

Scraping d'un site web de films en ligne à l'aide de C# ; et IronWebScraper
IronWebScraper extrait des données de films de sites web en analysant des éléments HTML, en créant des objets typés pour le stockage de données structurées, et en naviguant entre les pages en utilisant des métadonnées pour constituer des ensembles de données complètes d'informations sur les films. Cette bibliothèque C# Web Scraper simplifie la conversion de contenu web non structuré en données organisées et analysables.
Démarrage rapide : Extraire des films en C#
- Installez
IronWebScrapervia le gestionnaire de packages NuGet - Créez une classe qui hérite de
WebScraper - Redéfinissez
Init()pour définir la licence et demander l'URL cible - Redéfinissez
Parse()pour extraire les données de film en utilisant les sélecteurs CSS - Utilisez la méthode
Scrape()pour enregistrer les données au format JSON
-
Installez IronWebScraper avec le Gestionnaire de Packages NuGet
-
Copiez et exécutez cet extrait de code.
using IronWebScraper; using System; public class QuickstartMovieScraper : WebScraper { public override void Init() { // Set your license key License.LicenseKey = "YOUR-LICENSE-KEY"; // Configure scraper settings this.LoggingLevel = LogLevel.All; this.WorkingDirectory = @"C:\MovieData\Output\"; // Start scraping from the homepage this.Request("https://example-movie-site.com", Parse); } public override void Parse(Response response) { // Extract movie titles using CSS selectors foreach (var movieDiv in response.Css(".movie-item")) { var title = movieDiv.Css("h2")[0].TextContentClean; var url = movieDiv.Css("a")[0].Attributes["href"]; // Save the scraped data Scrape(new { Title = title, Url = url }, "movies.json"); } } } // Run the scraper var scraper = new QuickstartMovieScraper(); scraper.Start(); -
Déployez pour tester sur votre environnement de production.
Commencez à utiliser IronWebScraper dans votre projet dès aujourd'hui avec un essai gratuit

Comment configurer une classe Movie Scraper?
Commencez par un exemple de site web réel. Nous allons gratter un site web de films en utilisant les techniques décrites dans notre tutoriel Webscraping in C#.
Ajoutez une nouvelle classe et nommez-la MovieScraper :

La création d'une classe de scraper dédiée permet d'organiser votre code et de le rendre réutilisable. Cette approche suit les principes de l'orientation objet et vous permet d'étendre facilement les fonctionnalités par la suite.
À quoi ressemble la structure du site web cible?
Examinez la structure du site en vue d'un éventuel "scraping". La compréhension de la structure du site web est cruciale pour un web scraping efficace. Comme dans notre guide sur La récupération à partir d'un site Web de films en ligne, analysez d'abord la structure HTML :
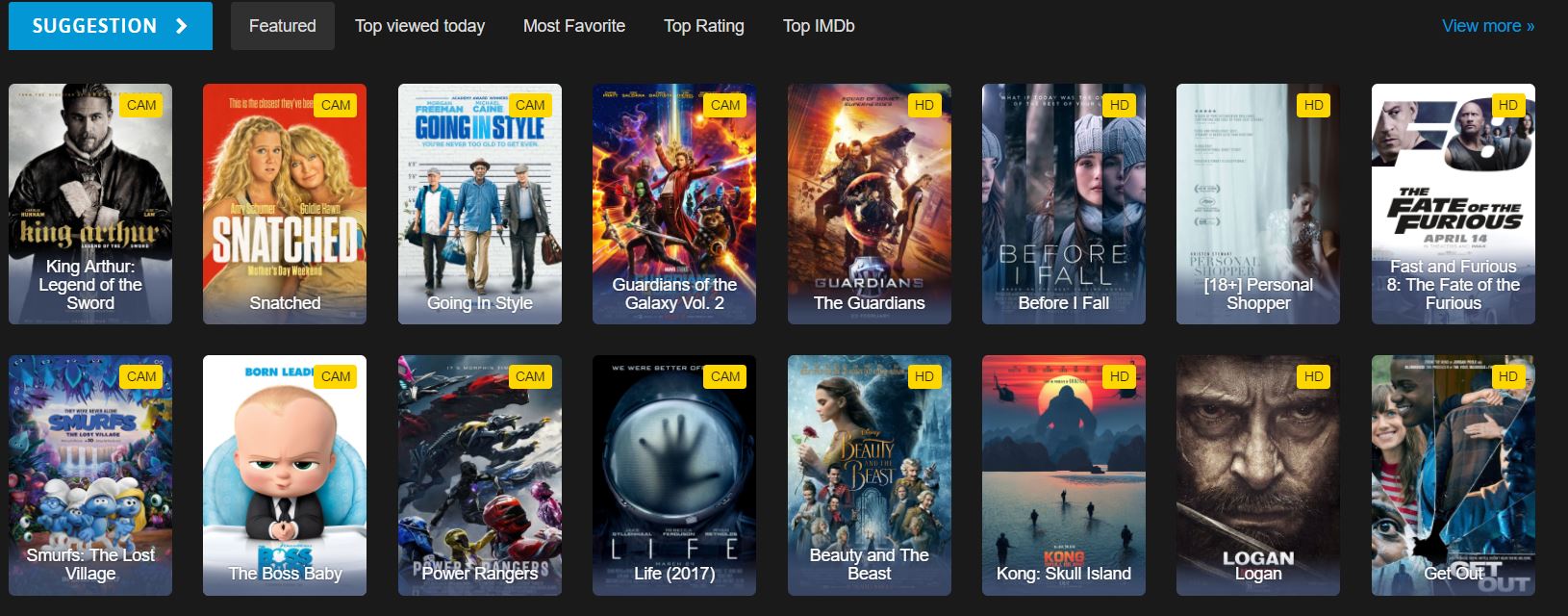
Quels sont les éléments HTML qui contiennent des données sur les films ?
