









ライブ環境でテストする
ウォーターマークなしで本番環境でテスト。
必要な場所で動作します。

using IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR は 125 の国際言語をサポートしています。 デフォルトでインストールされる英語以外に、追加の言語パックを NuGet 経由で .NET プロジェクトに追加したり、言語ページからダウンロードしたりすることもできます。 ほとんどの言語は、高速、標準 (推奨)、最高の品質で利用できます。 最高品質オプションを選択すると、より正確な結果が得られますが、処理時間も遅くなります。IronOCR 言語サポート
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR は、Tesseract 5 を使用してスキャンしたページごとに高度な結果オブジェクトを返します。 これには、位置データ、画像、テキスト、統計的信頼性、代替シンボルの選択肢、フォント名、フォント サイズの装飾、フォントの太さ、それぞれの位置が含まれます。
Page Paragraph Word Barcode 
製品、統合、またはライセンスの問い合わせであろうと、Ironの製品開発チームはすべての質問に対応します。Ironと対話を始め、このライブラリをプロジェクトで最大限に活用してください。
質問をする
パスポートのページ、請求書、銀行取引明細書、メール、名刺、または領収書にかかわらず、光学式文字認識 (OCR) はパターン認識、コンピュータ ビジョン、機械学習に基づく研究分野です。企業は、会計および財務システム、ビジネスのデジタル化、企業コンテンツ管理、データ報告システムでテキストを抽出するために、部門を越えて OCR を活用します。
他の 成功事例の構築に加えて、IronOCR はネイティブ C# OCR ライブラリである IronOCR を用いて、Google Tesseract と 2021 年 Microsoft Azure 認知サービスに付加価値を加えます。
実世界の画像を 99% の精度で変換したい場合は、IronOCR がどのようにして効率的で正確でスケーラブルでほぼ人間に見える光学文字認識アプリケーションを構築できるかをご覧ください。
光学文字認識 (OCR) は、さまざまな API が保護に対する多大な自信を主張するために、解決された現象と考えられています。しかし、さまざまな製品はしばしば堅苦しく、実世界のアプリケーションでは失敗することがあります。同様に、Tesseract OCR は、機械印刷された高解像度の完全なテキストで動作します。
いいですか?
現実の世界では、常に完全に印刷された手書きのテキストが高解像度で存在するわけではありません。それとは対照的に、回転、傾き、低 DPI、背景ノイズなどのデジタルの不完全性のすべての厄介なものは、IronOCR によって処理され、画像ファイルから手書きテキストを抽出することさえします。99.8 - 100% の精度で検索可能なドキュメントを提供し、Windows、Linux、macOS、Microsoft Azure、AWS、Docker など、クロスプラットフォームのサポートが含まれます - そこに C# 開発者が IronOCR を選択する理由があります。基本的な Tesseract OCR よりも価値を追加することにかかっています。
最高のものを装備しましょう!
上記に加えて、IronOCR は画像ドキュメントを迅速に処理するよう装備しています。それだけでなく、IronOCR API の機能も次のように含まれています:
ネイティブな .dlls や exes のインストールから、1つの真実の情報源に移行します - 単純な C# API を使用して、単一のネイティブ .NET コンポーネントライブラリを使用して開発します。対応するもの:
IronOCR API の技術的優位性はそれで終わらず、機能をさらに探索し続けることができます。私たちはビジネスの複雑さを一歩一歩削減し、ドキュメント処理アプリケーションを迅速化し、優れた機能を組み込むことでビジネス収益を最大化します:
私たちの光学式文字認識プロセスは、自動画像前処理から始まり、イメージ ファイルを強化し、抽出応答率を改善します。IronOCR は、例ベースのイメージファイルを最適なバージョンに変換することにより、あなたの作業に価値を追加します。IronOCR はすべての基盤をカバーします:
IronOCR サービスは主に 300DPI(ドット/インチ)の画像ファイルでうまく機能するため、200-300 DPI の目標範囲にフィットするように、著しく範囲外の画像が再サンプリングされます。
これは、600 DPI 画像を 300 DPI にダウンサンプリングして翻訳するのではなく、自信を持って 100 DPI 画像を 200 DPI にアップサンプリングすることを意味します。
IronOCR コグニティブ サービスはモノクローム画像で機能するように設計されているため、色情報やグレースケールの画像は適応型バイナリゼーションアルゴリズムを利用してモノクロに変換されます。
アルゴリズムは、エリア内のピクセルの密度を比較してピクセルをモノクロームに変換するために使用する閾値を決定します。
IronOCR は、テキストの行と文字のパターンを探して、入力画像リソースを希望の方向に自動的にデスクビューイングおよび回転させます。
IronOCR を使用すると、画像ファイルはノイズの存在と量について自動的に分析されます。ノイズは基本的にスキャンされた画像に見られる「斑点」です。私たちの適応アルゴリズムは、ノイズの粒子のサイズに基づいてノイズを除去します。
サンプル イメージファイルが前処理され次第、IronOCR は入力画像ファイルをさまざまな処理ゾーンに分割します。
もうひとつの前準備段階には、参照画像をさまざまな論理ゾーンに分割することが含まれます。IronOCR は最初に、ホワイトスペースやパターンを使用して、画像内のテキストと画像を位置特定し、テキスト領域を画像から分離します。
それがその後、ゾーン - 段落、カラム、およびテキストブロックに分けられます。テキスト認識中に無視されるべき画像と残りの非テキストピクセルは、スマート出力に含められます。その後 IronOCR が、テキストゾーンを表としてグリッドラインとテキストブロックでフラグします。
ユーザーが検索できる単行テキストスレッドを、ピクセルブロブの多段階の、相互接続されたプロセスを行います。これには、文字分割、適応的分類、辞書参照、および関連するプロセスが含まれ、最適な抽出テキストに寄与します。
IronOCR API サービスを使用すると、複数の国際言語のワードレベル、シンボルの精度、マイクロソフトオフィス形式におけるレイアウト保留を含む、複数のデータファイル例の中で私たちのツールをテストしました。いくつかのパラメーターは自動でテストされますが、他のものには視覚チェックが含まれます。
IronOCR により、プレーンテキスト文字列に複数の入力形式でクロスプラットフォームの OCR 機能を追加できます。IronOCR で生産性を高めるために、自由に使用できる チュートリアルドキュメントから始めて IronOCR を使用する方法をガイドします。私たちの NuGet パッケージインストーラーをダウンロードし、無料トライアルキーで探索するか、24/7 の個人的なサポートに接続します。チームのサイズに関わらず、私たちのライフタイムライセンスでニーズをスケールします。
ライセンスを見る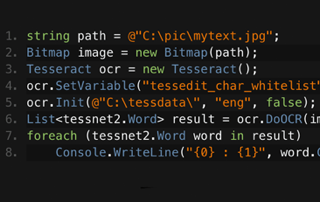
C# Tesseract PDFライセンス

