

Testez dans un environnement en direct
Testez en production sans filigranes.
Fonctionne où que vous en ayez besoin.

30DAYFREE
using IronWebScraper;
public class Program
{
private static void Main(string[] args)
{
var ScrapeJob = new BlogScraper();
ScrapeJob.Start();
}
}
public class BlogScraper : WebScraper
{
public override void Init()
{
LoggingLevel = LogLevel.All;
Request("https://www.zyte.com/blog/", Parse);
}
public override void Parse(Response response)
{
foreach (HtmlNode title_link in response.Css(".oxy-post-title"))
{
string strTitle = title_link.TextContentClean;
Scrape(new ScrapedData() { { "Title", strTitle } });
}
if (response.CssExists("div.oxy-easy-posts-pages > a[href]"))
{
string next_page = response.Css("div.oxy-easy-posts-pages > a[href]")[0].Attributes["href"];
Request(next_page, Parse);
}
}
}Install-Package IronWebScraper
Conçu pour C#, F# et VB.NET fonctionnant sur .NET 10, 9, 8, 7, 6, 5, Core, Standard, ou Framework

")
")
")
")
")
")
")
")
")
")
")
")
")
")
Explorer des milliers de pages à partir d'une seule classe C#. Sélecteurs CSS, XPath, rendu JavaScript, identités virtuelles et contrôles de courtoisie dans une seule bibliothèque.

Request(url, Parse), response.Css(".selector"), Scrape(data).using IronWebScraper;
public class Program
{
private static void Main(string[] args)
{
var ScrapeJob = new BlogScraper();
ScrapeJob.Start();
}
}
public class BlogScraper : WebScraper
{
public override void Init()
{
LoggingLevel = LogLevel.All;
Request("https://www.zyte.com/blog/", Parse);
}
public override void Parse(Response response)
{
foreach (HtmlNode title_link in response.Css(".oxy-post-title"))
{
string strTitle = title_link.TextContentClean;
Scrape(new ScrapedData() { { "Title", strTitle } });
}
if (response.CssExists("div.oxy-easy-posts-pages > a[href]"))
{
string next_page = response.Css("div.oxy-easy-posts-pages > a[href]")[0].Attributes["href"];
Request(next_page, Parse);
}
}
}Imports IronWebScraper
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim ScrapeJob = New BlogScraper()
ScrapeJob.Start()
End Sub
End Class
Public Class BlogScraper
Inherits WebScraper
Public Overrides Sub Init()
LoggingLevel = LogLevel.All
Request("https://www.zyte.com/blog/", AddressOf Parse)
End Sub
Public Overrides Sub Parse(ByVal response As Response)
For Each title_link As HtmlNode In response.Css(".oxy-post-title")
Dim strTitle As String = title_link.TextContentClean
Scrape(New ScrapedData() From {
{ "Title", strTitle }
})
Next title_link
If response.CssExists("div.oxy-easy-posts-pages > a[href]") Then
Dim next_page As String = response.Css("div.oxy-easy-posts-pages > a[href]")(0).Attributes("href")
Request(next_page, AddressOf Parse)
End If
End Sub
End ClassInstall-Package IronWebScraper
IronWebScraper fournit un framework puissant pour extraire des données et des fichiers de sites web à l'aide de code C#.
WebScraper.Init qui utilise la méthode Request pour analyser au moins une URL.Parse pour traiter les requêtes, et effectivement Request plus de pages. Utilisez response.Css pour travailler avec des éléments HTML en utilisant des sélecteurs CSS de style jQuery.Start();.Découvrez comment extraire des données de sites web de films en ligne avec C#

