

How to Scrape Data from Websites in C
IronWebScraper est une bibliothèque .NET destinée au web scraping, à l'extraction de données Web et à l'analyse de contenu Web. Il s'agit d'une bibliothèque facile à utiliser qui peut être ajoutée aux projets Microsoft Visual Studio pour être utilisée en développement et en production.
IronWebScraper dispose de nombreuses fonctionnalités et capacités uniques, telles que le contrôle des pages, objets, médias, etc. autorisés et interdits. Il permet également la gestion de plusieurs identités, du cache Web et de nombreuses autres fonctionnalités que nous aborderons dans ce tutoriel.
Commencez à utiliser IronWebscraper
Commencez à utiliser IronWebScraper dans votre projet aujourd'hui avec un essai gratuit.
Public cible
Ce tutoriel s'adresse aux développeurs de logiciels possédant des compétences en programmation de niveau débutant ou avancé, qui souhaitent créer et mettre en œuvre des solutions offrant des capacités avancées de scraping (scraping de sites web, collecte et extraction de données de sites web, analyse du contenu de sites web, harvesting web).

Compétences requises
- Connaissances de base en programmation et maîtrise d'un des langages de programmation Microsoft tels que C# ou VB.NET
- Connaissances de base des technologies web (HTML, JavaScript, jQuery, CSS, etc.) et de leur fonctionnement
- Connaissances de base en DOM, XPath, HTML et sélecteurs CSS
Outils
- Microsoft Visual Studio 2010 ou version ultérieure
- Extensions de développement web pour navigateurs, telles que Web Inspector pour Chrome ou Firebug pour Firefox
Pourquoi faire du scraping ? (Reasons and Concepts)
Si vous souhaitez créer un produit ou une solution capable de :
- Extraire des données de sites web
- Comparer les contenus, les prix, les fonctionnalités, etc. de plusieurs sites web
- Analyse et mise en cache du contenu des sites web
Si l'une ou plusieurs des raisons ci-dessus s'appliquent à vous, alors IronWebscraper est une excellente bibliothèque qui répondra à vos besoins
Comment installer IronWebscraper ?
Après avoir Create a New Project (voir l'annexe A), vous pouvez ajouter la bibliothèque IronWebScraper à votre projet en l'insérant automatiquement via NuGet ou en installant manuellement la DLL.
Installer via NuGet
