

Aufbau eines Azure OCR-Dienstes mit IronOCR
Iron Software hat eine OCR-Bibliothek (Optical Character Recognition) entwickelt, die die Interoperabilitätsprobleme bei der Integration von Azure OCR beseitigt. Die Arbeit mit OCR-Bibliotheken auf Azure war für Entwickler schon immer ein wenig mühsam. Die Lösung für diese und viele andere OCR-Kopfschmerzen ist IronOCR.
IronOCR-Funktionen für Microsoft Azure
IronOCR umfasst die folgenden Funktionen für den Aufbau eines OCR-Dienstes auf Microsoft Azure:
- Wandelt PDFs in durchsuchbare Dokumente um, so dass es einfach ist, Text zu extrahieren
- Verwandelt Bilder in durchsuchbare Dokumente durch Extraktion von Text aus Bildern
- Liest sowohl Barcodes als auch QR-Codes
- Außergewöhnliche Genauigkeit
- Läuft lokal und erfordert kein SaaS (Software as a Service), bei dem es sich um ein Softwarebereitstellungsmodell handelt, bei dem ein Cloud-Anbieter, wie Microsoft Azure, verschiedene Anwendungen hostet und diese Anwendungen Endbenutzern zur Verfügung stellt.
Blitzschnelle Geschwindigkeit
Werfen wir einen Blick darauf, wie die beste OCR-Engine, Iron Software's IronOCR, es Entwicklern erleichtert, Text aus beliebigen Eingabedokumenten zu extrahieren.
Lassen Sie uns mit unserem Azure OCR Service beginnen
Um mit dem Beispiel beginnen zu können, müssen wir zunächst IronOCR installieren.
Erstellen einer neuen Konsolenanwendung mit C#
Installieren Sie IronOCR über NuGet entweder durch Eingabe von: Install-Package IronOcr oder durch Auswahl von Manage NuGet packages und Suche nach IronOCR. Dies wird im Folgenden dargestellt
- Bearbeiten Sie Ihre Datei Program.cs so, dass sie wie folgt aussieht:
- Wir importieren den IronOcr-Namensraum, um seine Ocr-Fähigkeiten zum Lesen und Extrahieren des Inhalts der PDF-Datei zu nutzen.
- Wir erstellen ein neues IronTesseract-Objekt, mit dem wir Text aus einem Bild extrahieren können.
using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string [] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); //Read PNG image File
Console.WriteLine(result.Text); //Write Output to PDF document
Console.ReadLine();
}
}
}
}using IronOcr;
using System;
namespace IronOCR_Ex
{
class Program
{
static void Main(string [] args)
{
var ocr = new IronTesseract();
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var result = ocr.Read(Input); //Read PNG image File
Console.WriteLine(result.Text); //Write Output to PDF document
Console.ReadLine();
}
}
}
}Imports IronOcr
Imports System
Namespace IronOCR_Ex
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim ocr = New IronTesseract()
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim result = ocr.Read(Input) 'Read PNG image File
Console.WriteLine(result.Text) 'Write Output to PDF document
Console.ReadLine()
End Using
End Sub
End Class
End NamespaceAls nächstes öffnen wir ein Bild mit dem Namen Purgatory.PNG. Dieses Bild ist Teil der Göttlichen Komödie von Dante - eines meiner Lieblingsbücher. Das Bild sieht so aus wie das folgende Bild.

Abbildung 2 - Der Text, der mit den optischen Zeichenerkennungsfähigkeiten von IronOCR extrahiert werden soll
Die Ausgabe, nachdem der obige Text aus dem obigen Eingabebildtext extrahiert wurde.
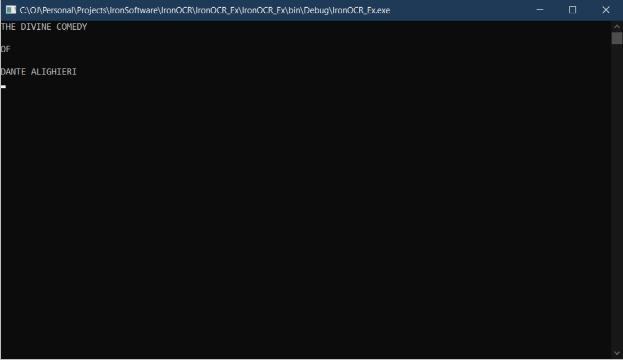
Abbildung 3 - Extrahierter Text
Machen wir das Gleiche mit einem PDF-Dokument. Das PDF-Dokument enthält den gleichen zu extrahierenden Text wie die Abbildung.
Der einzige Unterschied besteht darin, dass es sich um ein PDF-Dokument und nicht um ein Bild handelt. Geben Sie den folgenden Code ein:
var Ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; //Give title to input document
//Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var Result = Ocr.Read(input); //Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
} var Ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.Title = "Divine Comedy - Purgatory"; //Give title to input document
//Supply optional password and name of document
input.AddPdf("..\\Documents\\Purgatorio.pdf", "dante");
var Result = Ocr.Read(input); //Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf");
}Dim Ocr = New IronTesseract()
Using input = New OcrInput()
input.Title = "Divine Comedy - Purgatory" 'Give title to input document
'Supply optional password and name of document
input.AddPdf("..\Documents\Purgatorio.pdf", "dante")
Dim Result = Ocr.Read(input) 'Read the input file
Result.SaveAsSearchablePdf("SearchablePDFDocument.pdf")
End UsingFast das Gleiche wie der vorherige Code, der Text aus einem Bild extrahiert.
