



Probar en un entorno en vivo
Probar en producción sin marcas de agua.
Funciona donde lo necesites.

using IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR admite 125 idiomas internacionales. Además del inglés, que se instala por defecto, los paquetes de idiomas adicionales se pueden agregar a su proyecto .NET a través de NuGet o descargarlos de nuestra Página de Idiomas. En España, el soporte multilingüe es especialmente relevante: la LOPDGDD exige que el tratamiento de datos personales sea preciso y trazable con independencia del idioma del documento, por lo que un OCR con cobertura de los cuatro idiomas cooficiales del país es un requisito de cumplimiento, no una opción. La mayoría de los idiomas están disponibles en España es un país con cuatro lenguas cooficiales: castellano, catalán, euskera (vasco) y gallego. Esta pluralidad lingüística no es únicamente cultural; tiene implicaciones regulatorias directas que los sistemas de OCR deben contemplar. LOPDGDD y precisión multilingüe. La Ley Orgánica de Protección de Datos y Garantía de los Derechos Digitales (LOPDGDD), que transpone el RGPD al ordenamiento jurídico español, exige que los datos personales extraídos de documentos sean exactos y estén actualizados. Cuando un documento contiene nombres propios, direcciones o referencias fiscales en catalán, euskera o gallego, un motor OCR que no maneje correctamente estos idiomas puede generar errores que constituyan una infracción del principio de exactitud. La AEPD (Agencia Española de Protección de Datos) ha sancionado a organizaciones por inexactitudes en el tratamiento automatizado de datos personales. TicketBAI y el euskera en Bizkaia. El sistema TicketBAI, implantado en los territorios históricos de Bizkaia, Gipuzkoa y Araba, obliga a los contribuyentes a emitir y conservar tiques de venta con firma electrónica. Muchos de estos documentos incluyen campos en euskera, como eIDAS y documentos multilingües. Los certificados digitales emitidos por la FNMT (Fábrica Nacional de Moneda y Timbre) en el marco del reglamento eIDAS pueden acompañar documentos redactados en cualquiera de las lenguas cooficiales. La extracción de metadatos de firma mediante OCR requiere que el motor reconozca correctamente el texto independientemente del idioma del documento firmado. Ventaja competitiva en el sector público. Las administraciones autonómicas —Generalitat de Catalunya, Eusko Jaurlaritza, Xunta de Galicia— generan volúmenes masivos de documentación en sus respectivas lenguas. Las empresas que ofrezcan soluciones de digitalización con OCR preciso en todos los idiomas cooficiales tendrán una ventaja clara en licitaciones públicas relacionadas con digitalización documental y gestión de expedientes electrónicos. Escenario: Una asesoría fiscal de Bilbao necesita digitalizar e indexar automáticamente tiques TicketBAI emitidos por sus clientes del País Vasco. Los tiques están redactados en euskera e incluyen el La configuración recomendada con IronOCR es la siguiente: Con el paquete La compatibilidad multilingüe de IronOCR con los 125 idiomas disponibles, incluyendo los cuatro idiomas cooficiales de España, convierte a esta biblioteca en una solución idónea para proyectos de digitalización en el mercado español. El cumplimiento de la LOPDGDD, la integración con flujos TicketBAI supervisados por la AEPD, y la compatibilidad con documentos firmados bajo eIDAS con certificados FNMT son casos de uso reales que IronOCR resuelve con una configuración mínima. Si su organización opera en entornos regulados en España, IronOCR proporciona la precisión multilingüe necesaria para garantizar la conformidad normativa en cada extracción de texto.Compatibilidad con idiomas de IronOCR
Fast, Standard (recomendado), y Best calidad. La opción de calidad Best puede ofrecer resultados más precisos, pero también será más lenta en tiempo de procesamiento.Aplicaciones regulatorias en España
Faktura-zenbakia (número de factura) o BEZ-oinarria (base imponible del IVA). Los sistemas de archivo y auditoría que emplean OCR para indexar estos tiques deben reconocer correctamente el texto en euskera para cumplir con las obligaciones de conservación ante la Hacienda Foral correspondiente.Ejemplo práctico
Número de identificación fiscal (NIF/CIF) del emisor y el BEZ-oinarria (base imponible). El sistema debe extraer estos campos con precisión para alimentar el software de contabilidad y generar el rastro de auditoría exigido por la Hacienda Foral de Bizkaia.using IronOcr;