Pour ajouter la bibliothèque IronWebScraper à notre projet à l'aide de NuGet, nous pouvons le faire via l'interface graphique (NuGet Package Manager) ou par ligne de commande à l'aide de la Package Manager Console.
Utilisation du Package Manager NuGet
- À l'aide de la souris -> cliquez avec le bouton droit sur le nom du projet -> Sélectionnez " Gérer le package NuGet "
- Dans l'onglet " Parcourir " -> recherchez
IronWebScraper-> Installez - Cliquez sur OK
- Et voilà, c'est terminé
Utilisation de la console de paquets NuGet
- Dans Outils -> Package Manager NuGet -> Console du Package Manager
- Choisir " Class Library Project " comme projet par défaut
- Exécuter la commande ->
Install-Package IronWebScraper
Installer manuellement
- Rendez-vous sur
- Cliquez sur IronWebScraper ou rendez-vous directement sur sa page à l'aide de l'URL https://ironsoftware.com/csharp/webscraper/
- Cliquez sur Télécharger la DLL.
- Décompressez le fichier téléchargé
-
Dans Visual Studio, cliquez avec le bouton droit sur le projet -> Ajouter -> Référence -> Parcourir
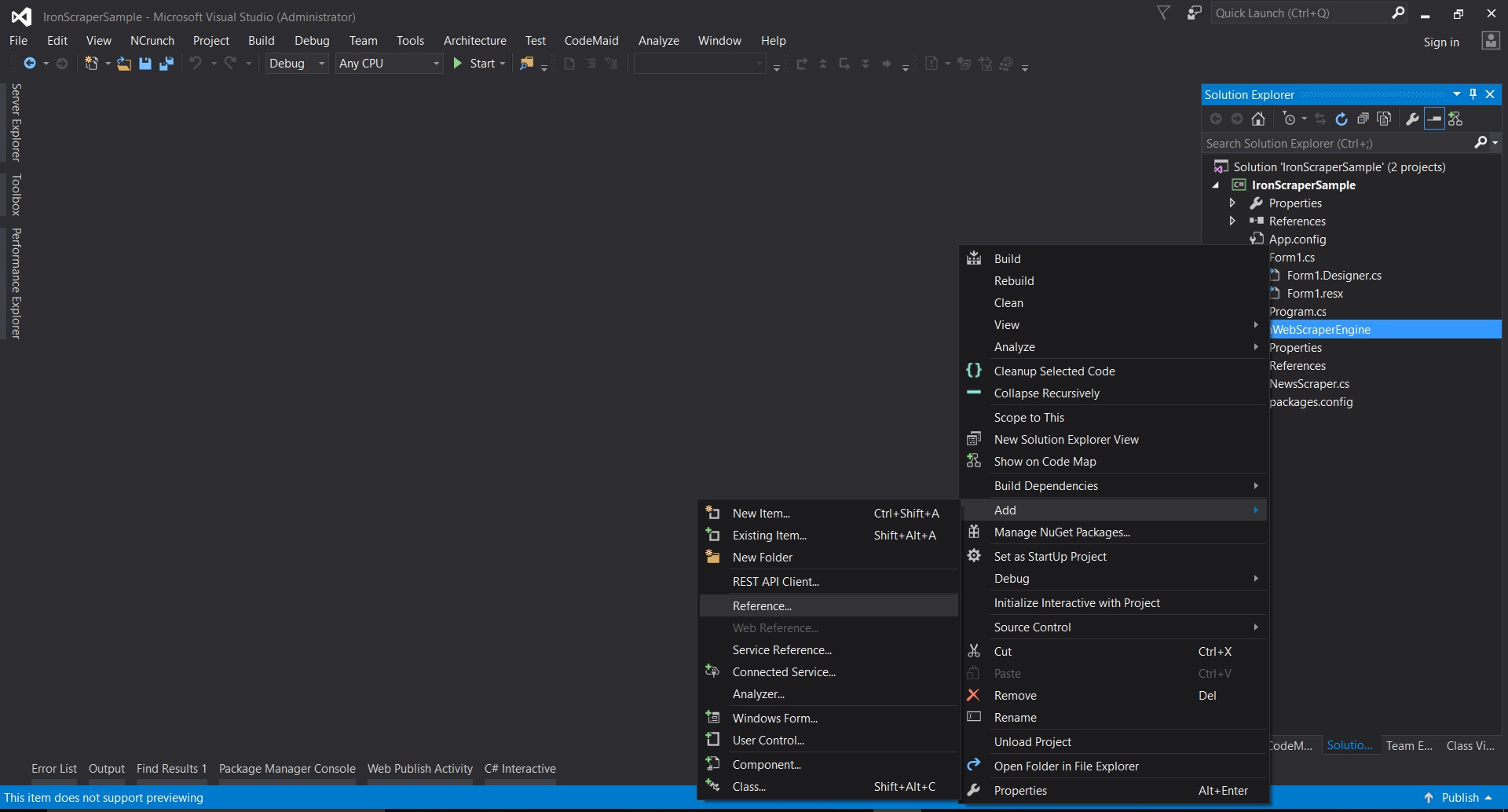
-
Accédez au dossier extrait ->
netstandard2.0-> et sélectionnez tous les fichiers.dll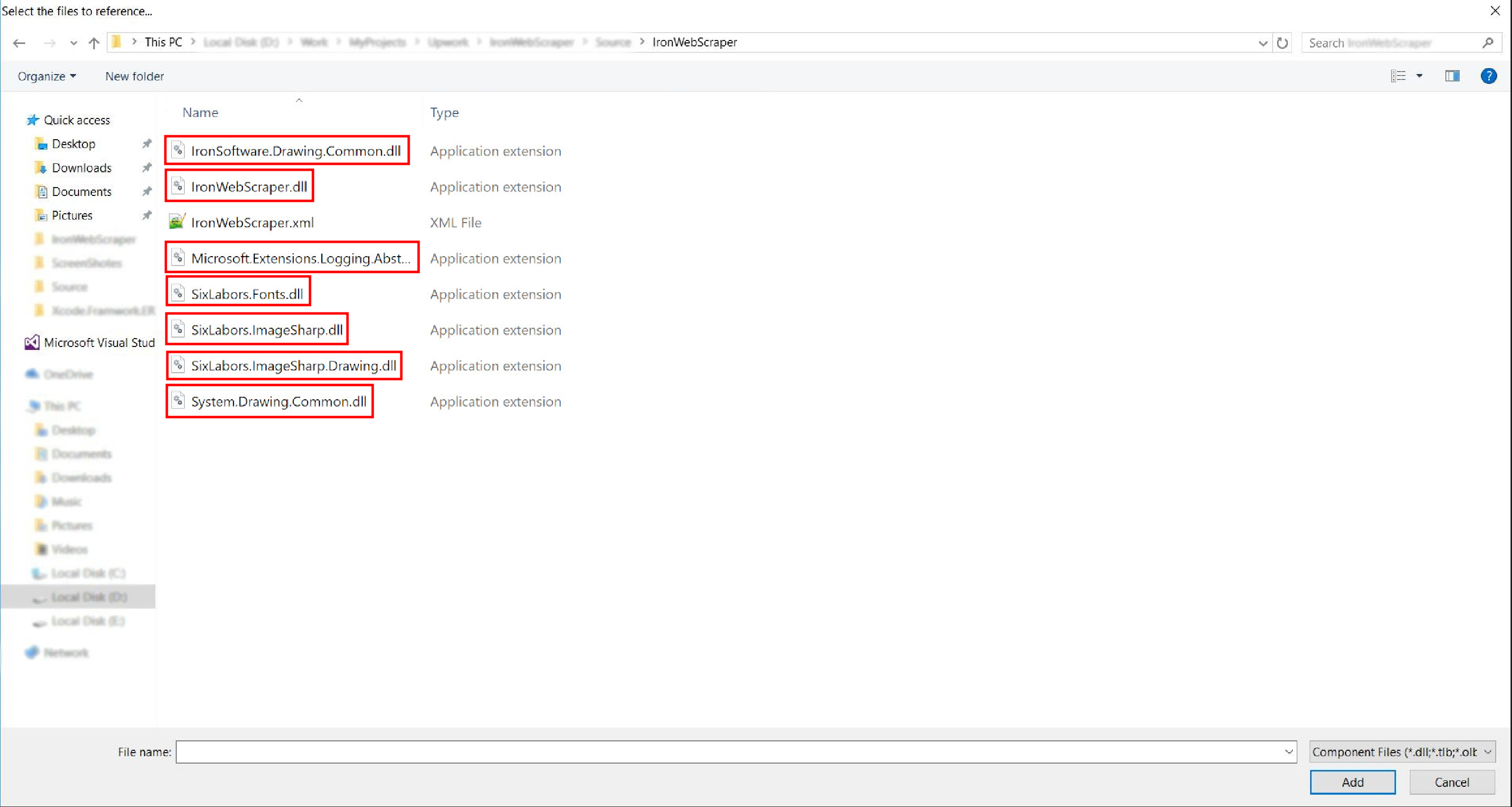
- Et voilà, c'est terminé !
HelloScraper - Notre premier exemple d'IronWebscraper
Comme d'habitude, nous commencerons par implémenter l'application Hello Scraper pour faire nos premiers pas avec IronWebScraper.
- Nous avons créé une nouvelle application console nommée " IronWebScraperSample "
Étapes pour créer un exemple IronWebscraper
- Créez un dossier et nommez-le " HelloScraperSample "
-
Ajoutez ensuite une nouvelle classe et nommez-la
HelloScraper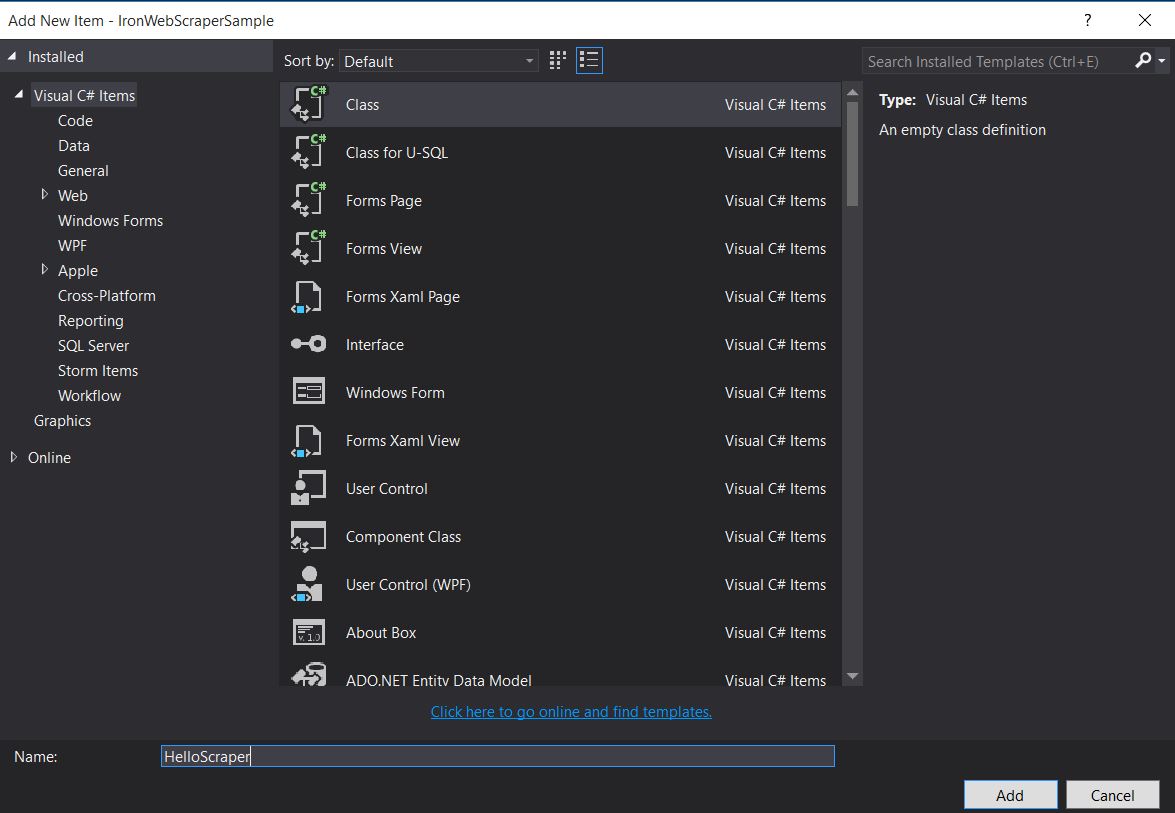
-
Ajoutez cet extrait de code à
HelloScraperpublic class HelloScraper : WebScraper { /// <summary> /// Override this method to initialize your web scraper. /// Important tasks will be to request at least one start URL and set allowed/banned domain or URL patterns. /// </summary> public override void Init() { License.LicenseKey = "LicenseKey"; // Write License Key this.LoggingLevel = WebScraper.LogLevel.All; // Log all events this.Request("https://blog.scrapinghub.com", Parse); // Initialize a web request to the given URL } /// <summary> /// Override this method to create the default Response handler for your web scraper. /// If you have multiple page types, you can add additional similar methods. /// </summary> /// <param