Il s'agit d'une partie de la page d'accueil HTML que nous voyons sur le site web. L'examen de la structure HTML permet d'identifier les sélecteurs CSS à utiliser :
<div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div><div id="movie-featured" class="movies-list movies-list-full tab-pane in fade active">
<div data-movie-id="20746" class="ml-item">
<a href="https://website.com/film/king-arthur-legend-of-the-sword-20746/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
class="lazy thumb mli-thumb" alt="King Arthur: Legend of the Sword"
src="https://img.gocdn.online/2017/05/16/poster/2116d6719c710eabe83b377463230fbe-king-arthur-legend-of-the-sword.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>King Arthur: Legend of the Sword</h2></span>
</a>
</div>
<div data-movie-id="20724" class="ml-item">
<a href="https://website.com/film/snatched-20724/">
<span class="mli-quality">CAM</span>
<img data-original="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
class="lazy thumb mli-thumb" alt="Snatched"
src="https://img.gocdn.online/2017/05/16/poster/5ef66403dc331009bdb5aa37cfe819ba-snatched.jpg"
style="display: inline-block;">
<span class="mli-info"><h2>Snatched</h2></span>
</a>
</div>
</div>Nous disposons d'un identifiant de film, d'un titre et d'un lien vers une page détaillée. Chaque film est contenu dans un élément div avec la classe ml-item et inclut un attribut data-movie-id unique pour identification.
Comment implémenter le scraping de films de base?
Commencez à récupérer cet ensemble de données. Avant d'exécuter un scraper, assurez-vous d'avoir correctement configuré votre clé de licence comme indiqué ci-dessous :
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("www.website.com", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"));
var link = div.Css("a")[0];
var movieTitle = link.TextContentClean;
// Scrape and store movie data as key-value pairs
Scrape(new ScrapedData()
{
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
}, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("www.website.com", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movieId = Convert.ToInt32(div.GetAttribute("data-movie-id"))
Dim link = div.Css("a")(0)
Dim movieTitle = link.TextContentClean
' Scrape and store movie data as key-value pairs
Scrape(New ScrapedData() From {
{ "MovieId", movieId },
{ "MovieTitle", movieTitle }
},
"Movie.Jsonl")
End If
Next div
End Sub
End ClassÀ quoi sert la propriété Working Directory?
Qu'y a-t-il de nouveau dans ce code?
La propriété Working Directory définit le répertoire de travail principal pour toutes les données aspirées et les fichiers connexes. Cela permet de s'assurer que tous les fichiers de sortie sont organisés dans un seul emplacement, ce qui facilite la gestion des projets de scraping à grande échelle. Le répertoire sera créé automatiquement s'il n'existe pas.
Quand utiliser les sélecteurs CSS plutôt que les attributs?