// Instalar: IronOcr + IronOcr.Languages.Basque vía NuGet
var ocr = new IronTesseract();
ocr.Language = OcrLanguage.BasqueBest; // Euskera, calidad máxima
using var input = new OcrInput();
input.LoadImage("ticketbai_bizkaia_2024_001.tiff");
OcrResult result = ocr.Read(input);
// Extraer campos clave del tique TicketBAI
Console.WriteLine("Texto extraído del tique TicketBAI:");
Console.WriteLine(result.Text);
// Salida esperada incluye: NIF/CIF, Faktura-zenbakia, BEZ-oinarria, IVA tipo aplicable
using IronOcr;
// Instalar: IronOcr + IronOcr.Languages.Basque vía NuGet
var ocr = new IronTesseract();
ocr.Language = OcrLanguage.BasqueBest; // Euskera, calidad máxima
using var input = new OcrInput();
input.LoadImage("ticketbai_bizkaia_2024_001.tiff");
OcrResult result = ocr.Read(input);
// Extraer campos clave del tique TicketBAI
Console.WriteLine("Texto extraído del tique TicketBAI:");
Console.WriteLine(result.Text);
// Salida esperada incluye: NIF/CIF, Faktura-zenbakia, BEZ-oinarria, IVA tipo aplicableImports IronOcr
' Instalar: IronOcr + IronOcr.Languages.Basque vía NuGet
Dim ocr As New IronTesseract()
ocr.Language = OcrLanguage.BasqueBest ' Euskera, calidad máxima
Using input As New OcrInput()
input.LoadImage("ticketbai_bizkaia_2024_001.tiff")
Dim result As OcrResult = ocr.Read(input)
' Extraer campos clave del tique TicketBAI
Console.WriteLine("Texto extraído del tique TicketBAI:")
Console.WriteLine(result.Text)
' Salida esperada incluye: NIF/CIF, Faktura-zenbakia, BEZ-oinarria, IVA tipo aplicable
End Using
$vbLabelText
$csharpLabel
IronOcr.Languages.Basque en modo Best, IronOCR reconoce con precisión los caracteres específicos del euskera (como tx, tz o ñ en contextos mixtos), garantizando que los datos extraídos sean fiables para el cumplimiento ante la AEPD y la Hacienda Foral.Conclusión
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR devuelve un objeto de resultado avanzado para cada página que escanea utilizando Tesseract 5. Esto contiene datos de ubicación, imágenes, texto, confianza estadística, alternativas de símbolos, nombres de fuentes, tamaños de fuentes, decoración, pesos de fuentes y posición para cada:
PageParagraphWordBarcode
Ya sean consultas sobre productos, integración o licencias, el equipo de desarrollo de productos Iron está disponible para apoyar todas tus preguntas. Ponerse en contacto y comenzar un diálogo con Iron para aprovechar al máximo nuestra biblioteca en tu proyecto.
Hacer una pregunta
Ya sea páginas de pasaportes, facturas, extractos bancarios, correo, tarjetas de visita o recibos; El reconocimiento óptico de caracteres (OCR) es un área de investigación basada en el reconocimiento de patrones, visión por computadora y aprendizaje automático. Las empresas utilizan OCR de manera transversal para extraer texto en sistemas de contabilidad y finanzas, digitalización empresarial, gestión de contenido empresarial y sistemas de informes de datos.
Además de construir otras historias de éxito. IronOCR agrega valor a Google Tesseract y a los servicios cognitivos de Microsoft 2021 Azure con IronOCR, una biblioteca OCR nativa de C#.
Si está buscando convertir imágenes del mundo real con un 99 por ciento de precisión, siga leyendo para ver cómo IronOCR le permite construir una aplicación de reconocimiento óptico de caracteres eficiente, precisa, escalable y casi humana.
El reconocimiento óptico de caracteres (OCR) se considera un fenómeno resuelto debido a la inmensa confianza que diferentes APIs afirman hacia la protección. Sin embargo, los diversos productos a menudo son rígidos e inexactos, fallando en aplicaciones del mundo real. Del mismo modo, Tesseract OCR funciona con texto impreso por máquina, de alta resolución y perfecto.
Suena bien?
Solo que el mundo real no siempre tiene texto impreso y escrito a mano perfectamente con alta resolución. En su lugar, el texto girado, desalineado, baja DPI, ruido de fondo y todas las desventajas de las imperfecciones digitales son atendidas por IronOCR, incluyendo la extracción de texto escrito a mano de archivos de imágenes. Garantizamos un documento 99.8 - 100 por ciento preciso y buscable con soporte multiplataforma que incluye Windows, Linux, macOS, Microsoft Azure, AWS y Docker; hay una razón por la cual los desarrolladores de C# eligen IronOCR sobre Tesseract OCR (básico): se trata de agregar valor.