name="response">The HTTP Response object to parse</param> public override void Parse(Response response) { // Set working directory for the project this.WorkingDirectory = AppSetting.GetAppRoot() + @"\HelloScraperSample\Output\"; // Loop on all links foreach (var titleLink in response.Css("h2.entry-title a")) { // Read link text string title = titleLink.TextContentClean; // Save result to file Scrape(new ScrapedData() { { "Title", title } }, "HelloScraper.json"); } // Loop on all links for pagination if (response.CssExists("div.prev-post > a[href]")) { // Get next page URL var nextPage = response.Css("div.prev-post > a[href]")[0].Attributes["href"]; // Scrape next URL this.Request(nextPage, Parse); } } }public class HelloScraper : WebScraper { /// <summary> /// Override this method to initialize your web scraper. /// Important tasks will be to request at least one start URL and set allowed/banned domain or URL patterns. /// </summary> public override void Init() { License.LicenseKey = "LicenseKey"; // Write License Key this.LoggingLevel = WebScraper.LogLevel.All; // Log all events this.Request("https://blog.scrapinghub.com", Parse); // Initialize a web request to the given URL } /// <summary> /// Override this method to create the default Response handler for your web scraper. /// If you have multiple page types, you can add additional similar methods. /// </summary> /// <param name="response">The HTTP Response object to parse</param> public override void Parse(Response response) { // Set working directory for the project this.WorkingDirectory = AppSetting.GetAppRoot() + @"\HelloScraperSample\Output\"; // Loop on all links foreach (var titleLink in response.Css("h2.entry-title a")) { // Read link text string title = titleLink.TextContentClean; // Save result to file Scrape(new ScrapedData() { { "Title", title } }, "HelloScraper.json"); } // Loop on all links for pagination if (response.CssExists("div.prev-post > a[href]")) { // Get next page URL var nextPage = response.Css("div.prev-post > a[href]")[0].Attributes["href"]; // Scrape next URL this.Request(nextPage, Parse); } } }Public Class HelloScraper Inherits WebScraper ''' <summary> ''' Override this method to initialize your web scraper. ''' Important tasks will be to request at least one start URL and set allowed/banned domain or URL patterns. ''' </summary> Public Overrides Sub