Hier verwenden wir die Methode OcrInput, um das aktuelle PDF-Dokument zu lesen, in diesem Fall: Purgatorio.pdf. Wenn die PDF-Datei Metadaten wie einen Titel oder ein Kennwort enthält, können wir diese ebenfalls einfügen.
Das Ergebnis wird als PDF-Dokument gespeichert, in dem wir nach Text suchen können.
Hinweis: Wenn die PDF-Datei zu groß ist, kann eine Ausnahme ausgelöst werden.
Das reicht bei Windows-Anwendungen; schauen wir uns an, wie wir OCR mit Microsoft Azure nutzen können.
Das Schöne an IronOCR ist, dass es sehr gut mit Microsoft Azure als Azure-Funktion in einer Microservice-Architektur funktioniert. Hier ist ein sehr schnelles Beispiel, wie eine Microsoft Azure-Funktion, die mit IronOCR arbeitet, aussehen könnte. Diese Microsoft Azure-Funktion extrahiert Text aus Bildern.
public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query ["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} public static class OCRFunction
{
public static HttpClient hcClient = new HttpClient();
[FunctionName("IronOCRFunction_EX")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest hrRequest, ExecutionContext ecContext)
{
var URI = hrRequest.Query ["image"];
var saStream = await hcClient.GetStreamAsync(URI);
var ocr = new IronTesseract();
using (var inputOCR = new OcrInput(saStream))
{
var outputOCR = ocr.Read(inputOCR);
return new OkObjectResult(outputOCR.Text);
}
}
} Public Module OCRFunction
Public hcClient As New HttpClient()
<FunctionName("IronOCRFunction_EX")>
Public Async Function Run(<HttpTrigger> ByVal hrRequest As HttpRequest, ByVal ecContext As ExecutionContext) As Task(Of IActionResult)
Dim URI = hrRequest.Query ("image")
Dim saStream = Await hcClient.GetStreamAsync(URI)
Dim ocr = New IronTesseract()
Using inputOCR = New OcrInput(saStream)
Dim outputOCR = ocr.Read(inputOCR)
Return New OkObjectResult(outputOCR.Text)
End Using
End Function
End ModuleDadurch wird das von der Funktion empfangene Bild direkt an die OCR-Engine weitergeleitet, die es als extrahierten Text ausgibt.
Eine kurze Zusammenfassung über Microsoft Azure.
Nach Angaben von Microsoft: Microsoft Azure Microservices sind ein architektonischer Ansatz für den Aufbau von Anwendungen, bei dem jede Kernfunktion oder jeder Dienst unabhängig aufgebaut und bereitgestellt wird. Die Microservice-Architektur ist verteilt und lose gekoppelt, so dass der Ausfall einer Komponente nicht die gesamte Anwendung gefährdet. Unabhängige Komponenten arbeiten zusammen und kommunizieren über klar definierte API-Verträge. Erstellen Sie Microservice-Anwendungen, um schnell wechselnde Geschäftsanforderungen zu erfüllen und neue Funktionen schneller auf den Markt zu bringen.
Einige weitere Funktionen von IronOCR for .NET oder Microsoft Azure sind die folgenden
Die Möglichkeit, fast jede Datei, jedes Bild oder jede PDF-Datei mit OCR zu bearbeiten.
- Blitzschnelle Verarbeitung von OCR-Eingaben
- Außergewöhnliche Genauigkeit
- Liest Barcodes und QR-Codes
- Läuft lokal, kein SaaS erforderlich
- Kann PDFs und Bilder in durchsuchbare Dokumente umwandeln
- Ausgezeichnete Alternative zu Azure OCR von Microsoft Cognitive Services
Bildfilter zur Verbesserung der OCR-Leistung
- OcrInput.Rotate - Dreht Bilder um mehrere Grad im Uhrzeigersinn. Für gegen den Uhrzeigersinn verwenden Sie negative Zahlen.
- OcrInput.Binarize() - Dieser Bildfilter macht jeden Pixel schwarz oder weiß, ohne Zwischentöne. Dies verbessert die OCR-Leistung.
- OcrInput.ToGrayScale() - Dieser Bildfilter wandelt jeden Pixel in einen Grauton um. Dies verbessert die OCR-Geschwindigkeit
- OcrInput.Contrast() - Erhöht den Kontrast automatisch. Dieser Filter verbessert die OCR-Geschwindigkeit und Genauigkeit bei kontrastarmen Scans.
- OcrInput.DeNoise() - Entfernt digitales Rauschen. Dieser Filter sollte nur verwendet werden, wenn in Eingangsdokumenten Rauschen erwartet wird.
- OcrInput.Invert() - Kehrt jede Farbe um.
