



In einer Live-Umgebung testen
Testen Sie ohne Wasserzeichen in der Produktion.
Funktioniert dort, wo Sie es brauchen.

using IronOcr;
using System;
var ocrTesseract = new IronTesseract();
ocrTesseract.Language = OcrLanguage.Arabic;
using (var ocrInput = new OcrInput())
{
ocrInput.LoadImage(@"images\arabic.gif");
var ocrResult = ocrTesseract.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}
// Example with a Custom Trained Font Being used:
var ocrTesseractCustomerLang = new IronTesseract();
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata");
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest);
using (var ocrInput = new OcrInput())
{
ocrInput.LoadPdf(@"images\mixed-lang.pdf");
var ocrResult = ocrTesseractCustomerLang.Read(ocrInput);
Console.WriteLine(ocrResult.Text);
}Imports IronOcr
Imports System
Private ocrTesseract = New IronTesseract()
ocrTesseract.Language = OcrLanguage.Arabic
Using ocrInput As New OcrInput()
ocrInput.LoadImage("images\arabic.gif")
Dim ocrResult = ocrTesseract.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End Using
' Example with a Custom Trained Font Being used:
Dim ocrTesseractCustomerLang = New IronTesseract()
ocrTesseractCustomerLang.UseCustomTesseractLanguageFile("custom_tesseract_files/custom.traineddata")
ocrTesseractCustomerLang.AddSecondaryLanguage(OcrLanguage.EnglishBest)
Using ocrInput As New OcrInput()
ocrInput.LoadPdf("images\mixed-lang.pdf")
Dim ocrResult = ocrTesseractCustomerLang.Read(ocrInput)
Console.WriteLine(ocrResult.Text)
End UsingInstall-Package IronOcr
IronOCR unterstützt 125 internationale Sprachen. Neben Englisch, das standardmäßig installiert ist, können zusätzliche Sprachpakete über NuGet zu Ihrem .NET-Projekt hinzugefügt oder von unserer Sprachenseite heruntergeladen werden. Die meisten Sprachen sind in Unterstützung von IronOCR-Sprachen
Fast, Standard (empfohlen) und Best Qualität verfügbar. Die Best Qualitätsoption kann genauere Ergebnisse bieten, ist jedoch in der Bearbeitungszeit langsamer.
using IronOcr;
using IronSoftware.Drawing;
// We can delve deep into OCR results as an object model of
// Pages, Barcodes, Paragraphs, Lines, Words and Characters
// This allows us to explore, export and draw OCR content using other APIs/
var ocrTesseract = new IronTesseract();
ocrTesseract.Configuration.ReadBarCodes = true;
using var ocrInput = new OcrInput();
var pages = new int[] { 1, 2 };
ocrInput.LoadImageFrames("example.tiff", pages);
OcrResult ocrResult = ocrTesseract.Read(ocrInput);
foreach (var page in ocrResult.Pages)
{
// Page object
int PageNumber = page.PageNumber;
string PageText = page.Text;
int PageWordCount = page.WordCount;
// null if we dont set Ocr.Configuration.ReadBarCodes = true;
OcrResult.Barcode[] Barcodes = page.Barcodes;
AnyBitmap PageImage = page.ToBitmap(ocrInput);
double PageWidth = page.Width;
double PageHeight = page.Height;
double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew()
foreach (var paragraph in page.Paragraphs)
{
// Pages -> Paragraphs
int ParagraphNumber = paragraph.ParagraphNumber;
string ParagraphText = paragraph.Text;
AnyBitmap ParagraphImage = paragraph.ToBitmap(ocrInput);
int ParagraphX_location = paragraph.X;
int ParagraphY_location = paragraph.Y;
int ParagraphWidth = paragraph.Width;
int ParagraphHeight = paragraph.Height;
double ParagraphOcrAccuracy = paragraph.Confidence;
OcrResult.TextFlow paragrapthText_direction = paragraph.TextDirection;
foreach (var line in paragraph.Lines)
{
// Pages -> Paragraphs -> Lines
int LineNumber = line.LineNumber;
string LineText = line.Text;
AnyBitmap LineImage = line.ToBitmap(ocrInput);
int LineX_location = line.X;
int LineY_location = line.Y;
int LineWidth = line.Width;