Considérations supplémentaires:
Les sélecteurs CSS sont idéaux pour cibler les éléments en fonction de leur position structurelle ou de leur nom de classe, tandis que l'accès direct aux attributs est préférable pour extraire des valeurs spécifiques telles que les identifiants ou les attributs de données personnalisés. Dans notre exemple, nous utilisons les sélecteurs CSS (#movie-featured > div) pour naviguer dans la structure DOM et les attributs (data-movie-id) pour extraire des valeurs spécifiques.
Comment créer des objets typés pour les données récupérées?
Construire des objets typés pour contenir des données scrappées dans des objets formatés. L'utilisation d'objets fortement typés permet une meilleure organisation du code, une prise en charge IntelliSense et une vérification des types au moment de la compilation.
Implémentez une classe Movie qui contiendra les données formatées :
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
}Public Class Movie
Public Property Id As Integer
Public Property Title As String
Public Property URL As String
End ClassComment l'utilisation d'objets typés améliore-t-elle l'organisation des données ?
Mettez à jour le code pour utiliser la classe typée Movie au lieu du dictionnaire générique ScrapedData :
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://website.com/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Scrape and store movie object
Scrape(movie, "Movie.Jsonl");
}
}
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://website.com/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Scrape and store movie object
Scrape(movie, "Movie.Jsonl")
End If
Next div
End Sub
End ClassQuel format la méthode Scrape utilise-t-elle pour les objets typés ?
Quoi de neuf ?
- Nous avons implémenté une classe
Moviepour contenir les données aspirées, fournissant une sécurité de type et une meilleure organisation du code. - Nous passons les objets film à la méthode
Scrapequi comprend notre format et l'enregistre de manière définie comme montré ci-dessous :

Le résultat est automatiquement sérialisé au format JSON, ce qui facilite son importation dans des bases de données ou d'autres applications.
Comment récupérer les pages détaillées d'un film?
Commencez à récupérer des pages plus détaillées. Le scraping de plusieurs pages est un besoin courant, et IronWebScraper le rend simple grâce à son mécanisme de chaînage des requêtes.
Quelles données supplémentaires puis-je extraire des pages détaillées ?
La page des films se présente comme suit, contenant de nombreuses métadonnées sur chaque film :

<div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div><div class="mvi-content">
<div class="thumb mvic-thumb"
style="background-image: url(https://img.gocdn.online/2017/04/28/poster/5a08e94ba02118f22dc30f298c603210-guardians-of-the-galaxy-vol-2.jpg);"></div>
<div class="mvic-desc">
<h3>Guardians of the Galaxy Vol. 2</h3>
<div class="desc">
Set to the backdrop of Awesome Mixtape #2, Marvel's Guardians of the Galaxy Vol. 2 continues the team's adventures as they travel throughout the cosmos to help Peter Quill learn more about his true parentage.
</div>
<div class="mvic-info">
<div class="mvici-left">
<p>
<strong>Genre: </strong>
<a href="https://Domain/genre/action/" title="Action">Action</a>,
<a href="https://Domain/genre/adventure/" title="Adventure">Adventure</a>,
<a href="https://Domain/genre/sci-fi/" title="Sci-Fi">Sci-Fi</a>
</p>
<p>
<strong>Actor: </strong>
<a target="_blank" href="https://Domain/actor/chris-pratt" title="Chris Pratt">Chris Pratt</a>,
<a target="_blank" href="https://Domain/actor/-zoe-saldana" title="Zoe Saldana">Zoe Saldana</a>,
<a target="_blank" href="https://Domain/actor/-dave-bautista-" title="Dave Bautista">Dave Bautista</a>
</p>
<p>
<strong>Director: </strong>
<a href="#" title="James Gunn">James Gunn</a>
</p>
<p>
<strong>Country: </strong>
<a href="https://Domain/country/us" title="United States">United States</a>
</p>
</div>
<div class="mvici-right">
<p><strong>Duration:</strong> 136 min</p>
<p><strong>Quality:</strong> <span class="quality">CAM</span></p>
<p><strong>Release:</strong> 2017</p>
<p><strong>IMDb:</strong> 8.3</p>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>
<div class="clearfix"></div>
</div>Comment étendre ma classe de film pour obtenir des propriétés supplémentaires?
