

IronOCRを使用してAzure OCRサービスを構築する方法
Iron Softwareは、AzureのOCR統合から相互運用性の問題を取り除くOCR(光学式文字認識)ライブラリを作成しました。 Azure上でOCRライブラリを扱うことは、常に開発者にとって少しの苦痛です。 この問題や他の多くのOCRの悩みを解決するソリューションはIronOCRです。
マイクロソフトAzure向けIronOCR機能
IronOCRは、Microsoft Azure上でOCRサービスを構築するための次の機能を含んでいます:
- PDFを検索可能なドキュメントに変換し、テキストを簡単に抽出できるようにします。
- 画像からテキストを抽出して、画像を検索可能なドキュメントに変換します
- バーコードとQRコードを読み取ります
- 優れた精度
- ローカルで実行され、SaaS(Software as a Service)を必要としません。SaaSは、Microsoft Azure などのクラウドプロバイダーが各種アプリケーションをホストし、これらのアプリケーションを最終ユーザーに提供するソフトウェア配信モデルです。
-
超高速スピード
最高のOCRエンジンであるIron SoftwareのIronOCRが、どのようにして開発者が任意の入力ドキュメントからテキストを抽出しやすくするのかを見てみましょう。
さあ、Azure OCRサービスを始めましょう。
サンプルを開始するためには、まずIronOCRをインストールする必要があります。
-
C#を使用して新しいコンソールアプリケーションを作成する
-
NuGetを介してIronOCRをインストールするには、以下のいずれかの方法を使用します:Install-Package IronOcrと入力するか、NuGetパッケージの管理を選択してIronOCRを検索します。 以下に示します
- Program.csファイルを次のように編集してください:
- PDFファイルの内容を読み取り抽出するために、IronOCRの名前空間をインポートしてそのOCR機能を利用します。
- 画像からテキストを抽出するために、新しいIronTesseractオブジェクトを作成します。
using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string [] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); //Read PNG image File
Console.WriteLine(result.Text); //Write Output to PDF document
Console.ReadLine();
}
}
}
}using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string [] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); //Read PNG image File
Console.WriteLine(result.Text); //Write Output to PDF document
Console.ReadLine();
}
}
}
}Imports IronOcr
Imports System
Namespace IronOCR_Ex
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim ocr = New IronTesseract()
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim result = ocr.Read(Input) 'Read PNG image File
Console.WriteLine(result.Text) 'Write Output to PDF document
Console.ReadLine()
End Using
End Sub
End Class
End Namespace-
次に、Purgatory.PNGという名前の画像を開きます。 この画像はダンテによる「神曲」の一部です。私の好きな本の一つです。 画像は次の画像のように見えます。

図2 - IronOCRの光学式文字認識機能で抽出されるテキスト
-
上記の入力画像テキストから抽出された後の出力。
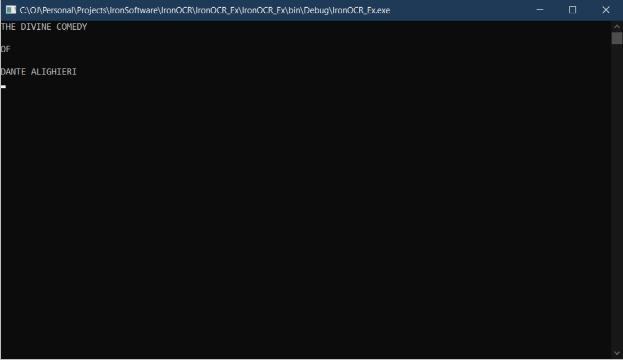
図3 - 抽出されたテキスト
-
PDFドキュメントでも同じことをしましょう。 PDFドキュメントには、Figureと同じテキストを抽出することが含まれています。
唯一の違いは、画像の代わりにPDFドキュメントになることです。 次のコードを入力してください:
var Ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; //Give title to input document
//Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var Result = Ocr.Read(input); //Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
} var Ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; //Give title to input document
//Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var Result = Ocr.Read(input); //Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