Init() License.LicenseKey = "LicenseKey" ' Write License Key Me.LoggingLevel = WebScraper.LogLevel.All ' Log all events Me.Request("https://blog.scrapinghub.com", AddressOf Parse) ' Initialize a web request to the given URL End Sub ''' <summary> ''' Override this method to create the default Response handler for your web scraper. ''' If you have multiple page types, you can add additional similar methods. ''' </summary> ''' <param name="response">The HTTP Response object to parse</param> Public Overrides Sub Parse(ByVal response As Response) ' Set working directory for the project Me.WorkingDirectory = AppSetting.GetAppRoot() & "\HelloScraperSample\Output\" ' Loop on all links For Each titleLink In response.Css("h2.entry-title a") ' Read link text Dim title As String = titleLink.TextContentClean ' Save result to file Scrape(New ScrapedData() From { { "Title", title } }, "HelloScraper.json") Next titleLink ' Loop on all links for pagination If response.CssExists("div.prev-post > a[href]") Then ' Get next page URL Dim nextPage = response.Css("div.prev-post > a[href]")(0).Attributes("href") ' Scrape next URL Me.Request(nextPage, AddressOf Parse) End If End Sub End Class$vbLabelText $csharpLabel -
Pour lancer Scrape, ajoutez cet extrait de code à
Mainstatic void Main(string[] args) { // Create Object From Hello Scrape class HelloScraperSample.HelloScraper scrape = new HelloScraperSample.HelloScraper(); // Start Scraping scrape.Start(); }static void Main(string[] args) { // Create Object From Hello Scrape class HelloScraperSample.HelloScraper scrape = new HelloScraperSample.HelloScraper(); // Start Scraping scrape.Start(); }Shared Sub Main(ByVal args() As String) ' Create Object From Hello Scrape class Dim scrape As New HelloScraperSample.HelloScraper() ' Start Scraping scrape.Start() End Sub$vbLabelText $csharpLabel - Le résultat sera enregistré dans un fichier au format
WebScraper.WorkingDirectory/classname.Json
Aperçu du code
Scrape.Start() déclenche la logique de scraping comme suit :
- Appelle la méthode
Init()pour initialiser des variables, extraire des propriétés et des attributs de comportement. - Définit la requête de la page d'accueil dans
Init()avecRequest("https://blog.scrapinghub.com", Parse). - Gère plusieurs requêtes HTTP et threads en parallèle, ce qui permet de conserver la synchronisation du code et facilite le débogage.