Étendez la classe Movie avec de nouvelles propriétés (Description, Genre, Actor, Director, Country, Duration, IMDb Score) mais utilisez uniquement Description, Genre, et Actor pour cet exemple. Utiliser List<string> pour les genres et les acteurs permet de gérer plusieurs valeurs élégamment :
using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}using System.Collections.Generic;
public class Movie
{
public int Id { get; set; }
public string Title { get; set; }
public string URL { get; set; }
public string Description { get; set; }
public List<string> Genre { get; set; }
public List<string> Actor { get; set; }
}Imports System.Collections.Generic
Public Class Movie
Public Property Id() As Integer
Public Property Title() As String
Public Property URL() As String
Public Property Description() As String
Public Property Genre() As List(Of String)
Public Property Actor() As List(Of String)
End ClassComment naviguer entre les pages lors du scraping?
Naviguez jusqu'à la page détaillée pour l'extraire. IronWebScraper gère automatiquement la sécurité des threads, permettant à plusieurs pages d'être traitées simultanément.
Pourquoi utiliser plusieurs fonctions d'analyse pour différents types de pages ?
IronWebScraper permet d'ajouter plusieurs fonctions de scrape pour gérer différents formats de pages. Cette séparation des préoccupations rend votre code plus facile à maintenir et permet une gestion appropriée des différentes structures de page. Chaque fonction d'analyse peut se concentrer sur l'extraction de données à partir d'un type de page spécifique.
Comment les méta-données aident-elles à passer des objets entre les fonctions d'analyse ?
La fonctionnalité MetaData est cruciale pour maintenir l'état entre les requêtes. Pour plus de fonctionnalités avancées de webscraping, consultez notre guide détaillé :
public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}public class MovieScraper : WebScraper
{
public override void Init()
{
// Initialize scraper settings
License.LicenseKey = "LicenseKey";
this.LoggingLevel = WebScraper.LogLevel.All;
this.WorkingDirectory = AppSetting.GetAppRoot() + @"\MovieSample\Output\";
// Request homepage content for scraping
this.Request("https://domain/", Parse);
}
public override void Parse(Response response)
{
// Iterate over each movie div within the featured movie section
foreach (var div in response.Css("#movie-featured > div"))
{
if (div.Attributes["class"] != "clearfix")
{
var movie = new Movie
{
Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))
};
var link = div.Css("a")[0];
movie.Title = link.TextContentClean;
movie.URL = link.Attributes["href"];
// Request detailed page
this.Request(movie.URL, ParseDetails, new MetaData() { { "movie", movie } });
}
}
}
public void ParseDetails(Response response)
{
// Retrieve movie object from metadata
var movie = response.MetaData.Get<Movie>("movie");
var div = response.Css("div.mvic-desc")[0];
// Extract description
movie.Description = div.Css("div.desc")[0].TextContentClean;
// Extract genres
movie.Genre = new List<string>(); // Initialize genre list
foreach(var genre in div.Css("div > p > a"))
{
movie.Genre.Add(genre.TextContentClean);
}
// Extract actors
movie.Actor = new List<string>(); // Initialize actor list
foreach (var actor in div.Css("div > p:nth-child(2) > a"))
{
movie.Actor.Add(actor.TextContentClean);
}
// Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl");
}
}Public Class MovieScraper
Inherits WebScraper
Public Overrides Sub Init()
' Initialize scraper settings
License.LicenseKey = "LicenseKey"
Me.LoggingLevel = WebScraper.LogLevel.All
Me.WorkingDirectory = AppSetting.GetAppRoot() & "\MovieSample\Output\"
' Request homepage content for scraping
Me.Request("https://domain/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
' Iterate over each movie div within the featured movie section
For Each div In response.Css("#movie-featured > div")
If div.Attributes("class") <> "clearfix" Then
Dim movie As New Movie With {.Id = Convert.ToInt32(div.GetAttribute("data-movie-id"))}
Dim link = div.Css("a")(0)
movie.Title = link.TextContentClean
movie.URL = link.Attributes("href")
' Request detailed page
Me.Request(movie.URL, AddressOf ParseDetails, New MetaData() From {
{ "movie", movie }
})
End If
Next div
End Sub
Public Sub ParseDetails(ByVal response As Response)
' Retrieve movie object from metadata
Dim movie = response.MetaData.Get(Of Movie)("movie")
Dim div = response.Css("div.mvic-desc")(0)
' Extract description
movie.Description = div.Css("div.desc")(0).TextContentClean
' Extract genres
movie.Genre = New List(Of String)() ' Initialize genre list
For Each genre In div.Css("div > p > a")
movie.Genre.Add(genre.TextContentClean)
Next genre
' Extract actors
movie.Actor = New List(Of String)() ' Initialize actor list
For Each actor In div.Css("div > p:nth-child(2) > a")
movie.Actor.Add(actor.TextContentClean)
Next actor
' Scrape and store detailed movie data
Scrape(movie, "Movie.Jsonl")
End Sub
End ClassQuelles sont les principales caractéristiques de cette approche de scraping multi-pages ?