}Dim Ocr = New IronTesseract()
Using input = New OcrInput()
input.Title = "Divine Comedy - Purgatory" 'Give title to input document
'Supply optional password and name of document
input.AddPdf("..\Documents\Purgatorio.pdf", "dante")
Dim Result = Ocr.Read(input) 'Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf")
End Usingほぼ前のコードと同じで、画像からテキストを抽出します。
こちらでは、OcrInput メソッドを使用して、現在のPDFドキュメント(この場合は Purgatorio.pdf)を読み込みます。 PDFファイルにタイトルやパスワードなどのメタデータが含まれている場合、それを入力することもできます。
結果は、テキストの検索が可能なPDFドキュメントとして保存されます。
注意: PDFファイルが大きすぎる場合、例外がスローされることがあります。
-
Windowsアプリケーションについてはこれで十分です。 Microsoft AzureでOCRを使用する方法を見ていきましょう。
IronOCRの魅力は、マイクロサービスアーキテクチャにおけるAzure FunctionとしてMicrosoft Azureと非常にうまく連携することです。 以下は、IronOCRと連携するMicrosoft Azure関数の非常に簡単な例です。このMicrosoft Azure関数は画像からテキストを抽出します。
public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query ["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query ["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} Public Module OCRFunction
Public hcClient As New HttpClient()
<FunctionName("IronOCRFunction_EX")>
Public Async Function Run(<HttpTrigger> ByVal hrRequest As HttpRequest, ByVal ecContext As ExecutionContext) As Task(Of IActionResult)
Dim URI = hrRequest.Query ("image")
Dim saStream = Await hcClient.GetStreamAsync(URI)
Dim ocr = New IronTesseract()
Using inputOCR = New OcrInput(saStream)
Dim outputOCR = ocr.Read(inputOCR)
Return New OkObjectResult(outputOCR.Text)
End Using
End Function
End Moduleこれにより、受け取った画像が直接OCRエンジンに送られ、抽出されたテキストとして出力されます。
Microsoft Azureの概要について簡単に振り返ります。
マイクロソフトによると:「Microsoft Azure マイクロサービスは、各コア機能やサービスが独立して構築およびデプロイされるアーキテクチャルなアプローチです。」 マイクロサービスアーキテクチャは分散型で疎結合であるため、1つのコンポーネントが故障してもアプリ全体が壊れることはありません。独立したコンポーネントが連携し、明確に定義されたAPI契約に基づいて通信します。 急速に変化するビジネスニーズに対応し、新機能を迅速に市場に投入するためのマイクロサービスアプリケーションを構築します。
以下は、.NETまたはMicrosoft Azureを使用したIronOCRのいくつかの追加機能です:
ほぼすべてのファイル、画像、またはPDFに対してOCRを実行する能力。
- OCR入力処理の超高速スピード
- 優れた精度
- バーコードおよびQRコードを読み取ります
- ローカルで実行され、SaaSを必要としません
- PDFや画像を検索可能なドキュメントに変換できます
- マイクロソフト コグニティブ サービスのAzure OCRに代わる優れた代替品
OCR性能を向上させるための画像フィルター
- OcrInput.Rotate - 画像を時計回りに数度回転させます。反時計回りの場合は負の数を使用してください。
- OcrInput.Binarize() - この画像フィルターは、すべてのピクセルを中間色なしで黒または白に変換します。 これはOCRのパフォーマンスを向上させます。
- OcrInput.ToGrayScale() - この画像フィルターは、すべてのピクセルをグレースケールの階調に変換します。 これはOCR速度を向上させます。
- OcrInput.Contrast() - コントラストを自動的に高めます。 このフィルターは、コントラストが低いスキャンにおいてOCRの速度と精度を向上させます。
- OcrInput.DeNoise() - デジタルノイズを除去します。このフィルターは、入力ドキュメントにノイズが予想される場合にのみ使用してください。
- OcrInput.Invert() - すべての色を反転させます。
- OcrInput.Dilate() - 拡張は、画像内のオブジェクトの境界にピクセルを追加します。
