

Comment construire un service Azure OCR en utilisant IronOCR
Iron Software a créé une bibliothèque OCR (reconnaissance optique de caractères) qui élimine les problèmes d'interopérabilité liés à l'intégration de l'OCR Azure. Travailler avec des bibliothèques OCR sur Azure a toujours été un peu pénible pour les développeurs. La solution à ce problème et à bien d'autres maux de tête liés à l'OCR est IronOCR.
Fonctionnalités de l'IronOCR pour Microsoft Azure
IronOCR comprend les fonctionnalités suivantes pour créer un service d'OCR sur Microsoft Azure :
- Transforme les PDF en documents consultables afin d'en extraire facilement le texte
- Transforme les images en documents consultables en extrayant le texte des images
- Lit les codes-barres et les codes QR
- Une précision exceptionnelle
- S'exécute localement et ne nécessite aucun SaaS (Software as a Service), un modèle de distribution de logiciels dans lequel un fournisseur de cloud, tel que Microsoft Azure, héberge diverses applications et met ces applications à disposition des utilisateurs finaux.
Une vitesse fulgurante
Voyons comment le meilleur moteur d'OCR, Iron Software's IronOCR, permet aux développeurs d'extraire plus facilement du texte à partir de n'importe quel document d'entrée.
Commençons par notre service Azure OCR
Pour commencer à utiliser l'exemple, nous devons d'abord installer IronOCR.
Créer une nouvelle application Console avec C#
Installez IronOCR via NuGet soit en entrant : Install-Package IronOcr ou en sélectionnant Manage NuGet packages et en recherchant IronOCR. Le tableau ci-dessous en est l'illustration
- Modifiez votre fichier Program.cs pour qu'il ressemble à ce qui suit :
- Nous importons l'espace de noms IronOcr afin d'utiliser ses capacités d'ocr pour lire et extraire le contenu du fichier PDF.
- Nous créons un nouvel objet IronTesseract, afin de pouvoir extraire du texte d'une image.
using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string [] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); //Read PNG image File
Console.WriteLine(result.Text); //Write Output to PDF document
Console.ReadLine();
}
}
}
}using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string [] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); //Read PNG image File
Console.WriteLine(result.Text); //Write Output to PDF document
Console.ReadLine();
}
}
}
}Imports IronOcr
Imports System
Namespace IronOCR_Ex
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim ocr = New IronTesseract()
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim result = ocr.Read(Input) 'Read PNG image File
Console.WriteLine(result.Text) 'Write Output to PDF document
Console.ReadLine()
End Using
End Sub
End Class
End NamespaceEnsuite, nous ouvrons une image nommée Purgatory.PNG. Cette image fait partie de la Comédie divine de Dante, l'un de mes livres préférés. L'image ressemble à l'image suivante.

Figure 2 - Le texte à extraire avec les capacités de reconnaissance optique de caractères d'IronOCR
La sortie après le texte ci-dessus a été extraite du texte de l'image d'entrée ci-dessus.
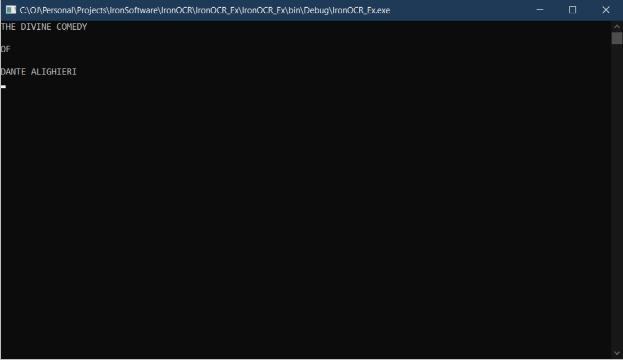
Figure 3 - Texte extrait
Faisons de même avec un document PDF. Le document PDF contient le même texte à extraire que la figure.
La seule différence est que nous serons un document PDF au lieu d'une image. Entrez le code suivant :
var Ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; //Give title to input document
//Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var Result = Ocr.Read(input); //Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
} var Ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; //Give title to input document
//Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var Result = Ocr.Read(input); //Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
}Dim Ocr = New IronTesseract()
Using input = New OcrInput()
input.Title = "Divine Comedy - Purgatory" 'Give title to input document
'Supply optional password and name of document
input.AddPdf("..\Documents\Purgatorio.pdf", "dante")
Dim Result = Ocr.Read(input) 'Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf")
End UsingPresque le même que le code précédent qui extrait le texte d'une image.