- La méthode
Parse()est déclenchée aprèsInit()pour traiter la réponse, en extrayant les données à l'aide de sélecteurs CSS et en les enregistrant au format JSON.
Fonctions et options de la bibliothèque IronWebscraper
La documentation mise à jour se trouve dans le fichier ZIP téléchargé via la méthode d'installation manuelle (IronWebScraper Documentation.chm File), ou vous pouvez consulter la documentation en ligne pour connaître la dernière mise à jour de la bibliothèque à l'adresse https://ironsoftware.com/csharp/webscraper/object-reference/.
Pour commencer à utiliser IronWebScraper dans votre projet, vous devez hériter de la classe IronWebScraper.WebScraper, qui étend votre bibliothèque de classes et y ajoute des fonctionnalités de scraping. Vous devez également implémenter les méthodes Init() et Parse(Response response).
namespace IronWebScraperEngine
{
public class NewsScraper : IronWebScraper.WebScraper
{
public override void Init()
{
throw new NotImplementedException();
}
public override void Parse(Response response)
{
throw new NotImplementedException();
}
}
}namespace IronWebScraperEngine
{
public class NewsScraper : IronWebScraper.WebScraper
{
public override void Init()
{
throw new NotImplementedException();
}
public override void Parse(Response response)
{
throw new NotImplementedException();
}
}
}Namespace IronWebScraperEngine
Public Class NewsScraper
Inherits IronWebScraper.WebScraper
Public Overrides Sub Init()
Throw New NotImplementedException()
End Sub
Public Overrides Sub Parse(ByVal response As Response)
Throw New NotImplementedException()
End Sub
End Class
End Namespace| Propriétés \ fonctions | Type | Description |
|---|---|---|
Init () |
Méthode | Utilisé pour configurer le scraper |
Parse (Response response) |
Méthode | Utilisé pour implémenter la logique que le scraper utilisera et la manière dont il la traitera. Peut mettre en œuvre plusieurs méthodes pour différents comportements ou structures de page. |
BannedUrls, AllowedUrls, BannedDomains |
Collections | Utilisé pour bloquer/autoriser des URL et/ou des domaines. Ex : BannedUrls.Add("*.zip", "*.exe", "*.gz", "*.pdf"); Prend en charge les caractères génériques et les expressions régulières. |
ObeyRobotsDotTxt |
Booléen | Utilisé pour activer ou désactiver la lecture et le respect des directives dans robots.txt. |
ObeyRobotsDotTxtForHost (string Host) |
Méthode | Permet d'activer ou de désactiver la lecture et le respect des directives de robots.txt pour un domaine donné. |
Scrape, ScrapeUnique |
Méthode | |
ThrottleMode |
Énumération | Options d'énumération : ByIpAddress, ByDomainHostName. Permet une limitation intelligente des requêtes, en respectant les adresses IP ou les noms de domaine des hôtes. |
EnableWebCache, EnableWebCache (TimeSpan cacheDuration) |
Méthode | Active la mise en cache pour les requêtes Web. |
MaxHttpConnectionLimit |
Int | Définit le nombre total de requêtes HTTP ouvertes autorisées (threads). |
RateLimitPerHost |
TimeSpan | Définit le délai de courtoisie (pause) minimal entre les requêtes adressées à un domaine ou une adresse IP donné(e). |
OpenConnectionLimitPerHost |
Int | Définit le nombre autorisé de requêtes HTTP simultanées (threads) par nom d'hôte ou adresse IP. |
WorkingDirectory |
string | Définit un chemin d'accès au répertoire de travail pour le stockage des données. |
Exemples concrets et exercices pratiques
Extraction de données d'un site web de films en ligne
Créons un exemple dans lequel nous extrayons des données d'un site web consacré au cinéma.
