

在實際環境中進行測試
在生產環境中測試,無浮水印。
無論您在哪裡需要,它都能運作。

30DAYFREE
using IronWebScraper;
public class Program
{
private static void Main(string[] args)
{
var ScrapeJob = new BlogScraper();
ScrapeJob.Start();
}
}
public class BlogScraper : WebScraper
{
public override void Init()
{
LoggingLevel = LogLevel.All;
Request("https://www.zyte.com/blog/", Parse);
}
public override void Parse(Response response)
{
foreach (HtmlNode title_link in response.Css(".oxy-post-title"))
{
string strTitle = title_link.TextContentClean;
Scrape(new ScrapedData() { { "Title", strTitle } });
}
if (response.CssExists("div.oxy-easy-posts-pages > a[href]"))
{
string next_page = response.Css("div.oxy-easy-posts-pages > a[href]")[0].Attributes["href"];
Request(next_page, Parse);
}
}
}Install-Package IronWebScraper
設計為C#, F#, & VB.NET運行於.NET 10, 9, 8, 7, 6, 5, Core, Standard,或 Framework

")
")
")
")
")
")
")
")
")
")
")
")
")
")
using IronWebScraper;
public class Program
{
private static void Main(string[] args)
{
var ScrapeJob = new BlogScraper();
ScrapeJob.Start();
}
}
public class BlogScraper : WebScraper
{
public override void Init()
{
LoggingLevel = LogLevel.All;
Request("https://www.zyte.com/blog/", Parse);
}
public override void Parse(Response response)
{
foreach (HtmlNode title_link in response.Css(".oxy-post-title"))
{
string strTitle = title_link.TextContentClean;
Scrape(new ScrapedData() { { "Title", strTitle } });
}
if (response.CssExists("div.oxy-easy-posts-pages > a[href]"))
{
string next_page = response.Css("div.oxy-easy-posts-pages > a[href]")[0].Attributes["href"];
Request(next_page, Parse);
}
}
}Imports IronWebScraper
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim ScrapeJob = New BlogScraper()
ScrapeJob.Start()
End Sub
End Class
Public Class BlogScraper
Inherits WebScraper
Public Overrides Sub Init()
LoggingLevel = LogLevel.All
Request("https://www.zyte.com/blog/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each title_link As HtmlNode In response.Css(".oxy-post-title")
Dim strTitle As String = title_link.TextContentClean
Scrape(New ScrapedData() From {
{ "Title", strTitle }
})
Next title_link
If response.CssExists("div.oxy-easy-posts-pages > a[href]") Then
Dim next_page As String = response.Css("div.oxy-easy-posts-pages > a[href]")(0).Attributes("href")
Request(next_page, AddressOf Parse)
End If
End Sub
End ClassInstall-Package IronWebScraper
IronWebscraper 提供了一個強大的框架,可透過 C# 程式碼從網站中擷取資料和檔案。


只需撰寫一個 C# 網頁抓取類別,即可將數千甚至數百萬個網頁抓取為 C# 類別實例、JSON 或下載檔案。IronWebScraper 讓您能編寫簡潔、線性的工作流程,模擬人類的瀏覽行為。IronWebScraper 將以虛擬網頁瀏覽器群組的形式執行您的程式碼,實現大規模平行處理,同時保持禮貌且具備容錯能力。
開始使用文件
IronWebScraper 必須透過程式設計來掌握如何處理所遇到的每種「類型」的網頁。這可透過 CSS 選擇器或 XPath 表達式以極簡潔的方式實現,並能使用 C# 進行完全自訂。這種自由度讓您能夠決定要在網站內抓取哪些頁面,以及如何處理所提取的資料。每個方法皆可在 Visual Studio 中進行整潔的除錯與監看。
觀看教學指南
IronWebscraper 透過多執行緒與網頁請求機制,可支援數百個並行執行緒,開發人員無需自行管理。可設定請求頻率限制,以降低目標網頁伺服器承受過大負載的風險。
WEBSCRAPER 快速入門
IronWebscraper 可使用一個或多個「身分」——這些身分是模擬真實人類請求的會話。每個請求可透過程式設計或隨機方式,分配其專屬的身分、使用者代理程式、Cookie、登入資訊,甚至 IP 位址。請求會根據 URL、解析方法及 POST 變數的組合,設定為自動產生唯一值。
See API Reference
IronWebscraper 採用先進的快取技術,讓開發人員能夠「即時」修改程式碼,並在不連線至網際網路的情況下重播所有先前請求。每個抓取任務都會自動儲存,即使發生異常或停電,也能繼續執行。
WEBSCRAPER 設定說明
IronWebscraper 透過 Visual Studio 安裝程式,讓您能快速掌握網頁抓取工具。無論是直接從 Visual Studio 內的 NuGet 安裝,還是下載 DLL 檔案,您都能在短時間內完成設定。僅需一個 DLL 檔案,無需任何依賴項。
PM > Install-Package IronWebscraper 下載 DLL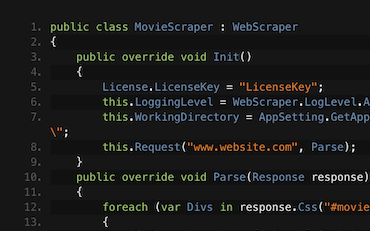
VB C# ASP.NET
了解 Ahmed 如何在專案中運用 IronWebScraper,將內容從一個網站遷移至另一個網站。提供用於抓取電子商務和部落格網站的範例專案與程式碼
 查看 Ahmed 的 WebScraping 教學
查看 Ahmed 的 WebScraping 教學





Iron 團隊在 .NET 軟體元件市場擁有超過 10 年的經驗。

想要快速證明? PM > Install-Package IronWebScraper
執行範例 觀看您的目標網站成為結構化資料。
Install-Package IronWebScraper

無需信用卡
您的試用密鑰應該在電子郵件裡。![]() 試用表單已提交
試用表單已提交
成功。
如果沒有,請聯繫
support@ironsoftware.com
在生產環境中測試,無浮水印。
無論您在哪裡需要,它都能運作。
立即獲取 30 天完整功能版產品。
幾分鐘內即可完成安裝並開始使用。
在產品試用期間,您可隨時聯繫我們的技術支援團隊
我們產品及其關鍵功能的即時示範
獲取專案特定的功能建議
我們已為您解答所有疑問,確保您獲得所需的所有資訊。(完全無需承擔任何義務。)





預約無需承諾的諮詢

預訂 30 分鐘的個人演示。
無須合約、無須卡號、無任何長期綁約。