Quoi de neuf ?
- Ajoutez des fonctions d'aspiration (par exemple,
ParseDetails) pour aspirer les pages détaillées, similaires aux techniques utilisées lors de l'aspiration d'un site d'achat. - Déplacez la fonction
Scrapequi génère des fichiers vers la nouvelle fonction, en veillant à ce que les données soient enregistrées seulement après que tous les détails soient recueillis. - Utilisez la fonctionnalité IronWebScraper (
MetaData) pour transmettre des objets film à de nouvelles fonctions d'aspiration, en maintenant l'état des objets entre les requêtes. - Scraper les pages et enregistrer les données des objets vidéo dans des fichiers contenant des informations complètes.

Pour plus d'informations sur les méthodes et propriétés disponibles, consultez la Référence API. IronWebScraper fournit un cadre robuste pour l'extraction de données structurées à partir de sites web, ce qui en fait un outil essentiel pour les projets de collecte et d'analyse de données.
Questions Fréquemment Posées
Comment extraire des titres de films à partir de HTML à l'aide de C# ?
IronWebScraper fournit des méthodes de sélection CSS pour extraire les titres de films du code HTML. Utilisez la méthode response.Css() avec des sélecteurs appropriés tels que '.movie-item h2' pour cibler les éléments de titre, puis accédez à la propriété TextContentClean pour obtenir la valeur du texte propre.
Quelle est la meilleure façon de naviguer entre plusieurs pages de films ?
IronWebScraper gère la navigation dans les pages par le biais de la méthode Request(). Vous pouvez extraire les liens de pagination à l'aide de sélecteurs CSS, puis appeler Request() avec chaque URL pour extraire des données de plusieurs pages et constituer automatiquement des ensembles complets de données sur les films.
Comment puis-je enregistrer les données de films récupérées dans un format structuré ?
Utilisez la méthode Scrape() d'IronWebscraper pour enregistrer des données au format JSON. Créez des objets anonymes ou des classes typées contenant des propriétés de films telles que le titre, l'URL et l'évaluation, puis passez-les à Scrape() avec un nom de fichier pour sérialiser et enregistrer automatiquement les données.
Quels sélecteurs CSS dois-je utiliser pour extraire des informations sur les films ?
IronWebscraper prend en charge les sélecteurs CSS standard. Pour les sites web de films, utilisez des sélecteurs tels que '.movie-item' pour les conteneurs, 'h2' pour les titres, 'a[href]' pour les liens, et des noms de classe spécifiques pour les classements ou les genres. La méthode Css() renvoie des collections que vous pouvez parcourir.
Comment gérer les indicateurs de qualité des films tels que "CAM" dans les données récupérées ?
IronWebscraper vous permet d'extraire et de traiter des indicateurs de qualité en ciblant leurs éléments HTML spécifiques. Utilisez des sélecteurs CSS pour localiser les badges de qualité ou le texte, puis incluez-les en tant que propriétés dans vos objets de données récupérées pour obtenir des informations complètes sur les films.
Puis-je mettre en place un système de journalisation pour mes opérations de "movie scraping" ?
Oui, IronWebscraper comprend une fonctionnalité de journalisation intégrée. Définissez la propriété LoggingLevel à LogLevel.All dans votre méthode Init() pour suivre toutes les activités de scraping, les erreurs et les progrès, ce qui permet de déboguer et de surveiller l'extraction des données de votre film.
Quelle est la bonne façon de configurer les répertoires de travail pour les données récupérées ?
IronWebscraper vous permet de définir une propriété WorkingDirectory dans la méthode Init(). Spécifiez un chemin d'accès tel que "C#MovieData\Output\" où les fichiers de données de films scrappés seront sauvegardés. Cela permet de centraliser la gestion de la sortie et d'organiser les données.
Comment hériter correctement de la classe WebScraper ?
Créez une nouvelle classe qui hérite de la classe de base WebScraper d'IronWebscraper. Surchargez la méthode Init() pour la configuration et la méthode Parse() pour la logique d'extraction des données. Cette approche orientée objet rend votre racleur de films réutilisable et facile à maintenir.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ? PM > Install-Package IronWebScraper
exécuter un échantillon regarder votre site cible devenir des données structurées.










