

Probar en un entorno en vivo
Probar en producción sin marcas de agua.
Funciona donde lo necesites.

30DAYFREE
using IronWebScraper;
public class Program
{
private static void Main(string[] args)
{
var ScrapeJob = new BlogScraper();
ScrapeJob.Start();
}
}
public class BlogScraper : WebScraper
{
public override void Init()
{
LoggingLevel = LogLevel.All;
Request("https://www.zyte.com/blog/", Parse);
}
public override void Parse(Response response)
{
foreach (HtmlNode title_link in response.Css(".oxy-post-title"))
{
string strTitle = title_link.TextContentClean;
Scrape(new ScrapedData() { { "Title", strTitle } });
}
if (response.CssExists("div.oxy-easy-posts-pages > a[href]"))
{
string next_page = response.Css("div.oxy-easy-posts-pages > a[href]")[0].Attributes["href"];
Request(next_page, Parse);
}
}
}Install-Package IronWebScraper
Diseñado para C#, F#, y VB.NET funcionando en .NET 10, 9, 8, 7, 6, 5, Core, Standard, o Framework

")
")
")
")
")
")
")
")
")
")
")
")
")
")
using IronWebScraper;
public class Program
{
private static void Main(string[] args)
{
var ScrapeJob = new BlogScraper();
ScrapeJob.Start();
}
}
public class BlogScraper : WebScraper
{
public override void Init()
{
LoggingLevel = LogLevel.All;
Request("https://www.zyte.com/blog/", Parse);
}
public override void Parse(Response response)
{
foreach (HtmlNode title_link in response.Css(".oxy-post-title"))
{
string strTitle = title_link.TextContentClean;
Scrape(new ScrapedData() { { "Title", strTitle } });
}
if (response.CssExists("div.oxy-easy-posts-pages > a[href]"))
{
string next_page = response.Css("div.oxy-easy-posts-pages > a[href]")[0].Attributes["href"];
Request(next_page, Parse);
}
}
}Imports IronWebScraper
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim ScrapeJob = New BlogScraper()
ScrapeJob.Start()
End Sub
End Class
Public Class BlogScraper
Inherits WebScraper
Public Overrides Sub Init()
LoggingLevel = LogLevel.All
Request("https://www.zyte.com/blog/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each title_link As HtmlNode In response.Css(".oxy-post-title")
Dim strTitle As String = title_link.TextContentClean
Scrape(New ScrapedData() From {
{ "Title", strTitle }
})
Next title_link
If response.CssExists("div.oxy-easy-posts-pages > a[href]") Then
Dim next_page As String = response.Css("div.oxy-easy-posts-pages > a[href]")(0).Attributes("href")
Request(next_page, AddressOf Parse)
End If
End Sub
End ClassInstall-Package IronWebScraper
IronWebScraper proporciona un potente framework para extraer datos y archivos de sitios web usando C#.
WebScraper.Init que utilice el método Request para analizar al menos una URL.Parse para procesar las solicitudes, y de hecho Request más páginas. Usa response.Css para trabajar con elementos HTML utilizando selectores CSS al estilo jQuery.Start();.Descubra cómo extraer datos de sitios web de películas en línea con C#

Ya sean consultas sobre productos, integración o licencias, el equipo de desarrollo de productos Iron está disponible para apoyar todas tus preguntas. Ponerse en contacto y comenzar un diálogo con Iron para aprovechar al máximo nuestra biblioteca en tu proyecto.
Hacer una pregunta
Solo escribe una única clase de web scraper en C# para raspar miles o incluso millones de páginas web en instancias de clase C#, JSON o archivos descargados. IronWebScraper te permite codificar flujos de trabajo concisos y lineales que simulan el comportamiento de navegación humano. IronWebScraper ejecutará tu código como un enjambre de navegadores web virtuales, masivamente en paralelo, pero cortés y tolerante a fallas.
Comienza con la documentación
IronWebScraper debe programarse para saber cómo manejar cada "tipo" de página que encuentra. Esto se logra de manera muy concisa utilizando selectores CSS o expresiones XPath y puede personalizarse completamente en C#. Esta libertad te permite decidir qué páginas raspar dentro de un sitio web y qué hacer con los datos extraídos. Cada método puede depurarse y observarse ordenadamente en Visual Studio.
Sigue un tutorial
IronWebScraper maneja el multihilo y las solicitudes web para permitir cientos de hilos concurrentes sin que el desarrollador necesite gestionarlos. Se puede establecer la cortesía para limitar las solicitudes, reduciendo así el riesgo de carga excesiva en los servidores web de destino.
Puesta en marcha con WebScraper
IronWebScraper puede usar una o múltiples "identidades" - sesiones que simulan solicitudes humanas del mundo real. Cada solicitud puede asignar programáticamente o aleatoriamente su propia Identidad, Agente de Usuario, Cookies, Inicios de Sesión e incluso direcciones IP. Las solicitudes se configuran como autouni que con una combinación de URL, método de análisis y variables post.
See API Reference
IronWebScraper utiliza almacenamiento en caché avanzado para permitir a los desarrolladores cambiar su código "sobre la marcha" y repetir cada solicitud anterior sin contactar con internet. Cada trabajo de raspado se guarda automáticamente y puede reanudarse en caso de una excepción o un corte de energía.
Instrucciones de configuración de WebScraper
IronWebScraper pone las herramientas de Web Scraping en tus propias manos rápidamente con un instalador de Visual Studio. Ya sea instalando directamente desde NuGet dentro de Visual Studio o descargando el DLL, estarás configurado en poco tiempo. Solo un DLL y sin dependencias.
PM > Install-Package IronWebScraper Descargar DLL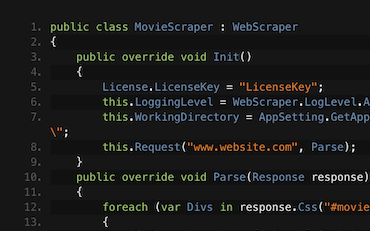
VB C# ASP.NET
Ve cómo Ahmed utiliza IronWebScraper en sus proyectos para migrar contenido de un sitio a otro. Proyectos de muestra y código proporcionados para raspar sitios de ecommerce y blogs
 Ver el Tutorial de WebScraping de Ahmed
Ver el Tutorial de WebScraping de Ahmed





El equipo de Iron tiene más de 10 años de experiencia en el mercado de componentes de software .NET.

¿Quieres una prueba rápida? PM > Install-Package IronWebScraper
ejecuta una muestra observa cómo tu sitio de destino se convierte en datos estructurados.
Install-Package IronWebScraper

No se requiere tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba fue enviado
El formulario de prueba fue enviado
con éxito.
Si no es así, por favor contacte
support@ironsoftware.com
No se requiere tarjeta de crédito
Probar en producción sin marcas de agua.
Funciona donde lo necesites.
Obtén 30 días de producto completamente funcional.
Instálalo y ejecútalo en minutos.
Acceso completo a nuestro equipo de soporte técnico durante tu prueba del producto
Demostración en vivo de nuestro producto y características clave
Recomendaciones de características del proyecto
Se responde a todas sus preguntas para asegurarse de que dispone de toda la información que necesita. (Sin ningún tipo de compromiso)





Reserva una Consulta Sin Compromiso

Completa el formulario a continuación o envía un correo a sales@ironsoftware.com
Tus detalles siempre serán mantenidos confidenciales.

Reserve una demostración personal de 30 minutos.
Sin contrato, sin datos de tarjeta, sin compromisos.