¡Prepárese con lo mejor!
Además de lo anterior, IronOCR le equipa para procesar documentos de imágenes rápidamente. Si eso no es todo, las características de la API de IronOCR también incluyen lo siguiente:
Pase de la instalación .dll nativa o ejecutables a una única fuente de verdad: desarrolle utilizando una sola biblioteca de componentes nativa de .NET utilizando simples APIs de C# que soportan:
El arte de la API de IronOCR no termina ahí. Puede seguir explorando nuestra ventaja técnica más. Reducimos las complejidades del negocio, paso a paso, desarrollando soluciones confiables para optimizar aplicaciones de procesamiento de documentos y maximizando los ingresos comerciales al ofrecer características líderes en la industria:
Nuestro proceso de reconocimiento óptico de caracteres comienza con el preprocesamiento automático de imágenes para mejorar el archivo de imagen que mejora la tasa de respuesta de extracción. IronOCR agrega valor a su trabajo al permitir a los usuarios extraer el archivo de imagen base de ejemplo en la versión óptima de sí mismo. IronOCR cubre todas las bases:
Como el servicio IronOCR funciona de forma óptima en archivos de imagen de 300DPI (puntos por pulgada), cualquier imagen que esté significativamente fuera del rango de 200-300 DPI se re-muestrea para ajustarse dentro del rango objetivo.
Esto se traduce en una reducción de muestreo de imágenes de 600 DPI a 300 DPI o un aumento de muestreo de imágenes de 100 DPI a 200 DPI con un 99 por ciento de confianza.
Como los servicios cognitivos de IronOCR están diseñados para funcionar en imágenes monocromáticas, cualquier imagen en color o en escala de grises se convierte a monocromática, utilizando un algoritmo de binarización adaptativa.
El algoritmo compara las densidades de píxeles dentro de un área para determinar el umbral a utilizar para convertir píxeles a monocromáticos.
IronOCR busca líneas de texto y patrones de caracteres para alinear automáticamente y rotar los recursos de imagen de entrada a la orientación deseada.
Con IronOCR, los archivos de imagen se analizan automáticamente para detectar la presencia y cantidad de ruido. El ruido son básicamente las 'motas' que se encuentran en las imágenes escaneadas. Nuestro algoritmo adaptativo luego elimina el ruido basado en el tamaño de las partículas de ruido.
Tan pronto como el archivo de imagen de muestra se preprocesa, IronOCR divide el archivo de imagen de entrada en diferentes zonas de procesamiento.
Otra etapa de pre-preparación implica dividir la imagen de referencia en diferentes zonas lógicas. IronOCR inicialmente localiza texto e imágenes dentro de la imagen con la ayuda del espacio en blanco y patrones; la región del texto se separa de las imágenes.
Luego se particiona en zonas: párrafos, columnas y bloques de texto. Las imágenes y los píxeles restantes no textuales se identifican para ser omitidos durante el reconocimiento de texto e incluidos en la salida inteligente. IronOCR luego marca las zonas de texto como tablas con la ayuda de líneas de cuadrícula y bloques de texto.
Realice múltiples pasos interconectados que convierten parches de píxeles en hilos de texto de una línea que los usuarios pueden buscar. Esto incluye segmentación de caracteres, clasificación adaptativa, referencias de diccionario y otros procesos relacionados que contribuyen al texto extraído óptimo.
Con el servicio API de IronOCR, hemos probado nuestra herramienta a través de múltiples ejemplos de archivos de datos en varios idiomas que incluyen niveles de palabras, precisión de símbolos y retención de diseño en formatos de Microsoft Office. Aunque algunos parámetros se prueban automáticamente; otros incluyen verificaciones visuales.
IronOCR le permite agregar capacidades OCR multiplataforma con múltiples formatos de entrada a una cadena de texto plano que puede buscar. Para aumentar su productividad con IronOCR, comience con nuestra documentación gratuita de tutorial que le guiará a través del uso de IronOCR. Descargue nuestro instalador de paquetes NuGet hoy, y explore con una clave de prueba gratuita o conéctese con soporte personal 24/7. Escale sus necesidades con nuestra licencia de por vida, sin importar el tamaño de su equipo.
Ver LicenciasLicencias de desarrollo comunitario gratuitas. Licencias comerciales desde $749.