int LineHeight = line.Height;
double LineOcrAccuracy = line.Confidence;
double LineSkew = line.BaselineAngle;
double LineOffset = line.BaselineOffset;
foreach (var word in line.Words)
{
// Pages -> Paragraphs -> Lines -> Words
int WordNumber = word.WordNumber;
string WordText = word.Text;
AnyBitmap WordImage = word.ToBitmap(ocrInput);
int WordX_location = word.X;
int WordY_location = word.Y;
int WordWidth = word.Width;
int WordHeight = word.Height;
double WordOcrAccuracy = word.Confidence;
foreach (var character in word.Characters)
{
// Pages -> Paragraphs -> Lines -> Words -> Characters
int CharacterNumber = character.CharacterNumber;
string CharacterText = character.Text;
AnyBitmap CharacterImage = character.ToBitmap(ocrInput);
int CharacterX_location = character.X;
int CharacterY_location = character.Y;
int CharacterWidth = character.Width;
int CharacterHeight = character.Height;
double CharacterOcrAccuracy = character.Confidence;
// Output alternative symbols choices and their probability.
// Very useful for spellchecking
OcrResult.Choice[] Choices = character.Choices;
}
}
}
}
}Imports IronOcr
Imports IronSoftware.Drawing
' We can delve deep into OCR results as an object model of
' Pages, Barcodes, Paragraphs, Lines, Words and Characters
' This allows us to explore, export and draw OCR content using other APIs/
Private ocrTesseract = New IronTesseract()
ocrTesseract.Configuration.ReadBarCodes = True
Dim ocrInput As New OcrInput()
Dim pages = New Integer() { 1, 2 }
ocrInput.LoadImageFrames("example.tiff", pages)
Dim ocrResult As OcrResult = ocrTesseract.Read(ocrInput)
For Each page In ocrResult.Pages
' Page object
Dim PageNumber As Integer = page.PageNumber
Dim PageText As String = page.Text
Dim PageWordCount As Integer = page.WordCount
' null if we dont set Ocr.Configuration.ReadBarCodes = true;
Dim Barcodes() As OcrResult.Barcode = page.Barcodes
Dim PageImage As AnyBitmap = page.ToBitmap(ocrInput)
Dim PageWidth As Double = page.Width
Dim PageHeight As Double = page.Height
Dim PageRotation As Double = page.Rotation ' angular correction in degrees from OcrInput.Deskew()
For Each paragraph In page.Paragraphs
' Pages -> Paragraphs
Dim ParagraphNumber As Integer = paragraph.ParagraphNumber
Dim ParagraphText As String = paragraph.Text
Dim ParagraphImage As AnyBitmap = paragraph.ToBitmap(ocrInput)
Dim ParagraphX_location As Integer = paragraph.X
Dim ParagraphY_location As Integer = paragraph.Y
Dim ParagraphWidth As Integer = paragraph.Width
Dim ParagraphHeight As Integer = paragraph.Height
Dim ParagraphOcrAccuracy As Double = paragraph.Confidence
Dim paragrapthText_direction As OcrResult.TextFlow = paragraph.TextDirection
For Each line In paragraph.Lines
' Pages -> Paragraphs -> Lines
Dim LineNumber As Integer = line.LineNumber
Dim LineText As String = line.Text
Dim LineImage As AnyBitmap = line.ToBitmap(ocrInput)
Dim LineX_location As Integer = line.X
Dim LineY_location As Integer = line.Y
Dim LineWidth As Integer = line.Width
Dim LineHeight As Integer = line.Height
Dim LineOcrAccuracy As Double = line.Confidence
Dim LineSkew As Double = line.BaselineAngle
Dim LineOffset As Double = line.BaselineOffset
For Each word In line.Words
' Pages -> Paragraphs -> Lines -> Words
Dim WordNumber As Integer = word.WordNumber
Dim WordText As String = word.Text
Dim WordImage As AnyBitmap = word.ToBitmap(ocrInput)
Dim WordX_location As Integer = word.X
Dim WordY_location As Integer = word.Y
Dim WordWidth As Integer = word.Width
Dim WordHeight As Integer = word.Height
Dim WordOcrAccuracy As Double = word.Confidence
For Each character In word.Characters
' Pages -> Paragraphs -> Lines -> Words -> Characters
Dim CharacterNumber As Integer = character.CharacterNumber