Que ce soit pour des questions sur le produit, l'intégration ou les licences, l'équipe de développement de produits Iron est à disposition pour répondre à toutes vos questions. Prenez contact et démarrez un dialogue avec Iron pour tirer le meilleur parti de notre bibliothèque dans votre projet.
Poser une question
Il suffit d'écrire une seule classe de scraper Web C# pour extraire des milliers, voire des millions de pages Web en instances de classe C#, JSON ou fichiers téléchargés. IronWebScraper vous permet de coder des flux de travail concis et linéaires simulant le comportement de navigation humaine. IronWebScraper exécutera votre code comme un essaim de navigateurs Web virtuels, massivement parallélisés, mais poli et tolérant aux fautes.
Commencer avec la documentation
IronWebScraper doit être programmé pour savoir comment gérer chaque “type” de page qu'il rencontre. Ceci est réalisé de manière très concise en utilisant des sélecteurs CSS ou des expressions XPath et peut être entièrement personnalisé en C#. Cette liberté vous permet de décider quelles pages scraper dans un site Web, et quoi faire avec les données extraites. Chaque méthode peut être déboguée et suivie proprement dans Visual Studio.
Suivre un tutoriel
IronWebScraper gère le multithreading et les requêtes Web pour permettre des centaines de threads concurrents sans que le développeur ait à les gérer. La politesse peut être réglée pour moduler les requêtes, réduisant ainsi le risque de charge excessive sur les serveurs Web cibles.
Prêt à l'emploi avec WebScraper
IronWebScraper peut utiliser une ou plusieurs “identités” - sessions qui simulent des demandes humaines réelles. Chaque demande peut assigner son propre Identité, Agent utilisateur, Cookies, Connexions et même adresses IP de manière programmatique ou aléatoire. Les demandes sont définies comme auto-uniques avec une combinaison d'URL, de méthode d'analyse et de variables post.
See API Reference
IronWebScraper utilise la mise en cache avancée pour permettre aux développeurs de modifier leur code “à la volée” et de rejouer chaque demande précédente sans contacter Internet. Chaque travail de scraping est automatiquement sauvegardé et peut être repris en cas d'exception ou de panne de courant.
Instructions de configuration de WebScraper
IronWebScraper met les outils de scraping Web entre vos mains rapidement avec un installateur Visual Studio. Que ce soit en installant directement à partir de NuGet dans Visual Studio ou en téléchargeant la DLL, vous serez configuré en un rien de temps. Juste une DLL et sans dépendances.
PM > Install-Package IronWebScraper Télécharger DLL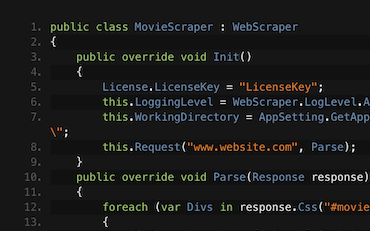
VB C# ASP.NET
Voyez comment Ahmed utilise IronWebScraper dans ses projets pour migrer du contenu d'un site à un autre. Des projets et du code échantillons sont fournis pour le scraping de sites de commerce électronique et de blogs
 Voir le tutoriel de scraping Web d'Ahmed
Voir le tutoriel de scraping Web d'Ahmed





L'équipe d'Iron a plus de 10 ans d'expérience dans le marché des composants logiciels .NET.

Vous voulez une preuve rapidement ? PM > Install-Package IronWebScraper
exécuter un échantillon regarder votre site cible devenir des données structurées.
Install-Package IronWebScraper

Pas de carte de crédit requise
Votre clé d'essai devrait être dans l'e-mail.![]() Le formulaire d'essai a été soumis
Le formulaire d'essai a été soumis
avec succès.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Pas de carte de crédit requise
Testez en production sans filigranes.
Fonctionne où que vous en ayez besoin.
Profitez de 30 jours de produit entièrement fonctionnel.
Configurez-le et faites-le fonctionner en quelques minutes.
Accès complet à notre équipe de support technique durant votre essai produit
Une démonstration en direct de notre produit et de ses fonctionnalités clés
Obtenez des recommandations de fonctionnalités spécifiques au projet
Nous répondons à toutes vos questions afin de nous assurer que vous disposez de toutes les informations dont vous avez besoin. (Sans aucun engagement)





Aucune restriction. 100 % débloqué. Pas de carte bancaire.
Réservez une Consultation sans Engagement

Remplissez le formulaire ci-dessous ou envoyez un email à sales@ironsoftware.com
Vos informations seront toujours gardées confidentielles.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagement.