- OcrInput.Dilate() - Die Erweiterung fügt den Rändern eines Objekts in einem Bild Pixel hinzu.
- OcrInput.Erode() - Erosion entfernt Pixel an den Objektgrenzen.
- OcrInput.Deskew() - Dreht ein Bild, damit es richtig ausgerichtet und orthogonal ist. Dies ist für die OCR sehr nützlich, da die Toleranz von Tesseract bei schiefen Scans bis zu 5 Grad betragen kann.
- OcrInput.DeepCleanBackgroundNoise() - Starke Entfernung von Hintergrundgeräuschen.
- OcrInput.EnhanceResolution - Verbessert die Auflösung eines minderwertigen Bildes.
Geschwindigkeitsleistung
Es folgt ein Beispiel:
var Ocr = new IronTesseract();
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][
\\";
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
Ocr.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
} var Ocr = new IronTesseract();
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][
\\";
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
Ocr.Language = OcrLanguage.EnglishFast;
using (var Input = new OcrInput("..\\Images\\Purgatory.PNG"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}Dim Ocr = New IronTesseract()
Ocr.Configuration.BlackListCharacters = "~`$#^*_}{][ \\"
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5
Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly
Ocr.Language = OcrLanguage.EnglishFast
Using Input = New OcrInput("..\Images\Purgatory.PNG")
Dim Result = Ocr.Read(Input)
Console.WriteLine(Result.Text)
End UsingPreisgestaltung und Lizenzierungsoptionen
Es gibt im Wesentlichen drei kostenpflichtige Lizenzstufen, die alle auf dem Prinzip eines einmaligen Kaufs mit lebenslanger Lizenz beruhen.
Und ja, diese sind für Entwicklungszwecke kostenlos.
Weitere Informationen
- Zusätzliche Ressourcen finden Sie unter folgendem Link: Ressourcen
- API-Referenzen können hier gefunden werden: API-Referenzen
- Unterstützung für IronOCR-Produkte finden Sie hier: Support
- Kontaktieren Sie Iron Software: Kontaktinformationen
IronOCR-Funktionen für .NET-Anwendungen, die OCR auf Azure und anderen Systemen ausführen
IronOCR unterstützt 127 internationale Sprachen. Jede Sprache ist in schneller, Standard- und bester Qualität verfügbar. Einige der verfügbaren Sprachpakete sind:
Bulgarisch
Armenisch
Kroatisch
Afrikaans
Dänisch
Tschechisch
Filipino
Finnisch
Französisch
- Deutsch
- Es gibt noch viele weitere Sprachpakete, die Sie sich unter dem folgenden Link ansehen können. IronOCR-Sprachpakete
Es funktioniert sofort nach dem Auspacken in .NET
Unterstützung für Xamarin
Unterstützung für Mono
Unterstützung für Microsoft Azure
Unterstützung für Docker auf Microsoft Azure
Unterstützt PDF-Dokumente
- Unterstützt Multiframe Tiffs
- Unterstützung für alle wichtigen Bildformate
Die folgenden .NET-Frameworks werden unterstützt:
.NET-Framework 4.5 und höher
.NET-Standard 2
.NET Core 2
- .NET Core 3
- .NET Core 5
Sie müssen Tesseract (eine Open-Source-OCR-Engine, die Unicode unterstützt und mehr als 100 Sprachen unterstützt) nicht installiert haben, damit IronOCR funktioniert.
- Verbesserte Genauigkeit gegenüber Tesseract
- Verbesserte Geschwindigkeit gegenüber Tesseract
- Korrigiert qualitativ schlechte Scans von Dokumenten oder Dateien
- Korrigiert schiefe Scans von Dokumenten oder Dateien mit schlechter Qualität
Was ist OCR (Optical Character Recognition)?
Laut Wikipedia: Optische Zeichenerkennung ist die elektronische oder mechanische Umwandlung von Bildern aus getipptem, gedrucktem Text in maschinell kodierten Text, sei es aus einem gescannten Dokument, einem Foto eines Dokuments, einem Szenenfoto oder aus einem Untertiteltext, der einem Bild überlagert ist. Ocr steht für Optical Character Recognition (optische Zeichenerkennung). Es gibt im Wesentlichen vier Arten der optischen Zeichenerkennung, nämlich:
- OCR - Optische Zeichenerkennung, die sich auf maschinengeschriebenen Text aus einem Eingabedokument konzentriert, ein Zeichen oder Glyph (elementares Symbol innerhalb eines vereinbarten Satzes von Symbolen, zum Beispiel 'a' in verschiedenen Schriftarten) auf einmal.
- OWR - Optical Word Recognition (Optische Worterkennung), die einen maschinengeschriebenen Text aus einem Eingabedokument wortweise erkennt
- ICR - Intelligente Zeichenerkennung, die auf gedruckten Text wie Druckschrift (Zeichen ohne Verbindung zu anderen Buchstaben) und Kursivschrift abzielt, ein Zeichen oder Glyph nach dem anderen
- IWR - Intelligent Word Recognition (Intelligente Worterkennung), die auf kursiven Text ausgerichtet ist.