Ici, nous utilisons la méthode OcrInput pour lire le document PDF actuel, dans ce cas : Purgatorio.pdf. Si le fichier PDF contient des métadonnées telles qu'un titre ou un mot de passe, nous pouvons également les introduire.
Le résultat est enregistré sous la forme d'un document PDF dans lequel nous pouvons rechercher du texte.
Remarque : si le fichier PDF est trop volumineux, une exception peut être levée.
Assez sur les applications Windows ; voyons comment nous pouvons utiliser l'ocr avec Microsoft Azure.
La beauté d'IronOCR est qu'il fonctionne très bien avec Microsoft Azure en tant qu'Azure Function dans une architecture de microservices. Voici un exemple très rapide sur ce à quoi ressemblerait une fonction Microsoft Azure qui fonctionne avec IronOCR. Cette fonction Microsoft Azure extrait du texte à partir d'images.
public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query ["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query ["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} Public Module OCRFunction
Public hcClient As New HttpClient()
<FunctionName("IronOCRFunction_EX")>
Public Async Function Run(<HttpTrigger> ByVal hrRequest As HttpRequest, ByVal ecContext As ExecutionContext) As Task(Of IActionResult)
Dim URI = hrRequest.Query ("image")
Dim saStream = Await hcClient.GetStreamAsync(URI)
Dim ocr = New IronTesseract()
Using inputOCR = New OcrInput(saStream)
Dim outputOCR = ocr.Read(inputOCR)
Return New OkObjectResult(outputOCR.Text)
End Using
End Function
End ModuleL'image reçue par la fonction est ainsi directement transmise au moteur d'ocr pour être restituée sous la forme d'un texte extrait.
Un bref rappel sur Microsoft Azure.
Selon Microsoft : Microsoft Azure Microservices est une approche architecturale de la construction d'applications où chaque fonction centrale, ou service, est construite et déployée de manière indépendante. L'architecture microservice est distribuée et faiblement couplée, de sorte que la défaillance d'un composant n'affecte pas l'ensemble de l'application. Les composants indépendants travaillent ensemble et communiquent à l'aide de contrats API bien définis. Créez des applications microservices pour répondre à l'évolution rapide des besoins de l'entreprise et mettre plus rapidement de nouvelles fonctionnalités sur le marché.
Voici quelques autres caractéristiques d'IronOCR for .NET ou Microsoft Azure :
La possibilité d'effectuer une ocr sur presque n'importe quel fichier, image ou PDF.
- Une vitesse fulgurante dans le traitement des données ocr
- Une précision exceptionnelle
- Lecture des codes-barres et des codes QR
- Fonctionne localement, sans SaaS
- Peut transformer des PDF et des images en documents consultables
- Une excellente alternative à Azure OCR de Microsoft Cognitive Services
Filtres d'image pour améliorer les performances de l'OCR
- OcrInput.Rotate - Fait pivoter les images de plusieurs degrés dans le sens horaire. Pour le sens antihoraire, utilisez des nombres négatifs.
- OcrInput.Binarize() - Ce filtre d'image transforme chaque pixel en noir ou en blanc sans nuance intermédiaire. Les performances de l'OCR s'en trouvent améliorées.
- OcrInput.ToGrayScale() - Ce filtre d'image transforme chaque pixel en une nuance de gris. La vitesse de l'OCR s'en trouve améliorée
- OcrInput.Contrast() - Augmente automatiquement le contraste. Ce filtre améliore la vitesse et la précision de l'ocr dans les scans à faible contraste.
- OcrInput.DeNoise() - Supprime le bruit numérique. Ce filtre doit être utilisé uniquement là où du bruit est attendu dans les documents d'entrée.
- OcrInput.Invert() - Inverse toutes les couleurs.
- OcrInput.Dilate() - La dilatation ajoute des pixels aux frontières de tout objet dans une image.