Ajoutez une nouvelle classe et nommez-la MovieScraper :

Structure HTML
Voici un extrait du code HTML de la page d'accueil que l'on trouve sur le site web :
<div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/" >
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div><div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/" >
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div>Comme on peut le voir, nous avons un identifiant de film, un titre et un lien vers une page détaillée. Commençons à extraire ces données :
public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movieId = div.GetAttribute("data-movie-id");
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
Scrape(new ScrapedData() { { "MovieId", movieId }, { "MovieTitle", movieTitle } }, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movieId = div.GetAttribute("data-movie-id");
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
Scrape(new ScrapedData() { { "MovieId", movieId }, { "MovieTitle", movieTitle } }, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
Me.Request("www.website.com", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each div In response.Css("#movie-featured > div")
If div.GetAttribute("class") <> "clearfix" Then
Dim movieId = div.GetAttribute("data-movie-id")
Dim link = div.Css("a")(0)
Dim movieTitle = link.TextContentClean
Scrape(New ScrapedData() From {
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
},
"Movie.Jsonl")
End If
Next div
End Sub
End ClassClasse Movie structurée
Pour stocker nos données formatées, implémentons une classe Movie :
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
End ClassMettons maintenant à jour notre code pour utiliser la classe Movie :
public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
Scrape(movie, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
Scrape(movie, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
Me.Request("https://website.com/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each div In response.Css("#movie-featured > div")
If div.GetAttribute("class") <> "clearfix" Then
Dim movie As New Movie With {
.Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
.Title = div.Css("a")(0).TextContentClean,
.URL = div.Css("a")(0).Attributes("href")
}
Scrape(movie, "Movie.Jsonl")
End If
Next div
End Sub
End ClassScraping de pages détaillées
Extendons notre classe Movie pour y ajouter de nouvelles propriétés contenant les informations détaillées :
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
Public Property Description As String
Public Property Genre As List(Of String)
Public Property Actor As List(Of String)
End ClassAccédez ensuite à la page détaillée pour la scraper, en utilisant les fonctionnalités avancées d'IronWebScraper :
public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
movie.Description = div.Css("div.desc")[0].TextContentClean;
movie.Genre = div.Css("div > p > a").Select(element => element.TextContentClean).ToList();
movie.Actor = div.Css("div > p:nth-child(2) > a").Select(element => element.TextContentClean).ToList();
Scrape(movie, "Movie.Jsonl");
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.GetAttribute("class") != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
Title = div.Css("a")[0].TextContentClean,
URL = div.Css("a")[0].Attributes["href"]
};
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
movie.Description = div.Css("div.desc")[0].TextContentClean;
movie.Genre = div.Css("div > p > a").Select(element => element.TextContentClean).ToList();
movie.Actor = div.Css("div > p:nth-child(2) > a").Select(element => element.TextContentClean).ToList();
Scrape(movie, "Movie.Jsonl");
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
Me.Request("https://domain/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each div In response.Css("#movie-featured > div")
If div.GetAttribute("class") <> "clearfix" Then
Dim movie As New Movie With {
.Id = Convert.ToInt32(div.GetAttribute("data-movie-id")),
.Title = div.Css("a")(0).TextContentClean,
.URL = div.Css("a")(0).Attributes("href")
}
Me.Request(movie.URL, AddressOf ParseDetails, New MetaData() From {
{ "movie", movie }
})
End If
Next div
End Sub
Public Sub ParseDetails(ByVal response As Response)
Dim movie = response.MetaData.Get(Of Movie)("movie")
Dim div = response.Css("div.mvic-desc")(0)
movie.Description = div.Css("div.desc")(0).TextContentClean
movie.Genre = div.Css("div > p > a").Select(Function(element) element.TextContentClean).ToList()
movie.Actor = div.Css("div > p:nth-child(2) > a").Select(Function(element) element.TextContentClean).ToList()
Scrape(movie, "Movie.Jsonl")
End Sub
End ClassFonctionnalités de la bibliothèque IronWebscraper
Fonctionnalité HttpIdentity
Certains systèmes exigent que l'utilisateur soit connecté pour consulter le contenu ; Utilisez HttpIdentity pour les identifiants :
HttpIdentity id = new HttpIdentity
{
NetworkUsername = "username",
NetworkPassword = "pwd"
};
Identities.Add(id);HttpIdentity id = new HttpIdentity
{
NetworkUsername = "username",
NetworkPassword = "pwd"
};
Identities.Add(id);Dim id As New HttpIdentity With {
.NetworkUsername = "username",
.NetworkPassword = "pwd"
}
Identities.Add(id)Activer le cache Web
Mettre en cache les pages demandées pour les réutiliser pendant le développement :
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
EnableWebCache();
this.Request("http://www.WebSite.com", Parse);
}public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
EnableWebCache();
this.Request("http://www.WebSite.com", Parse);
}Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\ShoppingSiteSample\Output\"
EnableWebCache()
Me.Request("http://www.WebSite.com", Parse)
End SubLimitation
Contrôler les numéros de connexion et la vitesse :
public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
this.MaxHttpConnectionLimit = 80;
this.RateLimitPerHost = TimeSpan.FromMilliseconds(50);
this.OpenConnectionLimitPerHost = 25;
this.ObeyRobotsDotTxt = false;
this.ThrottleMode = Throttle.ByDomainHostName;
this.Request("https://www.Website.com", Parse);
}public override void Init()
{
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\ShoppingSiteSample\Output\";
this.MaxHttpConnectionLimit = 80;
this.RateLimitPerHost = TimeSpan.FromMilliseconds(50);
this.OpenConnectionLimitPerHost = 25;
this.ObeyRobotsDotTxt = false;
this.ThrottleMode = Throttle.ByDomainHostName;
this.Request("https://www.Website.com", Parse);
}Public Overrides Sub Init()
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\ShoppingSiteSample\Output\"
Me.MaxHttpConnectionLimit = 80
Me.RateLimitPerHost = TimeSpan.FromMilliseconds(50)
Me.OpenConnectionLimitPerHost = 25
Me.ObeyRobotsDotTxt = False
Me.ThrottleMode = Throttle.ByDomainHostName
Me.Request("https://www.Website.com", Parse)
End SubPropriétés de limitation
MaxHttpConnectionLimit
nombre total de requêtes HTTP ouvertes autorisées (threads)RateLimitPerHost
délai de courtoisie (pause) minimum entre deux requêtes adressées à un domaine ou une adresse IP donnésOpenConnectionLimitPerHost
nombre autorisé de requêtes HTTP simultanées (threads) par nom d'hôte ou adresse IPThrottleMode
Permet à WEBSCRAPER de limiter intelligemment les requêtes non seulement par nom d'hôte, mais aussi par adresses IP des serveurs hôtes. Ceci est une précaution au cas où plusieurs domaines scrappés seraient hébergés sur la même machine.