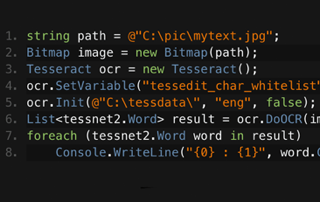
C# Tesseract OCR

Jim ha sido una figura líder en el desarrollo de IronOCR. Jim diseña y construye algoritmos de procesamiento de imágenes y métodos de lectura para OCR.
Ver comparación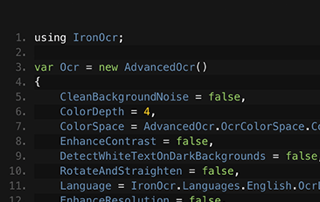
C# OCR ASP.NET

Aprenda cómo el equipo de Gemma usa IronOCR para leer texto de imágenes para su software de archivo. Gemma comparte sus propios ejemplos de código.
Imagen a texto tutorial de .NET




El equipo de Iron tiene más de 10 años de experiencia en el mercado de componentes de software .NET.








Install-Package IronOcr

No se requiere tarjeta de crédito
Su clave de prueba debería estar en el correo electrónico.![]() El formulario de prueba fue enviado
El formulario de prueba fue enviado
con éxito.
Si no es así, por favor contacte
support@ironsoftware.com
No se requiere tarjeta de crédito
Probar en producción sin marcas de agua.
Funciona donde lo necesites.
Obtén 30 días de producto completamente funcional.
Instálalo y ejecútalo en minutos.
Acceso completo a nuestro equipo de soporte técnico durante tu prueba del producto
Demostración en vivo de nuestro producto y características clave
Recomendaciones de características del proyecto
Se responde a todas sus preguntas para asegurarse de que dispone de toda la información que necesita. (Sin ningún tipo de compromiso)





Sin limitaciones. 100 % desbloqueado. Sin tarjeta de crédito.
Reserva una Consulta Sin Compromiso

Completa el formulario a continuación o envía un correo a sales@ironsoftware.com
Tus detalles siempre serán mantenidos confidenciales.

Reserve una demostración personal de 30 minutos.
Sin contrato, sin datos de tarjeta, sin compromisos.


