



Testez dans un environnement en direct
Testez en production sans filigranes.
Fonctionne où que vous en ayez besoin.

using IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR prend en charge 125 langues internationales. Outre l'anglais, installé par défaut, des modules linguistiques supplémentaires peuvent être ajoutés à votre projet .NET via NuGet ou téléchargés depuis notre page Langues . La plupart des langues sont disponibles en qualité Rapide, Standard (recommandée) et Meilleure. L'option de meilleure qualité peut offrir des résultats plus précis, mais sera également plus lente en termes de temps de traitement. Explorez la reconnaissance optique de caractères (OCR) en plusieurs langues avec IronOCR.Prise en charge linguistique d'IronOCR
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR renvoie un objet de résultat avancé pour chaque page qu'il analyse en utilisant Tesseract 5. Ce fichier contient des données de localisation, des images, du texte, un niveau de confiance statistique, des choix de symboles alternatifs, les noms de police, les tailles de police, la décoration, les graisses de police et la position de chaque élément :
Page Paragraph Word Barcode Découvrez comment lire les résultats de la reconnaissance optique de caractères (OCR) avec IronOCR.

Que ce soit pour des questions sur le produit, l'intégration ou les licences, l'équipe de développement de produits Iron est à disposition pour répondre à toutes vos questions. Prenez contact et démarrez un dialogue avec Iron pour tirer le meilleur parti de notre bibliothèque dans votre projet.
Poser une question
Que ce soit des pages de passeport, des factures, des relevés bancaires, du courrier, des cartes de visite ou des reçus; la reconnaissance optique de caractères (OCR) est un domaine de recherche basé sur la reconnaissance de motifs, la vision par ordinateur et l'apprentissage machine. Les entreprises utilisent l'OCR de manière inter-départementale pour extraire du texte dans les systèmes de comptabilité et de finance, la numérisation des affaires, la gestion de contenu d'entreprise et les systèmes de rapport de données.
En plus de construire d'autres histoires de réussite. IronOCR ajoute de la valeur à Google Tesseract et aux services cognitifs Microsoft Azure 2021 avec IronOCR - une bibliothèque OCR native C#.
Si vous cherchez à convertir des images du monde réel avec une précision de 99 pour cent - alors continuez à lire, pour voir comment IronOCR vous permet de créer une application de reconnaissance optique de caractères efficace, précise, évolutive et presque humaine.
La reconnaissance optique de caractères (OCR) est considérée comme un phénomène résolu en raison de l'immense confiance que revendiquent différentes API envers la protection. Cependant, les divers produits sont souvent rigides et imprécis, échouant dans les applications du monde réel. De même, Tesseract OCR fonctionne avec du texte imprimé par machine, à haute résolution, parfait.
Cela semble bien ?
Seulement, le monde réel n'a pas toujours du texte parfaitement imprimé et manuscrit avec une haute résolution. Au lieu de cela, le texte tourné, déformé, avec une faible densité de pixels, du bruit de fond et tous les fléaux des imperfections numériques sont pris en charge par IronOCR, y compris l'extraction de texte manuscrit à partir de fichiers d'images. Nous garantissons un document précis à 99,8 - 100 pour cent, consultable avec prise en charge multiplateforme qui inclut Windows, Linux, macOS, Microsoft Azure, AWS et Docker - Il y a une raison pour laquelle les développeurs C# choisissent IronOCR plutôt que (basiquement) Tesseract OCR - il s'agit tout simplement d'ajouter de la valeur.
Équipez-vous du meilleur !
En plus de ce qui précède, IronOCR vous équipe pour traiter rapidement les documents d'images. Si cela ne suffit pas, les fonctionnalités de l'API IronOCR incluent également les éléments suivants :
Opposez-vous à l'installation de .dlls ou exécutables natives en optant pour une source unique de vérité - développez en utilisant une bibliothèque de composants unique et native en .NET utilisant des API C# simples qui prennent en charge :
L'art de l'API IronOCR ne se limite pas en ces termes; vous pouvez continuer à explorer notre avancée technique features plus loin. Nous réduisons les complexités d'affaires, une étape à la fois, en développant des solutions fiables pour rationaliser les applications de traitement de documents et maximiser les revenus d'entreprise en offrant des fonctionnalités leaders sur le marché qui ont été intégrées :
Notre processus de reconnaissance optique de caractères commence par un prétraitement automatique de l'image, pour améliorer le fichier image qui améliore le taux de réponse d'extraction. IronOCR ajoute de la valeur à votre travail en permettant aux utilisateurs d'extraire l'image de base exemple dans la version optimale de lui-même. IronOCR couvre toutes les bases :
Comme le service IronOCR fonctionne de manière optimale sur des fichiers image de 300 PPP (Points Par Pouce), toute image qui est significativement en dehors de 200-300 PPP est rééchantillonnée pour s'intégrer dans la gamme ciblée.
Ceci se traduit par un sous-échantillonnage des images 600 PPP à 300 PPP ou un sur-échantillonnage des images 100 PPP à 200 PPP avec une confiance de 99 pour cent.
Comme les services cognitifs IronOCR sont conçus pour fonctionner sur des images monochromatiques, toutes les images colorées ou en niveaux de gris sont converties en monochromatiques, utilisant un algorithme de binarisation adaptatif.
L'algorithme compare les densités de pixels dans une zone qui détermine le seuil à utiliser pour convertir les pixels en monochromatique.
IronOCR recherche des lignes de texte et des motifs de caractères pour rectifier et faire pivoter automatiquement les ressources d'image d'entrée à l'orientation souhaitée.
Avec IronOCR, les fichiers d'image sont automatiquement analysés pour la présence et la quantité de bruit. Le bruit est essentiellement les 'taches' trouvées sur les images scannées. Notre algorithme adaptatif supprime alors le bruit en fonction de la taille des particules de bruit.
Dès que le fichier image échantillon est pré-traité, IronOCR segmente alors le fichier image d'entrée en différentes zones de traitement.
Une autre étape de pré-préparation implique la division de l'image de référence en différentes zones logiques. IronOCR localise d'abord le texte et les images à l'intérieur de l'image avec l'aide de l'espace blanc, et des motifs ; la région de texte est séparée des images.
Elle est ensuite partitionnée en zones - paragraphes, colonnes et blocs de texte. Les images et les pixels non-textuels restants sont identifiés pour être omis lors de la reconnaissance du texte et inclus dans la sortie intelligente. IronOCR marque ensuite les zones de texte comme tableaux avec l'aide de lignes de grille et de blocs de texte.
Exécute plusieurs étapes interconnectées qui convertissent les amas de pixels en fils de texte à une seule ligne que les utilisateurs peuvent rechercher. Cela inclut la segmentation des caractères, la classification adaptative, les références de dictionnaire et d'autres processus connexes qui contribuent au texte extrait optimal.
Avec le service API IronOCR, nous avons testé notre outil à travers de multiples exemples de fichiers de données dans plusieurs langues qui incluent les niveaux de mots, la précision des symboles, et le maintien de la mise en page dans les formats Microsoft Office. Bien que certains paramètres soient automatiquement testés; d'autres incluent des vérifications visuelles.
IronOCR vous permet d'ajouter des capacités OCR multiplateformes avec de multiples formats d'entrée à une chaîne de texte brut que vous pouvez rechercher. Pour renforcer votre productivité avec IronOCR, commencez avec notre documentation tutoriel gratuite qui vous guide dans l'utilisation d'IronOCR. Téléchargez aujourd'hui notre installateur de package NuGet, et explorez avec une clé d'essai gratuite ou connectez-vous à notre support personnel 24/7. Échelonnez vos besoins avec notre licensing à vie, indépendamment de la taille de votre équipe.
Fonctionne avec .NET, VB.NET, C#
Voir LicencesGratuit licences de développement communautaire. Licences commerciales à partir de 749 $.