Annexe
Comment créer une application Windows Form ?
Utilisez Visual Studio 2013 ou une version ultérieure.
- Ouvrez Visual Studio.
-
Fichier -> Nouveau -> Projet

- Choisissez Visual C# ou VB -> Windows -> Application Windows Forms.
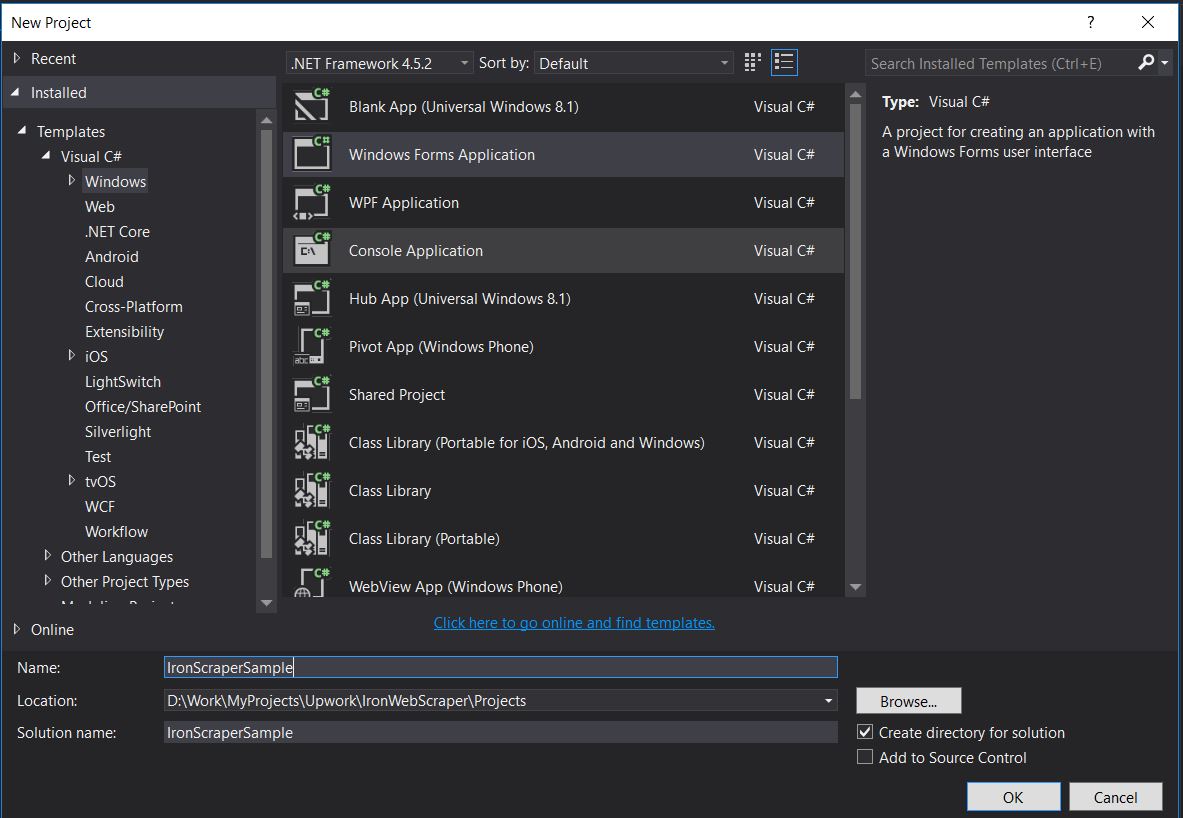
Nom du projet : IronScraperSample
Emplacement : sélectionnez un emplacement sur votre disque.
