

Scraping de un sitio web de películas en línea usando C# y IronWebScraper
IronWebScraper extrae datos de películas de sitios web analizando elementos HTML, creando objetos tipados para el almacenamiento de datos estructurados y navegando entre páginas usando metadata para construir conjuntos de datos de información completa sobre películas. Esta biblioteca C# Web Scraper simplifica la conversión de contenido web no estructurado en datos organizados y analizables.
Inicio rápido: Extraer películas en C#
- Instala
IronWebScrapera través del Administrador de Paquetes NuGet - Crea una clase que herede de ``
- Sobrescribe `` para establecer la licencia y solicitar la URL objetivo
- Sobrescribe `` para extraer datos de películas usando selectores CSS
- Utiliza el método `` para guardar datos en formato JSON
-
Instala IronWebScraper con el Administrador de Paquetes NuGet
PM > Install-Package IronWebScraper -
Copie y ejecute este fragmento de código.
using IronWebScraper; using System; public class QuickstartMovieScraper : WebScraper { public override void Init() { // Set your license key License.LicenseKey = "YOUR-LICENSE-KEY"; // Configure scraper settings this.LoggingLevel = LogLevel.All; this.WorkingDirectory = @"C:\MovieData\Output\"; // Start scraping from the homepage this.Request("https://example-movie-site.com", Parse); } public override void Parse(Response response) { // Extract movie titles using CSS selectors foreach (var movieDiv in response.Css(".movie-item")) { var title = movieDiv.Css("h2")[0].TextContentClean; var url = movieDiv.Css("a")[0].Attributes["href"]; // Save the scraped data Scrape(new { Title = title, Url = url }, "movies.json"); } } } // Run the scraper var scraper = new QuickstartMovieScraper(); scraper.Start(); -
Despliegue para probar en su entorno real
Comienza a usar IronWebScraper en tu proyecto hoy mismo con una prueba gratuita

¿Cómo configuro una clase de Movie Scraper?
Comience con un ejemplo de sitio web del mundo real. Para ello, utilizaremos las técnicas descritas en nuestro tutorial Webscraping en C#.
Agrega una nueva clase y nómbrela ``:

La creación de una clase dedicada al scraper ayuda a organizar el código y lo hace reutilizable. Este enfoque sigue los principios orientados a objetos y permite ampliar fácilmente la funcionalidad más adelante.
¿Cómo es la estructura del sitio web de destino?
Examinar la estructura del sitio para detectar posibles raspaduras. Comprender la estructura del sitio web es crucial para que el web scraping sea eficaz. Al igual que en nuestra guía sobre Scraping de un sitio web de películas, analiza primero la estructura HTML:
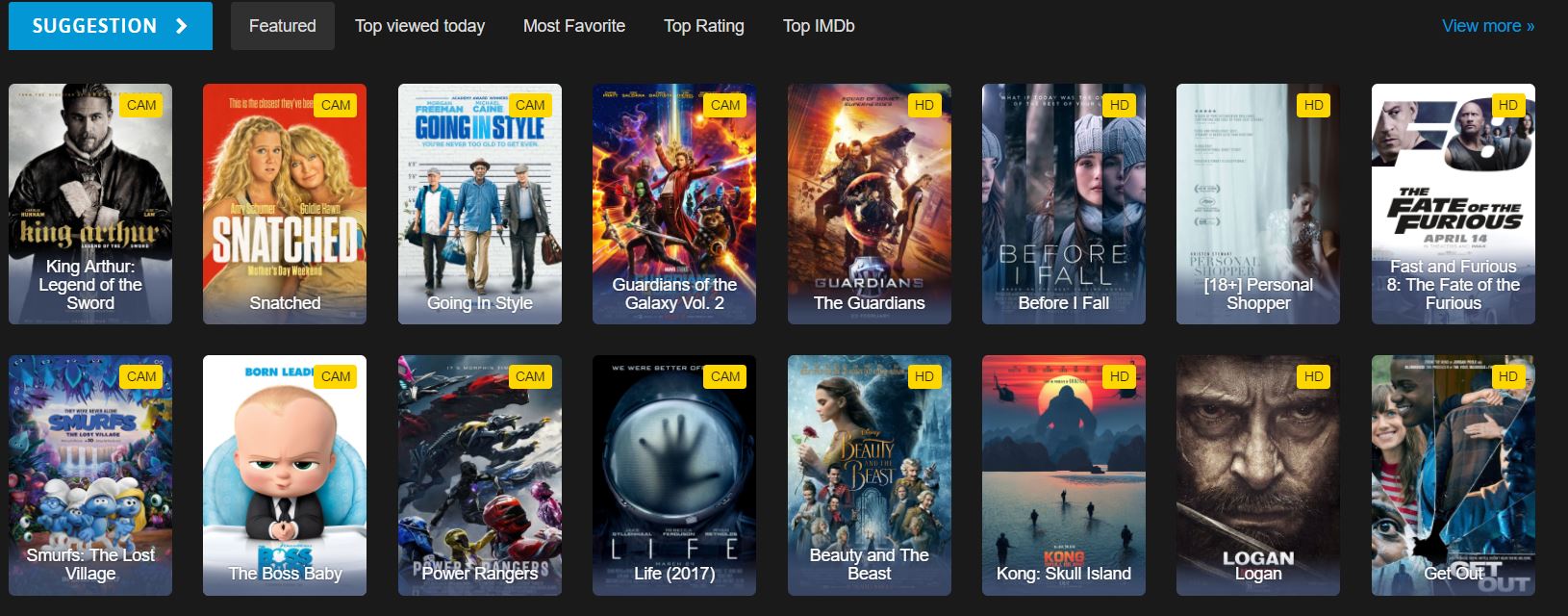
¿Qué elementos HTML contienen datos de películas?
Esto forma parte del HTML de la página de inicio que vemos en el sitio web. Examinar la estructura HTML ayuda a identificar los selectores CSS correctos que hay que utilizar:
<div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div><div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div>Tenemos un ID de película, un título y un enlace a una página detallada. Cada película está contenida dentro de un elemento con la clase e incluye un atributo único `` para identificación.
¿Cómo implemento el Movie Scraping básico?
Empieza a recopilar este conjunto de datos. Antes de ejecutar cualquier scraper, asegúrese de haber configurado correctamente su clave de licencia como se muestra a continuación:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("www.website.com", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"))
Dim link = div.Css("a")(0)
Dim movieTitle = link.TextContentClean
' Scrape and store movie data as key-value pairs
Scrape(New ScrapedData() From {
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
},
"Movie.Jsonl")
End If
Next div
End Sub
End Class¿Para qué sirve la propiedad Directorio de trabajo?
¿Qué hay de nuevo en este código?
La propiedad Working Directory establece el directorio de trabajo principal para todos los datos raspados y archivos relacionados. Esto garantiza que todos los archivos de salida estén organizados en una única ubicación, lo que facilita la gestión de proyectos de scraping a gran escala. El directorio se creará automáticamente si no existe.
¿Cuándo debo usar selectores CSS en lugar de atributos?
Consideraciones adicionales:
Los selectores CSS son ideales para seleccionar elementos por su posición estructural o nombres de clase, mientras que el acceso directo a atributos es mejor para extraer valores específicos como ID o atributos de datos personalizados. En nuestro ejemplo, utilizamos selectores CSS (#movie-featured > div) para navegar la estructura DOM y atributos (``) para extraer valores específicos.
¿Cómo crear objetos tipificados para datos raspados?
Construir objetos tipados para contener datos raspados en objetos formateados. El uso de objetos fuertemente tipados proporciona una mejor organización del código, compatibilidad con IntelliSense y comprobación de tipos en tiempo de compilación.
Implementa una clase `` que contendrá datos formateados:
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
End Class¿Cómo mejora la organización de datos el uso de objetos tipados?
Actualiza el código para usar la clase tipada en lugar de el diccionario genérico:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://website.com/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Scrape and store movie object
Scrape(movie, "Movie.Jsonl")
End If
Next div
End Sub
End Class¿Qué formato utiliza el método Scrape para los objetos tipados?
¿Qué hay de nuevo?
- Implementamos una clase `` para contener datos raspados, proporcionando seguridad de tipo y mejor organización del código.
- Pasamos objetos de películas al método `` que entiende nuestro formato y lo guarda de una manera definida como se muestra a continuación:

El resultado se serializa automáticamente en formato JSON, lo que facilita su importación a bases de datos u otras aplicaciones.
¿Cómo raspar páginas detalladas de películas?
Empezar a raspar páginas más detalladas. El scraping multipágina es un requisito común, e IronWebScraper lo hace sencillo gracias a su mecanismo de encadenamiento de peticiones.
¿Qué datos adicionales puedo extraer de las páginas detalladas?
La página de películas tiene este aspecto y contiene metadatos detallados sobre cada película:

<div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div><div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>¿Cómo debo extender mi clase de película para obtener propiedades adicionales?
Extiende la clase con nuevas propiedades (, ,, ,, ,IMDb Score) pero usa solo, , y para este ejemplo. Usar `` para géneros y actores permite manejar múltiples valores de manera elegante:
using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}Imports System.Collections.Generic
Public Class Movie
Public Property Id() As Integer
Public Property Title() As String
Public Property URL() As String
Public Property Description() As String
Public Property Genre() As List(Of String)
Public Property Actor() As List(Of String)
End Class¿Cómo navego entre páginas mientras hago scraping?
Navegue hasta la página detallada para rasparla. IronWebScraper maneja automáticamente la seguridad de threads, permitiendo que múltiples páginas sean procesadas concurrentemente.
¿Por qué utilizar varias funciones de análisis para distintos tipos de páginas?
IronWebScraper permite añadir múltiples funciones de scrape para manejar diferentes formatos de página. Esta separación de preocupaciones hace que su código sea más fácil de mantener y permite un manejo adecuado de las diferentes estructuras de página. Cada función de análisis sintáctico puede centrarse en la extracción de datos de un tipo de página específico.
¿Cómo ayudan los metadatos a pasar objetos entre funciones de análisis?
La característica MetaData es crucial para mantener el estado entre solicitudes. Para obtener más información sobre características avanzadas de webscraping, consulta nuestra guía detallada:
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://domain/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Request detailed page
Me.Request(movie.URL, AddressOf ParseDetails, New MetaData() From {
{ "movie", movie }
})
End If
Next div
End Sub
Public Sub ParseDetails(ByVal response As Response)
' Retrieve movie object from metadata
Dim movie = response.MetaData.Get(Of Movie)("movie")
Dim div = response.Css("div.mvic-desc")(0)
' Extract description
movie.Description = div.Css("div.desc")(0).TextContentClean
' Extract genres
movie.Genre = New List(Of String)() ' Initialize genre list
For Each genre In div.Css("div > p > a")
movie.Genre.Add(genre.TextContentClean)
Next genre
' Extract actors
movie.Actor = New List(Of String)() ' Initialize actor list
For Each actor In div.Css("div > p:nth-child(2) > a")
movie.Actor.Add(actor.TextContentClean)
Next actor
' Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl")
End Sub
End Class¿Cuáles son las principales características de este método de raspado multipágina?
¿Qué hay de nuevo?
- Agrega funciones de raspado (por ejemplo, ``) para raspar páginas detalladas, similar a las técnicas utilizadas al raspar de un sitio web de compras.
- Mueve la función `` que genera archivos a la nueva función, asegurando que los datos se guarden solo después de que se recojan todos los detalles.
- Usa la función IronWebScraper (``) para pasar objetos de películas a nuevas funciones de raspado, manteniendo el estado del objeto entre solicitudes.
- Raspe páginas y guarde datos de objetos de películas en archivos con información completa.

Para obtener más información sobre los métodos y propiedades disponibles, consulte la Referencia API. IronWebScraper proporciona un marco sólido para extraer datos estructurados de sitios web, lo que lo convierte en una herramienta esencial para proyectos de recopilación y análisis de datos.
Preguntas Frecuentes
¿Cómo extraigo títulos de películas de HTML utilizando C#?
IronWebScraper proporciona métodos de selección CSS para extraer títulos de películas de HTML. Utilice el método response.Css() con selectores apropiados como '.movie-item h2' para seleccionar elementos de título y, a continuación, acceda a la propiedad TextContentClean para obtener el valor de texto limpio.
¿Cuál es la mejor manera de navegar entre varias páginas de películas?
IronWebScraper maneja la navegación de páginas a través del método Request(). Puede extraer enlaces de paginación utilizando selectores CSS y, a continuación, llamar a Request() con cada URL para raspar datos de varias páginas, construyendo automáticamente completos conjuntos de datos de películas.
¿Cómo puedo guardar los datos de las películas en un formato estructurado?
Utilice el método Scrape() de IronWebScraper para guardar datos en formato JSON. Cree objetos anónimos o clases tipificadas que contengan propiedades de películas como el título, la URL y la calificación y, a continuación, páselos a Scrape() junto con un nombre de archivo para serializar y guardar automáticamente los datos.
¿Qué selectores CSS debo utilizar para extraer la información de la película?
IronWebScraper admite selectores CSS estándar. Para sitios web de películas, utilice selectores como '.movie-item' para contenedores, 'h2' para títulos, 'a[href]' para enlaces y nombres de clase específicos para clasificaciones o géneros. El método Css() devuelve colecciones que puedes recorrer.
¿Cómo se gestionan los indicadores de calidad de las películas como "CAM" en los datos raspados?
IronWebScraper permite extraer y procesar indicadores de calidad dirigiéndose a sus elementos HTML específicos. Utilice selectores CSS para localizar los indicadores de calidad o el texto y, a continuación, inclúyalos como propiedades en sus objetos de datos raspados para obtener información cinematográfica completa.
¿Puedo configurar el registro de mis operaciones de movie scraping?
Sí, IronWebScraper incluye funcionalidad de registro integrada. Establezca la propiedad LoggingLevel en LogLevel.All en su método Init() para realizar un seguimiento de todas las actividades de raspado, los errores y el progreso, lo que ayuda a depurar y supervisar la extracción de datos de la película.
¿Cuál es la forma correcta de configurar los directorios de trabajo para los datos raspados?
IronWebScraper le permite establecer una propiedad WorkingDirectory en el método Init(). Especifique una ruta como 'C:\MovieData\Output\' donde se guardarán los archivos de datos de películas raspadas. Esto centraliza la gestión de salida y mantiene sus datos organizados.
¿Cómo heredo correctamente de la clase WebScraper?
Cree una nueva clase que herede de la clase base WebScraper de IronWebScraper. Anule el método Init() para la configuración y el método Parse() para la lógica de extracción de datos. Este enfoque orientado a objetos hace que su raspador de películas sea reutilizable y mantenible.


¿Aún desplazándote?
¿Quieres una prueba rápida? PM > Install-Package IronWebScraper
ejecuta una muestra observa cómo tu sitio de destino se convierte en datos estructurados.