Dim CharacterText As String = character.Text
Dim CharacterImage As AnyBitmap = character.ToBitmap(ocrInput)
Dim CharacterX_location As Integer = character.X
Dim CharacterY_location As Integer = character.Y
Dim CharacterWidth As Integer = character.Width
Dim CharacterHeight As Integer = character.Height
Dim CharacterOcrAccuracy As Double = character.Confidence
' Output alternative symbols choices and their probability.
' Very useful for spellchecking
Dim Choices() As OcrResult.Choice = character.Choices
Next character
Next word
Next line
Next paragraph
Next pageInstall-Package IronOcr
IronOCR gibt für jede von ihm gescannte Seite ein fortschrittliches Ergebnisobjekt unter Verwendung von Tesseract 5 zurück. Dies enthält Standortdaten, Bilder, Text, statistisches Vertrauen, alternative Symbolauswahlen, Schriftartennamen, Schriftgrößen, Dekoration, Schriftstärken und Position für jedes:
PageParagraphWordBarcode
Egal, ob es sich um Produkt-, Integrations- oder Lizenzanfragen handelt, das Iron-Produktentwicklungsteam steht zur Verfügung, um all Ihre Fragen zu unterstützen. Nehmen Sie Kontakt auf und beginnen Sie einen Dialog mit Iron, um unsere Bibliothek in Ihrem Projekt optimal zu nutzen.
Frage stellen
Ob es sich um Passseiten, Rechnungen, Kontoauszüge, Post, Visitenkarten oder Quittungen handelt; die optische Zeichenerkennung (OCR) ist ein Forschungsfeld, das auf Mustererkennung, Computer Vision und maschinellem Lernen basiert. Unternehmen verwenden OCR über Abteilungen hinweg, um Text in Buchhaltungs- und Finanzsystemen, Geschäftsdigitalisierung, Unternehmensinhaltsmanagement und Datenberichterstattungssystemen zu extrahieren.
Zusätzlich zum Aufbau weiterer Erfolgsgeschichten. IronOCR fügt Google Tesseract und Microsoft 2021 Azure Cognitive Services mit IronOCR - einer nativen C# OCR-Bibliothek - Mehrwert hinzu.
Wenn Sie reale Bilder mit 99-prozentiger Genauigkeit konvertieren möchten - dann lesen Sie weiter, um zu sehen, wie IronOCR Ihnen ermöglicht, eine effiziente, genaue, skalierbare und nahezu menschliche optische Zeichenerkennungsanwendung zu erstellen.
Optische Zeichenerkennung (OCR) gilt als gelöstes Phänomen aufgrund der großen Zuversicht, die verschiedene APIs hinsichtlich des Schutzes beanspruchen. Die verschiedenen Produkte sind jedoch oft starr und ungenau und scheitern in realen Anwendungen. Ebenso arbeitet Tesseract OCR mit maschinengedrucktem, hochauflösendem, perfektem Text.
Klingt gut?
Nur die reale Welt hat nicht immer perfekt gedruckten und handgeschriebenen Text mit hoher Auflösung. Stattdessen werden von IronOCR gedrehte, verzerrte, niedrige DPI, Hintergrundrauschen und alle Flüche digitaler Unvollkommenheiten bearbeitet, einschließlich des Extrahierens von handgeschriebenem Text aus Bilddateien. Wir gewährleisten ein 99,8–100 prozentig genaues, durchsuchbares Dokument mit plattformübergreifender Unterstützung, die Windows, Linux, macOS, Microsoft Azure, AWS und Docker umfasst - es gibt einen Grund, warum C# Entwickler IronOCR dem (einfachen) Tesseract OCR vorziehen - es geht darum, Mehrwert zu schaffen.
Rüsten Sie sich mit dem Besten aus!
Zusätzlich zur oben genannten Ausstattung bietet IronOCR Ihnen die Möglichkeit, Bilddokumente prompt zu verarbeiten. Wenn das alles nicht ausreicht, umfassen die Funktionen der IronOCR-API außerdem Folgendes:
Vom nativen .dlls oder exes-Installationen zu einer einzigen Quelle der Wahrheit übergehen - entwickeln Sie mit einer einzigen, nativen .NET-Komponentenbibliothek unter Verwendung einer einfachen C# APIs die unterstützt:
Die Kunst der IronOCR-API endet hier nicht; Sie können unseren technischen Vorsprung weiter erkunden. Wir reduzieren die geschäftlichen Komplexitäten Schritt für Schritt, indem wir zuverlässige Lösungen entwickeln, um Dokumentenverarbeitungsanwendungen zu optimieren und Geschäftsgewinne zu maximieren, indem wir branchenspezifische Funktionen bieten, die eingebettet sind:
Unser optischer Zeichenerkennungsprozess beginnt mit der automatisierten Bildvorverarbeitung, um die Bilddatei zu verbessern, die die Extraktionsreaktionsrate verbessert. IronOCR fügt Ihrem Projekt Wert hinzu, da es den Benutzern ermöglicht, die Beispiel-Bilddatei in die optimale Version von sich selbst zu extrahieren. IronOCR deckt alle Bereiche ab:
Da der IronOCR-Dienst optimal auf 300DPI (Dots Per Inch) Bilddateien arbeitet, wird jedes Bild, das sich signifikant außerhalb von 200-300 DPI befindet, auf die angestrebte Reichweite umgesampelt.
Dies übersetzt das Abwärts-Sampling von 600 DPI Bildern auf 300 DPI oder das Aufwärts-Sampling von 100 DPI Bildern auf 200 DPI mit 99-prozentigem Vertrauen.
Da IronOCR- kognitive Dienste so konzipiert sind, dass sie auf monochromatischen Bildern funktionieren, werden alle farbigen oder Graustufenbilder in monochrom umgewandelt, wobei ein adaptiver Binarisierungsalgorithmus verwendet wird.
Der Algorithmus vergleicht die Pixeldichten in einem Bereich, der den Schwellenwert bestimmt, der verwendet wird, um Pixel monochrom zu konvertieren.
IronOCR sucht nach Textlinien und Zeichenmustern, um Eingabebildressourcen automatisch zu entzerren und zur gewünschten Ausrichtung zu drehen.
Mit IronOCR werden Bilddateien automatisch auf das Vorhandensein und die Menge von Rauschen analysiert. Rauschen sind im Wesentlichen die auf den gescannten Bildern gefundenen ‘Flecken’. Unser adaptiver Algorithmus entfernt das Rauschen basierend auf der Größe der Rauschpartikel.
Sobald die Beispiel-Bilddatei vorverarbeitet ist, bricht IronOCR die Eingabebilddatei in verschiedene Verarbeitungszonen auf.
Eine weitere Vorbereitungsstufe besteht darin, das Referenzbild in verschiedene logische Zonen aufzuteilen. IronOCR lokalisiert zuerst Text und Bilder innerhalb des Bildes mit Hilfe von Leerraum und Mustern; der Textbereich wird von Bildern getrennt.
Es wird dann in Zonen unterteilt – Absätze, Spalten und Textblöcke. Die Bilder und verbleibende Nicht-Text-Pixel werden identifiziert, um während der Texterkennung ausgelassen und in die intelligente Ausgabe einbezogen zu werden. IronOCR markiert dann die Textzonen als Tabellen mit Hilfe von Rasterlinien und Textblöcken.
Führen Sie mehrere miteinander verbundene Schritte aus, die Pixelansammlungen in Einzeil-Textfäden umwandeln, die Benutzer durchsuchen können. Dies umfasst die Zeichensegmentierung, adaptive Klassifizierung, Wörterbuchreferenzen und andere verwandte Prozesse, die zum optimalen extrahierten Text beitragen.
Mit dem IronOCR API-Dienst haben wir unser Tool durch mehrere Datenbeispiele in mehreren Sprachen getestet, die Wortstufen, Symbolgenauigkeit und Layout-Erhaltung in Microsoft Office-Formaten umfassen. Obwohl einige Parameter automatisch getestet werden; andere beinhalten visuelle Prüfungen.
IronOCR ermöglicht es Ihnen, plattformübergreifende OCR-Funktionen mit mehreren Eingabeformaten zu einer durchsuchbaren Nur-Text-Zeichenfolge hinzuzufügen. Um Ihre Produktivität mit IronOCR zu steigern, beginnen Sie mit unserer kostenlosen Tutorial-Dokumentation, die Sie durch die Nutzung von IronOCR führt. Laden Sie heute unseren NuGet-Paketen-Installer herunter und erkunden Sie mit einem kostenlosen Testschlüssel oder verbinden Sie sich mit unserem 24/7 persönlichen Support. Passen Sie Ihre Bedürfnisse mit unserer lebenslangen Lizenzierung an, unabhängig von Ihrer Teamgröße.
Lizenzen anzeigenKostenlos Community-Entwicklungslizenzen. Kommerzielle Lizenzen ab $749.