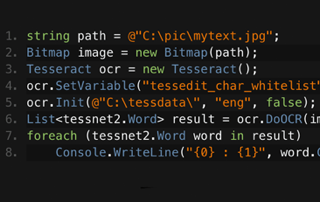
C# Tesseract OCR

Jim a été un leader dans le développement d'IronOCR. Jim conçoit et construit des algorithmes de traitement d'image et des méthodes de lecture pour l'OCR.
Voir Comparaison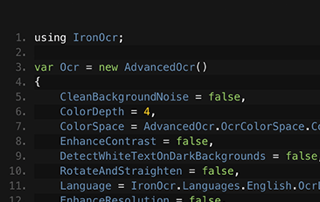
C# OCR ASP.NET

Apprenez comment l'équipe de Gemma utilise IronOCR pour lire du texte à partir d'images pour leur logiciel d'archivage. Gemma partage ses propres exemples de code.
Tutoriel Image à Texte .NET




L'équipe d'Iron a plus de 10 ans d'expérience dans le marché des composants logiciels .NET.








Install-Package IronOcr

Votre clé d'essai devrait être dans l'e-mail.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Testez en production sans filigranes.
Fonctionne où que vous en ayez besoin.
Profitez de 30 jours de produit entièrement fonctionnel.
Configurez-le et faites-le fonctionner en quelques minutes.
Accès complet à notre équipe de support technique durant votre essai produit
Une démonstration en direct de notre produit et de ses fonctionnalités clés
Obtenez des recommandations de fonctionnalités spécifiques au projet
Nous répondons à toutes vos questions afin de nous assurer que vous disposez de toutes les informations dont vous avez besoin. (Sans aucun engagement)





Réservez une Consultation sans Engagement

Remplissez le formulaire ci-dessous ou envoyez un email à sales@ironsoftware.com
Vos informations seront toujours gardées confidentielles.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagement.


