果 OCR 结果不准确,请考虑使用 IronOCR 的图像增强功能,如 Input.Deskew() 和 Input.DeNoise(),并确保安装了正确的语言包。
我可以自定义 OCR 过程以排除某些字符吗?
可以,IronOCR 允许通过使用 BlackListCharacters 属性自定义 OCR 过程,以排除特定字符,从而通过专注于相关文本提高准确率和处理速度。



还在滚动吗?
想快速获得证据? PM > Install-Package IronOcr
运行示例 观看您的图像变成可搜索文本。