- OcrInput.Erode() - L'érosion supprime les pixels sur les frontières des objets.
- OcrInput.Deskew() - Fait pivoter une image pour qu'elle soit à l'endroit et orthogonale. Ceci est très utile pour l'OCR car la tolérance de Tesseract pour les scans biaisés peut être aussi basse que 5 degrés.
- OcrInput.DeepCleanBackgroundNoise() - Suppression intense du bruit de fond.
- OcrInput.EnhanceResolution - Améliore la résolution d'une image de basse qualité.
Performances en matière de vitesse
En voici un exemple :
var Ocr = new IronTesseract();
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][
\\";
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
Ocr.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
} var Ocr = new IronTesseract();
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][
\\";
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
Ocr.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}Dim Ocr = New IronTesseract()
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][ \\"
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly
Ocr.Language = OcrLanguage.EnglishFast
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim Result = Ocr.Read(Input)
Console.WriteLine(Result.Text)
End UsingPrix et options de licence
Il existe essentiellement trois niveaux de licence payants qui fonctionnent tous sur le principe d'un achat unique pour une licence à vie.
Et oui, ils sont gratuits à des fins de développement.
Plus d'informations
- Des ressources supplémentaires peuvent être trouvées au lien suivant : Resources
- Les références de l'API peuvent être trouvées ici : Références de l'API
- Le support pour les produits IronOCR peut être trouvé ici : Support
- Contactez Iron Software : Informations de contact
Fonctionnalités d'IronOCR pour les applications .NET exécutant l'OCR sur Azure et d'autres systèmes
IronOCR prend en charge 127 langues internationales. Chaque langue est disponible en qualité Rapide, Standard et Meilleure. Parmi les packs de langues disponibles, citons
Bulgare
Arménien
Croate
Afrikaans
Danois
Tchèque
Philippin
Finlandais
Français
- Allemand
- De nombreux autres packs linguistiques sont disponibles. Pour les consulter, cliquez sur le lien suivant. Packs de langues IronOCR
Il est prêt à l'emploi dans .NET
Prise en charge de Xamarin
Prise en charge de Mono
Prise en charge de Microsoft Azure
Prise en charge de Docker sur Microsoft Azure
Prise en charge des documents PDF
- Prise en charge des Tiffs multiframes
- Prise en charge de tous les principaux formats d'image
Les Framework .NET suivants sont pris en charge :
framework .NET 4.5 et supérieur
standard .NET 2
.NET Core 2
- .NET Core 3
- .NET Core 5
Vous n'avez pas besoin d'avoir Tesseract (un moteur OCR open-source qui prend en charge Unicode et supporte plus de 100 langues) installé pour qu'IronOCR fonctionne.
- Précision améliorée par rapport au Tesseract
- Vitesse améliorée par rapport au Tesseract
- Corrige les numérisations de mauvaise qualité de documents ou de fichiers
- Corrige les numérisations obliques de documents ou de fichiers de mauvaise qualité
Qu'est-ce que la reconnaissance optique de caractères (OCR) ?
Selon Wikipedia : La reconnaissance optique de caractères est la conversion électronique ou mécanique d'images de textes dactylographiés ou imprimés en textes codés par une machine, que ce soit à partir d'un document scanné, d'une photo d'un document, d'une photo de scène ou d'un texte de sous-titres superposé à une image. Ocr est l'abréviation de Optical Character Recognition (reconnaissance optique de caractères). Il existe essentiellement quatre types de reconnaissance optique de caractères :
- OCR - Reconnaissance Optique de Caractères, qui cible le texte tapé d'un document d'entrée, un caractère ou glyphe (symbole élémentaire au sein d'un ensemble de symboles convenus, par exemple "a" dans différentes polices) à la fois.
- OWR - Optical Word Recognition, qui cible le texte dactylographié à partir d'un document d'entrée, un mot à la fois
- ICR - Reconnaissance Intelligente de Caractères, qui cible le texte imprimé tel que l'écriture script (caractères sans liaison avec d'autres lettres) et l'écriture cursive, un caractère ou glyphe à la fois
- IWR - Intelligent Word Recognition (reconnaissance intelligente des mots), qui cible les textes en cursive.