- OcrInput.Erode() - 侵食は、オブジェクトの境界のピクセルを取り除きます。
- OcrInput.Deskew() - 画像を回転させて正しい向きにし、直交させます。 これは、OCRに非常に役立ちます。なぜなら、Tesseractの傾きの許容範囲は5度程度と低いためです。
- OcrInput.DeepCleanBackgroundNoise() - 重度の背景ノイズ除去。
- OcrInput.EnhanceResolution - 低品質の画像の解像度を向上させます。
速度性能
以下に例を示します:
var Ocr = new IronTesseract();
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][
\\";
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
Ocr.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
} var Ocr = new IronTesseract();
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][
\\";
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
Ocr.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}Dim Ocr = New IronTesseract()
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][ \\"
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly
Ocr.Language = OcrLanguage.EnglishFast
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim Result = Ocr.Read(Input)
Console.WriteLine(Result.Text)
End Using価格およびライセンスオプション
基本的に、有料のライセンスタイアは3つあり、すべて一度の購入で生涯ライセンスの原則に基づいています。
そして、はい、これらは開発目的で無料です。
詳細情報
- 追加のリソースは次のリンクで見つけることができます:Resources
- APIリファレンスはこちらで見つけることができます:APIリファレンス
- IronOCR製品のサポートはこちらで見つけることができます:サポート
- Iron Softwareに連絡する: お問い合わせ情報
Azureおよびその他のシステムでOCRを実行する.NETアプリケーション向けIronOCRの機能
-
IronOCRは127の国際言語をサポートしています。 それぞれの言語は、Fast、Standard、Bestの品質で利用可能です。 利用可能な言語パックには以下が含まれます:
-
ブルガリア語
-
アルメニア語
-
クロアチア語
-
アフリカーンス語
-
デンマーク語
-
チェコ語
-
フィリピン語
-
フィンランド語
-
フランス語
- ドイツ語
-
- より多くの言語パックが利用可能です。詳細を見るには、次のリンクをご覧ください。 IronOCR 言語パック
-
.NETでそのまま動作します。
-
Xamarinのサポート
-
Mono対応
-
マイクロソフト アジュールのサポート
-
Microsoft AzureでのDockerサポート
-
PDFドキュメントをサポート
- マルチフレームTIFFをサポート
-
- すべての主要な画像フォーマットをサポート
-
対応している .NET Framework は以下の通りです:
-
.NET Framework 4.5以降
-
.NET Standard 2
-
.NET Core 2
- .NET Core 3
-
- .NET Core 5
-
IronOCRを動作させるために、Tesseract(Unicodeをサポートし、100以上の言語をサポートするオープンソースのOCRエンジン)をインストールする必要はありません。
- Tesseractよりも精度が向上しています
- Tesseractよりも速度が向上しました
- 低品質なスキャンドキュメントやファイルを修正します。
- 低品質で傾いたドキュメントやファイルのスキャンを修正します
OCR(光学文字認識)とは何ですか?
Wikipediaによると、光学文字認識(Optical Character Recognition)は、スキャンされた文書、文書の写真、シーン写真、または画像に重ねられた字幕テキストなどのタイプされた、印刷されたテキストの画像を機械でエンコードされたテキストに電子的または機械的に変換することです。 OCRは光学式文字認識(Optical Character Recognition)の略です。 本質的に、光学文字認識には4つのタイプがあります。それらは:
- OCR(光学文字認識)は、入力ドキュメントのタイプされたテキストを対象とし、一度に1文字またはグリフ(合意された一連の記号内の基本記号、例えば異なるフォントの「a」)を認識する技術です。
- OWR - 光学単語認識は、入力ドキュメントからタイプライティングされたテキストを一度に一単語ずつ認識する技術です。
- ICR - インテリジェント文字認識は、印刷されたテキストや筆記体(他の文字と接続しない文字)などを対象に、一文字またはグリフずつ認識を行います。
- IWR - インテリジェントワード認識、手書き文字を対象とします。