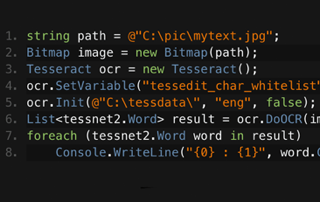
C# Tesseract OCR

Jim war eine führende Figur in der Entwicklung von IronOCR. Jim entwirft und baut Bildverarbeitungsalgorithmen und Leseverfahren für OCR.
21. Vergleich anzeigen
C# OCR ASP.NET

Erfahren Sie, wie Gemmas Team IronOCR verwendet, um Text aus Bildern für ihre Archivierungssoftware zu lesen. Gemma teilt ihre eigenen Codebeispiele.
Bild zu Text .NET Tutorial




Das Iron-Team hat über 10 Jahre Erfahrung im .NET-Softwaremarkt.








Install-Package IronOcr

Keine Kreditkarte erforderlich
Ihr Testschlüssel sollte in der E-Mail sein.![]() Das Testformular wurde
Das Testformular wurde
erfolgreich eingereicht.
Wenn nicht, kontaktieren Sie bitte
support@ironsoftware.com
Keine Kreditkarte erforderlich
Testen Sie ohne Wasserzeichen in der Produktion.
Funktioniert dort, wo Sie es brauchen.
Erhalten Sie 30 Tage voll funktionsfähiges Produkt.
In wenigen Minuten einsatzbereit.
Voller Zugriff auf unser Support-Engineering-Team während Ihrer Produktprobe
Eine Live-Demo unseres Produkts und seiner Hauptmerkmale
Erhalten Sie projektspezifische Funktionsempfehlungen
Alle Ihre Fragen werden beantwortet, um sicherzustellen, dass Sie alle Informationen erhalten, die Sie benötigen. (Völlig unverbindlich.)





Buchen Sie eine unverbindliche Beratung

Füllen Sie das Formular unten aus oder senden Sie eine E-Mail an sales@ironsoftware.com
Ihre Daten werden immer vertraulich behandelt.

Windows (10, 11, Server 2012 - 2022)
Keine Verträge, keine Kartenangaben, keine Verpflichtungen.