JimはIronOCRの開発において中心的な人物であり、OCRのための画像処理アルゴリズムと読み取り方法を設計し、構築しています。
比較を見る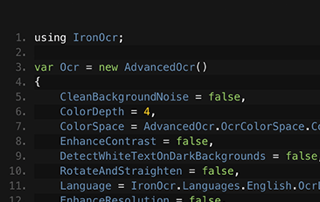
C# PDFライセンス ASP.NET

画像からテキストを読むためにIronOCRを使用するGemmaのチームの方法を学びましょう。Gemmaは自身のコードサンプルを共有しています。
画像からテキストへの .NET チュートリアル




Ironのチームは、.NETソフトウェアコンポーネント市場で10年以上の経験があります。








Install-Package IronOcr
試用キーはメールに届いているはずです。![]() トライアルフォームが正常に
トライアルフォームが正常に
送信されました。
もし届いていない場合は
support@ironsoftware.comにご連絡ください。
ウォーターマークなしで本番環境でテスト。
必要な場所で動作します。
完全に機能する製品を30日間利用できます。
数分でセットアップして稼働します。
製品試用期間中、サポートエンジニアリングチームへのフルアクセス
製品とその主要機能のライブデモをご覧いただけます。
NuGetでインストール
あなたが必要なすべての情報を持っていることを確認するために、すべての質問にお答えします。(コミットメントは一切ありません)。





義務のない相談を予約

下記のフォームを記入するか、sales@ironsoftware.comにメールしてください。
あなたの詳細は常に守秘されます。

30分間の個別デモを予約してください。
契約なし、カード詳細なし、コミットメントなし。