Comment créer une application Web Form ASP.NET ?
-
Ouvrez Visual Studio.
-
Fichier -> Nouveau -> Projet
- Choisissez Visual C# ou VB -> Web -> Application Web ASP.NET (.NET Framework).
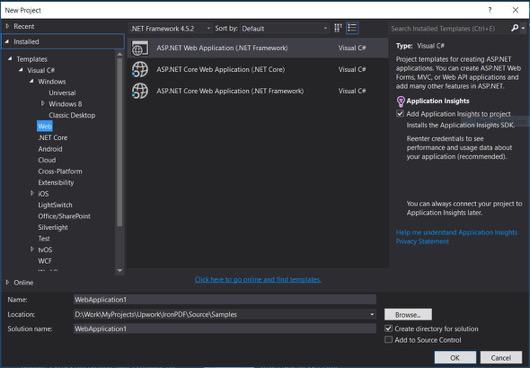
Nom du projet : IronScraperSample
Emplacement : sélectionnez un emplacement sur votre disque.
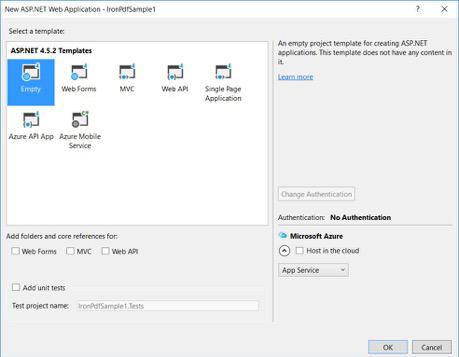
-
Dans vos modèles ASP.NET, sélectionnez un modèle vide et cochez la case Web Forms.
- Votre projet de formulaire Web ASP.NET de base est créé.
Téléchargez ici le code complet du projet d'exemple du tutoriel.
Questions Fréquemment Posées
Comment extraire des données de sites Web en C# ?
Vous pouvez utiliser IronWebScraper pour extraire des données de sites Web en C#. Commencez par installer la bibliothèque via NuGet et configurez une application console de base pour commencer à extraire efficacement les données Web.
Quelles sont les conditions préalables pour le scraping Web en C# ?
Pour effectuer du scraping Web en C#, vous devez avoir des compétences de base en programmation en C# ou VB.NET, comprendre les technologies Web telles que HTML, JavaScript et CSS, ainsi qu'une familiarité avec le DOM, XPath et les sélecteurs CSS.
Comment puis-je installer une bibliothèque de scraping Web dans un projet .NET ?
Pour installer IronWebScraper dans un projet .NET, utilisez la console du gestionnaire de packages NuGet avec la commande Install-Package IronWebScraper ou naviguez à travers l'interface du gestionnaire de packages NuGet dans Visual Studio.
Comment puis-je implémenter la limitation des requêtes dans mon scraper Web ?
IronWebScraper vous permet d'implémenter la limitation des requêtes pour gérer la fréquence des requêtes envoyées à un serveur. Cela peut être configuré en utilisant des paramètres tels que MaxHttpConnectionLimit, RateLimitPerHost et OpenConnectionLimitPerHost.
Quel est le but d'activer la mise en cache Web dans le scraping Web ?
L'activation de la mise en cache Web dans le scraping Web aide à réduire le nombre de requêtes envoyées à un serveur en stockant et réutilisant les réponses précédentes. Cela peut être configuré dans IronWebScraper en utilisant la méthode EnableWebCache.
Comment l'authentification peut-elle être gérée dans le scraping Web ?
Avec IronWebScraper, vous pouvez utiliser HttpIdentity pour gérer l'authentification, permettant l'accès au contenu derrière les formulaires d'identification ou les zones restreintes, autorisant ainsi le scraping de ressources protégées.
Quel est un exemple simple de scraper Web en C# ?
Le 'HelloScraper' est un exemple simple fourni dans le tutoriel. Il démontre la configuration d'un scraper Web de base en utilisant IronWebScraper, y compris comment initier des requêtes et analyser les réponses.
Comment puis-je étendre mon scraper Web pour gérer des structures de pages complexes ?
En utilisant IronWebScraper, vous pouvez étendre votre scraper pour gérer des structures de pages complexes en personnalisant les méthodes Parse pour traiter différents types de pages, permettant des stratégies d'extraction de données flexibles.
Quels sont les avantages d'utiliser une bibliothèque de scraping Web ?
Utiliser une bibliothèque de scraping Web telle qu'IronWebScraper offre des avantages tels que l'extraction de données simplifiée, la gestion de domaine, la limitation des requêtes, la mise en cache, et le support de l'authentification, permettant de gérer efficacement les tâches de scraping Web.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ? PM > Install-Package IronWebScraper
exécuter un échantillon regarder votre site cible devenir des données structurées.










